

Deep learning is a new buzzword among machine learning researchers, both in academia and industry. It deals with making machines learn to solve complex real world tasks using approaches similar to the ones adopted by their human counterparts.
Computers are good at following instructions without even a single bit of deviation. The programs we write are simply a collection of instructions, which need to be executed in a pre-determined order. Is that good or bad? What these programs are good for is being determinable and precise with respect to their input and output mapping. At the same time, they are not so good while handling novel scenarios. The fundamental idea of machine learning is to make the machines analyse the underlying data model and develop their own understanding so that they can react to unforeseen scenarios. For example, certain tasks that are mundane for humans like recognising faces, voices, etc, dont fit into the realm of simply giving a predefined path to follow. They require the machines to learn problem-solving instead of applying a readymade formula. For example, recognising a hand written number or digit is very different from finding out the area of a circle (for which a well-proven universal formula is available). This approach of making machines understand novel problems and provide a solution is called machine learning.
Machine learning is an umbrella term covering a spectrum of approaches. Some of them are listed below:
- Support vector machines
- Bayesian networks
- Artificial neural networks (ANN)
- Genetic algorithms
- Association rule learning, etc
Deep learning falls under the ANN category with certain specific features.
Artificial neural networks (ANN)
ANN is a method to train computers in a bio-inspired manner. You may be aware that the human brain is made up of super-speciality cells called neurons. These neurons are interconnected to form a neural networkthe basic infrastructure for all the learning that we do. The uniqueness of this network is the sizethe average human brain has 100 billion neurons and each neuron may have connections to 10,000 other neurons, thus making a gigantic network of 1000 trillion connections. Another interesting feature of these neural networks is that the human brain has evolved to its present form over thousands of years to achieve optimised results.
ANN is an attempt to mimic the biological brain using software instructions, which would give the computers the ability to learn things similar to the way we do. You might understand the mammoth nature of this task from the viewpoint of size and real-time responses. However, computer scientists have attempted ANN as early as the 1940s. The lack of advancements in the hardware industry was what hampered progress. The present wave of ANN is fuelled by unprecedented growth in the hardware industry in the form of ultrafast CPUs and GPUs with multiple cores, all available at an affordable cost.
Deep learning
The ANN has a layered approach. It has one input layer and one output layer. There may be one or more hidden layers. When the constructed network becomes deep (with a higher number of hidden layers), it is called a deep network or deep learning network. The popularity of deep learning can be understood from the fact that leading IT companies like Google, Facebook, Microsoft and Baidu have invested in it in domains like speech, image and behaviour modelling. Deep learning has various characteristics as listed below:
- In the traditional approach, the features of machine learning or shallow learning have to be identified by humans whereas in deep learning, the features are not human constructed.
- Deep learning involves ANN with a greater number of layers.
- Deep learning handles end-to-end compositional models. The hierarchy of representations with different data is handled. For example, with speech, the hierarchical representation is: Audio -> Band -> Phone -> Word. For vision, it is: Pixel -> Motif -> Part -> Object.
There are plenty of resources available on the Web to understand deep learning. However, at times it leads to the problem of plenty. The lecture delivered by Dr Andrew Ng at the GPU Technology Conference 2015 is one of the best to start with, in order to get a clear understanding of deep learning and its potential applications (http://www.ustream.tv/recorded/60113824).
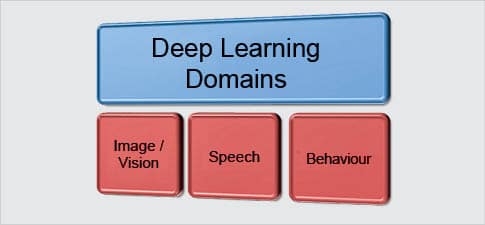
Deep learning domains
Deep learning has applications in various verticals. The three popular verticals are shown in Figure 1.
In the image domain, there are applications like classification, identification, captioning, matching, etc. The speech domain has applications like real time recognition under noisy environments. The behaviour domain has applications like trend analysis, security aspects, etc. Deep learning research studies are conducted in domains such as natural language processing, etc.
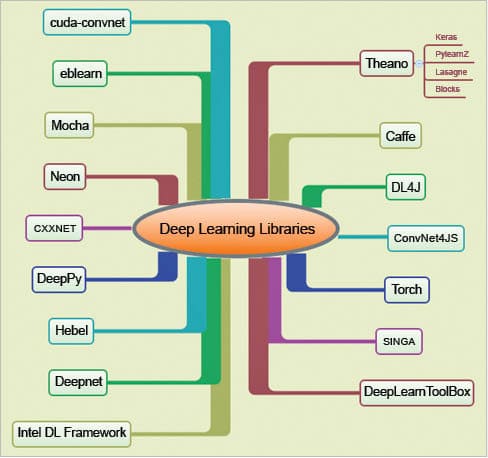
Deep learning libraries
There are many libraries that help to make the deep learning implementations quicker (Figure 2), as they make a layer of abstraction over the underlying complex mathematical representations.
Some of these libraries may turn out to be the trendsetters in 2016 and the years ahead. This article covers five of these libraries and their extensions. As deep learning itself is a bleeding edge technology, the field is in a dynamic stage. The libraries chosen for this article are representative in nature.

