






























































‘Linux Kernel Programming’ is a book that is targeted at people who are quite new to the world of Linux kernel development, and makes no assumptions regarding their knowledge of the kernel. The only prerequisites to reading this book is knowing your way around Linux on the command line and a working knowledge of programming on Linux with ‘C’, as that is the medium that is used throughout it (along with a few bash scripts).
This comprehensive guide to kernel internals, writing kernel modules, and kernel synchronisation was published by Packt in March 2021. All the material and code examples in the book are based on the 5.4 LTS Linux kernel. This kernel is slated to be maintained right through December 2025, thus keeping the book’s content very relevant for a long while! It can be a handy resource for people dealing with device drivers, embedded Linux, the Linux kernel or Linux programming.
The book is divided into three major sections: ‘The Basics’, ‘Understanding and Working with the Kernel’ and ‘Delving Deeper’. The extract that follows is taken from the second section, Chapter 6, titled ‘Kernel Internals Essentials – Processes and Threads’; this extract falls under the sub-section ‘Understanding Process and Interrupt Contexts’.
In Chapter 4, Writing Your First Kernel Module – LKMs, Part 1, we presented a brief section entitled Kernel architecture I (if you haven’t read it yet, I suggest you do so before continuing). We will now expand on this discussion.
It’s critical to understand that most modern OSes are monolithic in design. The word monolithic literally means a single large piece of stone. We shall defer a little later to how exactly this applies to our favorite OS! For now, we understand monolithic as meaning this: when a process or thread issues a system call, it switches to (privileged) kernel mode and executes kernel code, and possibly works on kernel data. Yes, there is no kernel or kernel thread executing code on its behalf; the process (or thread) itself executes kernel code. Thus, we say that kernel code executes within the context of a user space process or thread – we call this the process context. Think about it, significant portions of the kernel execute precisely this way, including a large portion of the code of device drivers.
Well, you may ask, now that you understand this, how else – besides process context – can kernel code execute? There is another way: when a hardware interrupt (from a peripheral device – the keyboard, a network card, a disk, and so on) fires, the CPU’s control unit saves the current context and immediately re-vectors the CPU to run the code of the interrupt handler (the interrupt service routine—ISR). Now this code runs in kernel (privileged) mode too – in effect, this is another, asynchronous, way to switch to kernel mode! The interrupt code paths of many device drivers are executed like this; we say that the kernel code being executed in this manner is executing in interrupt context.
So, any and every piece of kernel code is entered by and executes in one of two contexts:
- Process context: The kernel is entered from a system call or processor exception (such as a page fault) and kernel code is executed, kernel data worked upon; it’s synchronous (top down).
- Interrupt context: The kernel is entered from a peripheral chip’s hardware interrupt and kernel code is executed, kernel data worked upon; it’s asynchronous (bottom up).
Figure 6.1 shows the conceptual view: user-mode processes and threads execute in unprivileged user context; the user mode thread can switch to privileged kernel mode by issuing a system call. The diagram also shows us that pure kernel threads exist as well within Linux; they’re very similar to user-mode threads, with the key difference that they only execute in kernel space; they cannot even see the user VAS. A synchronous switch to kernel mode via a system call (or processor exception) has the task now running kernel code in process context. (Kernel threads too run kernel code in process context.) Hardware interrupts, though, are a different ball game – they cause execution to asynchronously enter the kernel; the code they execute (typically a device driver’s interrupt handler) runs in the so-called interrupt context.
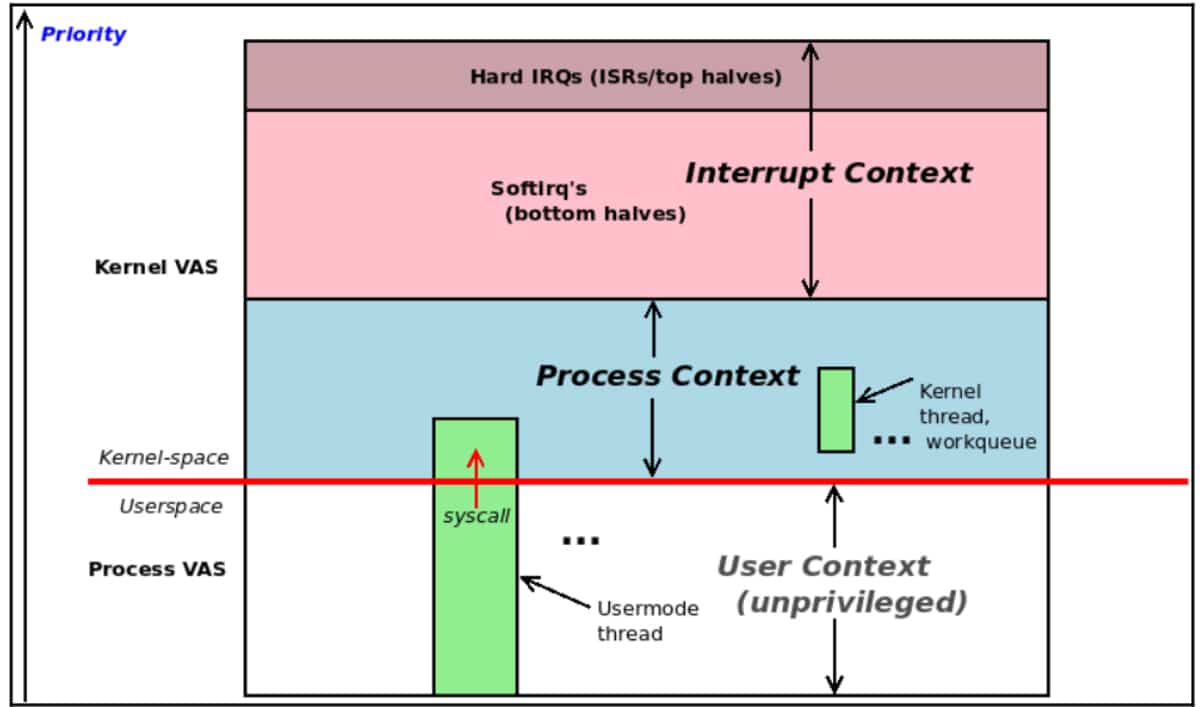
Figure 6.1 shows more details – interrupt context top and bottom halves, kernel threads and workqueues; we request you to have some patience, we’ll cover all this and much more in later chapters.
| Note: The book’s source repositories are publicly available on GitHub, as indicated below. Linux Kernel Programming (Part 1): A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization; https://github.com/PacktPublishing/Linux-Kernel-Programming Linux Kernel Programming (Part 2): Learn to work with ‘misc’ class char drivers, user-kernel interfaces, manage peripheral I/O and hardware interrupts; https://github.com/PacktPublishing/Linux-Kernel-Programming-Part-2 |
Further on in the book, we shall show you how exactly you can check in which context your kernel code is currently running. Read on!




















{kind=link}