


























































Deep learning is a sub-field of machine learning and is related to algorithms. Machine learning is a kind of artificial intelligence that provides computers with the ability to learn, without explicitly programming them.
Deep learning is a new area of machine learning research, which has been introduced with the objective of moving machine learning closer to one of its original goals—artificial intelligence (AI). Deep learning is the sub-field of machine learning that is concerned with algorithms. Its structure and function is inspired by that part of the human brain called neural networks. It is the work of well-known researchers like Andrew Ng, Geoff Hinton, Yann LeCun, Yoshua Bengio and Andrej Karpathy which has brought deep learning into the spotlight. If you follow the latest tech news, you may have even heard about how important deep learning has become among big companies such as:
- Google buying DeepMind for US$ 400 million
- Apple and its self-driving car
- NVIDIA and its GPUs
- Toyota’s billion dollar AI research investments
All of this tells us that deep learning is really gaining in importance.
Neural networks
The first thing you need to know is that deep learning is about neural networks. The structure of a neural network is like any other kind of network; there is an interconnected Web of nodes, which are called neurons, and there are edges that join them together. A neural network’s main function is to receive a set of inputs, perform progressively complex calculations, and then use the output to solve a problem. This series of events, starting from the input, where each activation is sent to the next layer and then the next, all the way to the output, is known as forward propagation, or forward prop.
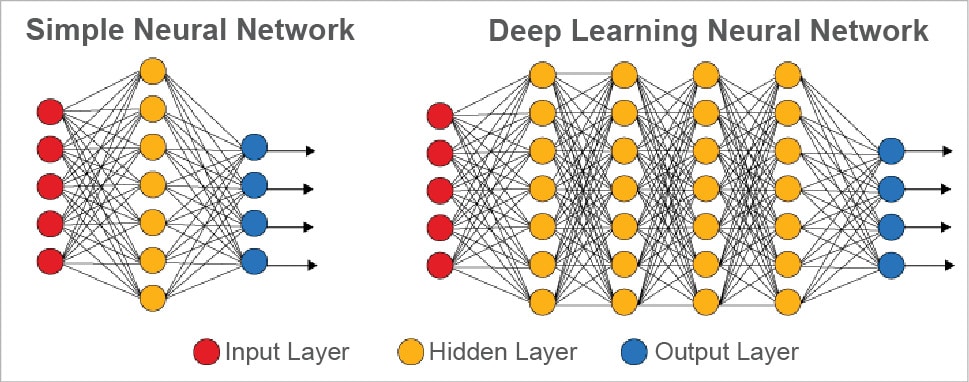
The first neural nets were born out of the need to address the inaccuracy of an early classifier, the perceptron. It was shown that by using a layered web of perceptrons, the accuracy of predictions could be improved. This new breed of neural nets was called a multi-layer perceptron or MLP.
You may have guessed that the prediction accuracy of a neural net depends on its weights and biases. We want the accuracy to be high, i.e., we want the neural net to predict a value that is as close to the actual output as possible, every single time. The process of improving a neural net’s accuracy is called training, just like with other machine learning methods. Here’s that forward prop again – to train the net, the output from forward prop is compared to the output that is known to be correct, and the cost is the difference of the two. The point of training is to make that cost as small as possible, across millions of training examples. Once trained well, a neural net has the potential to make accurate predictions each time. This is a neural net in a nutshell (refer to Figure 1).
Three reasons to consider deep learning
When the patterns get really complex, neural nets start to outperform all of their competition. Neural nets truly have the potential to revolutionise the field of artificial intelligence. We all know that computers are very good with repetitive calculations and detailed instructions, but they’ve historically been bad at recognising patterns. Thanks to deep learning, this is all about to change. If you only need to analyse simple patterns, a basic classification tool like an SVM or logistic regression is typically good enough. But when your data has tens of different inputs or more, neural nets start to win out over the other methods.