Theano
Theano is a Python library for defining, evaluating and optimising mathematical expressions. As deep learning involves tons of matrix/vector manipulation, Theano is employed for those tasks efficiently. It enables developers to attain the speed of execution that is possible only with direct C implementations. The greater benefit with Theano is that it can harness resources of both the CPU and the GPU.
Theano was developed at the Montreal Institute of Learning Algorithms and is available with a BSD licence. Python programmers can solve unique problems with Theano, which cannot be done with Numpy of Python. The following are some examples:
- Theano expressions can utilise both CPU and GPU; they run considerably faster than native Python algorithms.
- Theano has a unique feature of identifying unstable mathematical expressions, and it employs more stable algorithms while evaluating such expressions.
Some of the features of Theano are illustrated in Figure 3.
Many research groups have adopted Theano and there are libraries developed on top of Theano as listed below:
- Keras: This is a minimalistic library written in Python on top of Theano, which is highly suitable for quicker prototyping, as well as seamless execution in the CPU and GPU.
- Pylearn2: This is also a library that can be used on top of Theano. The developers can build their own Pylearn2 plugins with customised algorithms. The Pylearn2 code is compiled targeting either the CPU or GPU, using Theano.
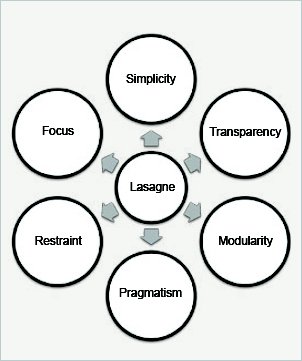
- Lasagne: This is another Theano based library, which is built with six design principles as shown in Figure 4.
- Blocks: The blocks framework enables developers to build neural network models on Theano. This framework is used along with Fuel, which provides standards for making machine-learning datasets and enables easier navigation through them.
Theano is more suitable for scenarios where finer control is needed and which require extensive customisation.
Caffe
Caffe is a super-speciality framework developed to increase the speed of deep learning implementations. Caffe was developed at Berkeley Vision and Learning Centre and is available with a BSD 2-Clause licence. Listed below are some reasons to choose Caffe:
- The switching between CPU and GPU can be carried out by setting a simple flag.
- Caffe is backed by more than 1000 developers with significant contributions. This active community backing is a big plus point.
- Caffe is superfast. Even on a single NVIDIA K40 GPU, it can infer an image in 1ms.
The popularity of Caffe can be gauged from the fact that within just two years of its release, it has got 600+ citations and 3400+ forks. The Caffe framework primarily focuses on vision, but it can be adopted for other media as well. The detailed installation instructions to configure Caffe in Ubuntu are available at http://caffe.berkeleyvision.org/installation.html.
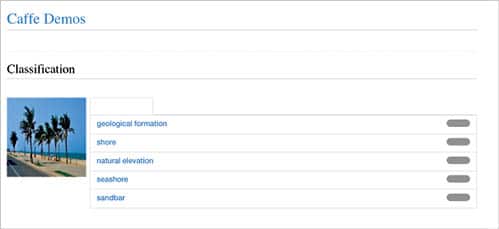
The Caffe demo for image classification is available at http://demo.caffe.berkeleyvision.org. A sample screenshot with its classification is shown in Figure 5.
Caffe sample implementations for scene recognition, object recognition, visual style recognition, segmentation, etc, are available. The Embedded Café on NVIDIA Jetson TK1 mobile board enables image inference within 35ms.
DL4J
DL4J or Deeplearning4J is an open source deep learning library which is targeted at Java/Scala. It can be directly used for deep learning implementations by non-researchers in an easier manner compared to Theano. It allows the development of faster prototyping, and is available under the Apache 2.0 licence. The DL4J use cases are listed below:
- Image recognition
- Speech processing
- Spam filtering
- E-commerce fraud detection, etc
The important features of DL4J are:
- GPU integration
- Robust n-dimensional array handling
- Hadoop and Spark scalability
- ND4J, which is a linear algebra library, and runs 200 per cent faster than Numpy
- Canova, which is a vectorisation tool for machine learning libraries.
The neural network architectures supported by DL4J are shown in Figure 6.
ConvNetJS
As of 2016, JavaScript is everywhere. Deep learning is no exception. ConvNetJS is an implementation of neural networks in JavaScript. The in-browser demos provided by ConvNetJS are really good. ConvNetJS was developed by Dr Karpathy at Stanford University. A special feature is that it doesnt require any dependencies like compilers, installers and GPUs. ConvNetJS has support for the following:
- Reinforcement learning model
- Classification (SVM) and regression (L2)
- Major neural network modules
- Image processing using Convolutional Networks
An easy-to-follow guide for using ConvNetJS is available at http://cs.stanford.edu/people/karpathy/convnetjs/started.html.

Torch
Torch is a framework for scientific computing. It has great support for many machine learning algorithms. It is based on a faster scripting language called LuaJIT, C and CUDA implementations. The primary features of Torch are:
- Neural network and energy based models
- Quick and efficient GPU support
- It has embeddable ports for iOS and Android
- Robust and powerful N-dimensional array handling
- Many functions for indexing, slicing and transposing
- Comes with a large ecosystem of community-driven packages for computer vision, machine learning, etc
Apart from the software libraries highlighted in this article, there are various other options for deep learning development like Deepnet, Hebel, Deeppy, Neon, Intel Deep learning framework and Mocha. As the field of deep learning is in its early stages and the best is yet to come, it can be confidently said that in the years ahead, deep learning will emerge as a game changer with applications in various domains.
References
[1] http://deeplearning.net/software/theano/
[2] http://keras.io/
[3] http://deeplearning.net/software/pylearn2/
[4] https://github.com/Lasagne/Lasagne
[5] https://github.com/mila-udem/blocks
[6] http://caffe.berkeleyvision.org/
[7] http://deeplearning4j.org/
[8] http://torch.ch/
[9] http://cs.stanford.edu/people/karpathy/convnetjs/started.html



{kind=link}