


























































Machine learning (ML) is the new ‘in’ thing in the world of computer science. For a newbie to get into it is not very easy, however. TensorFlow Hub is one way in which newbies can work with tried and tested models, and hone their skills in this rapidly evolving field.
Starting from scratch, machine learning requires four key components — algorithms, data, compute, and expertise. If you don’t have access to any one of these, then good luck to getting a great result! One viable alternative for small-scale projects is to reproduce pre-existing experiments relevant to their use cases, tweak them, and improve on the results. However, that is easier said than done.
Reproducibility in machine learning is a crisis that has been highlighted by top researchers and publications over the years. Recent times have seen a shift towards a more open paradigm. The field’s largest conference, NeurIPS, received 8,000 submissions last year, with organisers now encouraging code-sharing for papers submitted to them. This has been done in full consideration of existing proprietary libraries and dependencies that cannot accompany the code-release, i.e., code submission is encouraged even if it is ‘non-executable’ in external environments. The move has been widely perceived as a start to a more open culture in solving problems, working with data sets, and in general, promoting transparency and reproducibility.
 “Machine learning is really hard to do, so we built TensorFlow Hub (TFHub) to allow people to reuse machine learning. We are letting people pack up good machine learning and share it with the world!” Jeremiah Harmsen from Google Zurich excitedly explains. He adds that TFHub gives people ‘smaller pieces’ of machine learning models, making it more likely for developers to reuse code.
“Machine learning is really hard to do, so we built TensorFlow Hub (TFHub) to allow people to reuse machine learning. We are letting people pack up good machine learning and share it with the world!” Jeremiah Harmsen from Google Zurich excitedly explains. He adds that TFHub gives people ‘smaller pieces’ of machine learning models, making it more likely for developers to reuse code.
It is true that models require a specific type and format of input to produce a specific output. The minute you try to modify a model, you’re likely to run into issues. With TFHub, models and modules are treated as analogues to binaries and libraries. With this, it becomes well-defined in terms of importing modules and using functionality from within it. Modules are then composable, reusable, and retrainable.
In a talk at the TensorFlow Developer Summit, researchers at Google Zurich explained how you can customise a TFHub module for your own application, by using the example of an image classification model. Most image classifiers today have already been trained for hundreds of hours on millions of images. However, if given a custom task of making predictions related to a few types of rabbits, it is not possible to find a model that directly handles this for you. It becomes a complex problem to start to solve from scratch, but with TFHub and three lines of code, you find yourself retraining a model that can give you much better results than you would probably have obtained had you started from scratch. This approach could also incorporate the weights and architectures of models that have taken researchers over 60,000 hours of effort to develop!