Still, as the patterns get even more complex, neural networks with a small number of layers can become unusable. The reason is that the number of nodes necessary in each layer grows exponentially with the number of possible patterns in the data. Eventually, training becomes way too expensive and the accuracy starts to suffer. So for an intricate pattern – like an image of a human face, for example – basic classification engines and shallow neural nets simply aren’t good enough. The only practical choice is a deep net.
But what enables a deep net to distinguish these complex patterns? The key is that deep nets are able to break the multifaceted patterns down into a series of simpler patterns. For example, let’s say that a net has to decide whether or not an image contains a human face. A deep net would first use edges to detect different parts of the face – the lips, nose, eyes, ears, and so on – and would then combine the results together to form the whole face. This important feature – using simpler patterns as building blocks to detect complex patterns – is what gives deep nets their strength. These nets have now become very accurate and, in fact, a deep net from Google recently beat a human at a pattern recognition challenge.
What is a deep net platform?
A platform is a set of tools that other people can build on top of. For example, think of the applications that can be built off the tools provided by iOS, Android, Windows, MacOS, IBM Websphere and even Oracle BEA. Deep learning platforms come in two different forms – software platforms and full platforms. A deep learning platform provides a set of tools and an interface for building custom deep nets. Typically, it provides a user with a selection of deep nets to choose from, along with the ability to integrate data from different sources, manipulate data, and manage models through a UI. Some platforms also help with performance if a net needs to be trained with a large data set.
There are some advantages and disadvantages of using a platform rather than using a software library. A platform is an out-of-the-box application that lets you configure a deep net’s hyper-parameters through an intuitive UI. With a platform, you don’t need to know anything about coding in order to use the tools. The downside is that you are constrained by the platform’s selection of deep nets as well as the configuration options. But for anyone looking to quickly deploy a deep net, a platform is the best way to go. We’ll also look at two machine learning software platforms called H2O, and GraphLab Create, both of which offer deep learning tools.
H2O: This started out as an open source machine learning platform, with deep nets being a recent addition. Besides a set of machine learning algorithms, the platform offers several useful features, such as data pre-processing. H2O has built-in integration tools for platforms like HDFS, Amazon S3, SQL and NoSQL. It also provides a familiar programming environment like R, Python, JSON, and several others to access the tools, as well as to model or analyse data with Tableau, Microsoft Excel, and R Studio. H2O also provides a set of downloadable software packages, which you’ll need to deploy and manage on your own hardware infrastructure. H2O offers a lot of interesting features, but the website can be a bit confusing to navigate.
GraphLab: The deep learning project requires graph analytics and other vital algorithms, and hence Dato’s GraphLab Create can be a good choice. GraphLab is a software platform that offers two different types of deep nets depending on the nature of your input data – one is a convolutional net and the other is a multi-layer perceptron. The convolutional net is the default one. It also provides graph analytics tools, which is unique among deep net platforms. Just like the H2O platform, GraphLab provides a great set of data mugging features. It provides built-in integration for SQL databases, Hadoop, Spark, Amazon S3, Pandas data frames, and many others. GraphLab also offers an intuitive UI for model management. A deep net platform can be selected based on your project.
Deep learning is gaining popularity
Deep learning is a topic that is making big waves at the moment. It is basically a branch of machine learning that uses algorithms to, among other things, recognise objects and understand human speech. Scientists have used deep learning algorithms with multiple processing layers to make better models from large quantities of unlabelled data (such as photos with no descriptions, voice recordings or videos on YouTube).
The three main reasons why deep learning is gaining popularity are accuracy, efficiency and flexibility. Deep learning automatically extracts features by which to classify data, as opposed to most traditional machine learning algorithms, which require intense time and effort on the part of data scientists. The features that it manages to extract are more complex, because of the feature hierarchy possible in a deep net. They are also more flexible and less brittle, because the net is able to continue to learn on unsupervised data.















