





























































ScyllaDB is the next-generation Apache Cassandra compatible database. Its user list of IBM, Zenly, Snapfish, AdGear, etc, is in itself a testament to its excellence. With an installer for every platform, the reader has an open invitation to give it a try.
Loved by its community of users, Apache Cassandra is widely accepted as the best highly available distributed database. With roots in both Dynamo and Bigtables, it represents 15 years of progress. However, while Cassandra is known for flexible replication, multi-data centre support and gigantic homogeneous clusters, its many issues are well known too. At times, one feels that Cassandra is a victim of its own success.
At ScyllaDB, we set our sights on delivering an open source alternative to Cassandra — one that’s rebuilt from the ground up, to deliver higher throughput, to maintain consistently low latencies and to reduce the time users spend tuning their databases. At the same time, we wanted to preserve all the things the Cassandra community loves.
Once we’d decided what we wanted to build, we had to make several important decisions about how we’d go about building it. Here, I’ll share the seven fundamental design decisions we made when architecting a better performing Cassandra and the results those decisions have had on our open source project.
Design decision 1: C++ instead of Java
We didn’t have to think long before making this initial design decision. Most systems professionals understand that Java isn’t a good language for systems programming. Why? Because it deprives the user of control. A modern database requires the ability to use large amounts of memory and to have precise control over what the computer is doing at any time. Java isn’t well suited to address either of these requirements. However, C++ serves both purposes well. It not only gives developers very precise control over everything that they might want to do, but it also allows the creation of abstractions, which lets you create complex code in a manageable way.
Our initial analysis of Cassandra revealed the problems caused by its use of Java. The lack of control makes it hard for Cassandra developers to make the database do what they want it to. For instance, consider the recent kernel-level API enhancement, sponsored by Scylla, to improve the kernel polling interface. You can’t do that with a Java virtual machine (JVM). Scylla developers check the assembly generated code frequently and verify efficiency metrics to look for potential optimisations.
JVM’s performance and latency issues caused by garbage collection are well documented. Cassandra’s developers try to bypass the garbage collector by using off-heap data structures. However, the memory becomes fragmented and is harder to tune, defeating the whole purpose of memory being managed by the runtime. By deciding to build in C++, we avoided these problems altogether.
Design decision 2: Compatibility
We realised at the outset that the Cassandra user community isn’t interested in learning yet another database or another data model. What they wanted instead was a drop-in Cassandra alternative, which overcomes the performance and latency issues that had hindered their applications. So rather than build a new suite of drivers or design another query language, we chose to leverage the work that had already gone into drivers, the language and the applications that use them. Scylla is Cassandra-compatible in the wire protocol, JMX monitoring, the underlying file format and even the configuration file.
As a result of this fundamental decision, Cassandra users migrating to Scylla are spared from having to learn an entirely new data model. Their applications will work just as before and they can continue to leverage their existing ecosystems.
Design decision 3: All things asynchronous
Modern hardware works in an asynchronous manner. Equipped with multi-core processors, these machines are capable of performing hundreds of thousands of I/O operations per second. However, in order to harness the full power of this hardware, you need asynchronous software as well.
In systems programming, there are a lot of things going on at the same time. For instance, there are multiple queries running at the same time on different cores. These queries could be waiting for data from other cores or from other nodes on the network. They could be waiting for data to arrive from the disk or they could be waiting for the cloud to provide more data.
By making everything asynchronous, we’ve created a uniform way to address the problem of waiting for something to arrive. While building a framework that handles everything asynchronously meant more upfront work for us, once it was done, we no longer had to address the problems that could arise when increasing concurrency. With this approach, the number of concurrent queries is limited not by the framework itself, but by the extent of the system’s resources.
It’s worth noting that Scylla uses Seastar, our async engine. Here, you can read how Scylla accesses the disk with async and direct DMA using the Linux API. The Pedis project (Parallel Redis) uses the Seastar engine for parallelism. Another project which uses Seastar is SMF, an ultra-fast RPC designed by Alexander Gallego of Akamai.