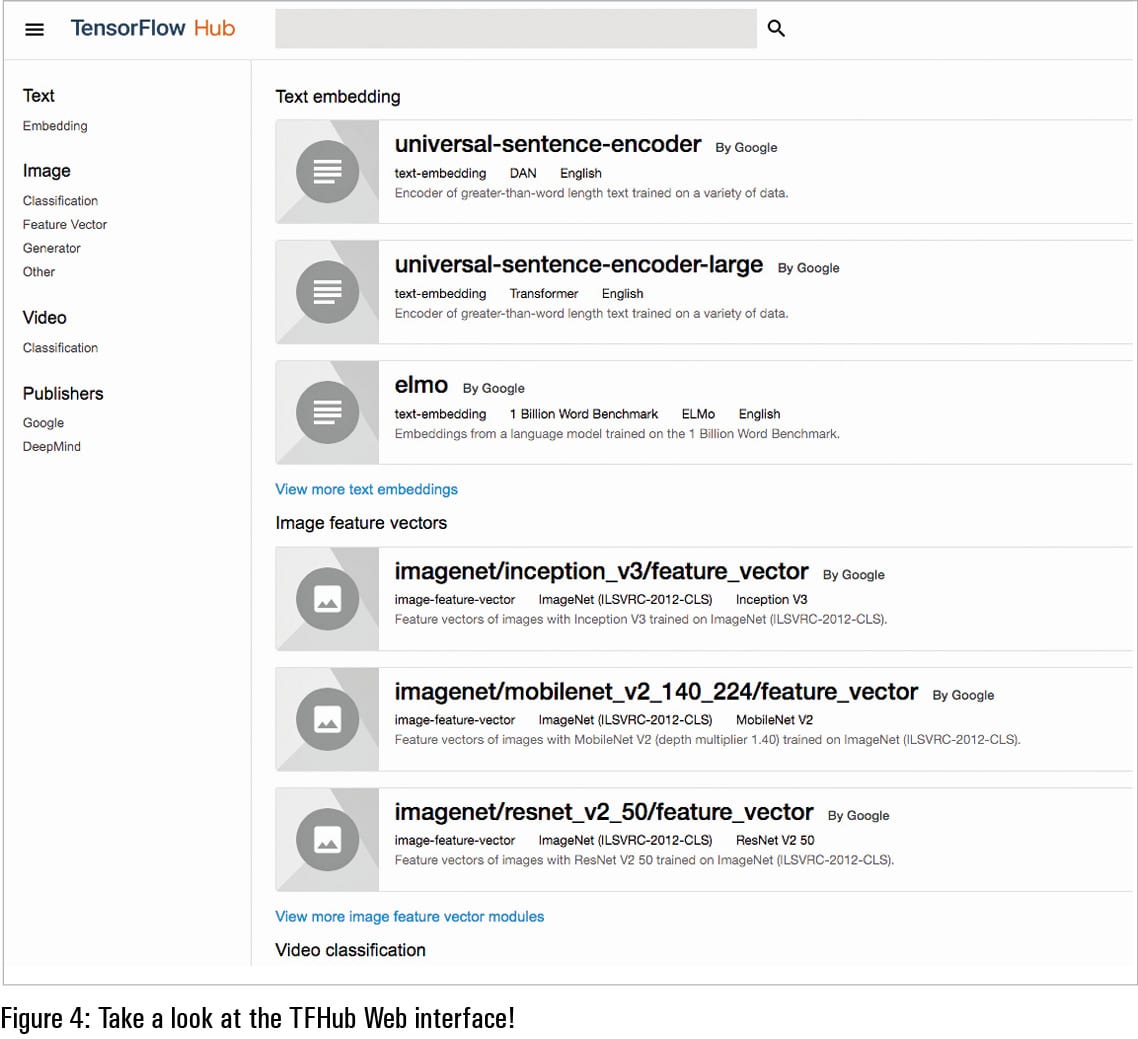
TFHub aims to foster engagement within the community and promote more transparency in machine learning. At the same time, it provides a one-stop shop for all models of TensorFlow; just add a few lines of code and you have a model running inference on new input data or better still, re-training on input data to provide an even better, more fine-tuned performance. As expected, Google remains committed to pushing out more models and enabling a better Web experience on TFHub, as evidenced by the focus on providing resources akin to the ‘Universal Sentence Encoder’ module –“a successful example of speeding up the translation from fundamental machine learning science to application in the broader developer community.”
For many teams undertaking cutting-edge research, it is not feasible to publish their TFHub modules publicly. In such cases, TFHub allows developers to publish modules to, and consume from, private storage. Instead of referring to modules by their
tfhub.dev URL, the User Guide explains how you can use a file system path to retrieve and use them in your code.
 On the whole, with the introduction of TensorFlow 2.0 and the infrastructure offered by TensorFlow Hub, Google is doubling down on its commitment to provide developers with a complete package, along with bells and whistles, to perform cutting-edge machine learning. Other projects in this area include TensorFlow data sets that capitalise on the tf.data API in order to allow for easy pipelining and data manipulation,Tensorflow.js which offers in-browser training of neural networks among other awesome functionality, and Tensorboard which is a visualisation tool for machine learning.
On the whole, with the introduction of TensorFlow 2.0 and the infrastructure offered by TensorFlow Hub, Google is doubling down on its commitment to provide developers with a complete package, along with bells and whistles, to perform cutting-edge machine learning. Other projects in this area include TensorFlow data sets that capitalise on the tf.data API in order to allow for easy pipelining and data manipulation,Tensorflow.js which offers in-browser training of neural networks among other awesome functionality, and Tensorboard which is a visualisation tool for machine learning.
TFHub has been surrounded by a lot of hype ever since its introduction, but it remains to be seen if the product is used as widely as it was expected to. The Google Zurich team is a fantastic team of engineers and researchers, who are working in tandem on TFHub, in what Dr Harmsen states is its first major infrastructure project. There are big things coming out of this lab, so it is going to be very exciting to see what is next!
