Design decision #4: Shard per core
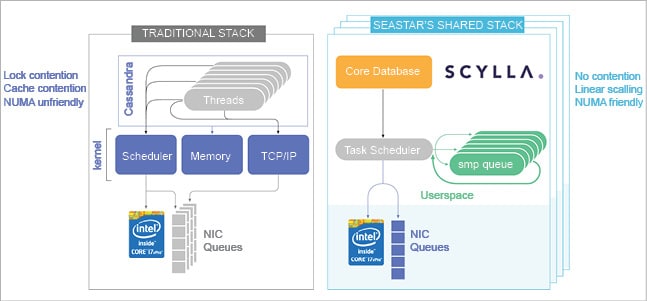
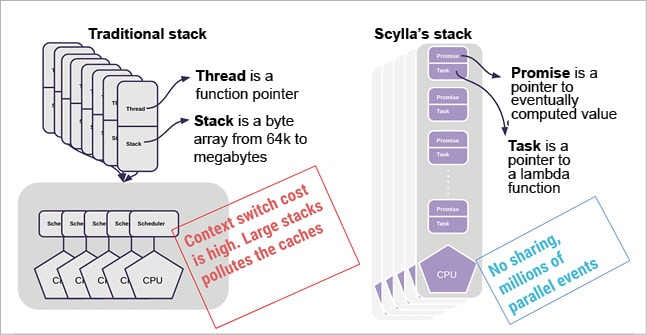
With the normal programming model of having a large number of threads, you’re guaranteed to fight scalability problems every step of the way. A threaded programming model helps the program to focus on the problem and use locks to exclusively access the data. However, with Moore’s Law being stretched to more cores instead of higher frequency, the core count grows and thus the contention. When you acquire spin locks, all of the other threads cannot access the data and are unable to proceed. Even granular locks don’t help since locking the bus to acquire a spin lock costs 20 per cent of the CPU’s time even when the lock is not contended.
The complexity of the traditional threaded model doesn’t end with locking. With more than a single socket, memory accesses may spread across sockets, but access to a memory bank that belongs to a neighbouring socket costs 2x that of a local socket. It’s very hard to code memory with NUMA oriented allocations.
Lastly, there are the I/O devices. Modern NICs and drives have multi-queue modes, where every CPU can drive I/O. The standard model usually does not have enough handlers or will cause a lot of context switches.
Scylla solves all these scalability issues by using a shared-nothing architecture. The data set is sharded into smaller ranges called shards. This is the same process as sharding a whole data set from cluster to nodes. It is completely hidden from the user.
Scylla runs multiple shards per server node. The number of shards is usually the same as the number of CPU cores or, more accurately, hyper threads. Each shard is an independent unit and fully owns its data set. A shard has a thread of execution, a single OS-level thread that runs on that core and a subset of the RAM. The thread and the RAM are pinned in a NUMA friendly way. Each shard issues its own I/O, either to the disk or to the NIC, directly.
Shards communicate using shared-memory queues, one for each pair of source:target shards. Requests that need to retrieve data from several shards are first parsed by the receiving shard, then distributed to the target shard in a map-reduce fashion using Seastar’s queues.
Each shard is executed by a single thread. However, the shard has different tasks to execute, such as network exchange, disk I/O, compaction, and reads and writes. That’s why we developed a task scheduler that schedules tiny lambda functions (continuations). It has low overhead in terms of resources and is much lighter than threads. With this approach, every core can execute a million tasks per second.
Those who have run Cassandra on a large machine have probably noticed that it’s not able to utilise all the available cores. Even though Cassandra is working as hard as it can, many of the cores are idle or not fully utilised. With the Scylla thread-per-core architecture, you can easily reach 100 per cent utilisation on all the cores—so you’re fully utilising your hardware.
Design decision 5: Unified cache vs C* cache plethora
This was actually two design decisions wrapped into one. First, we chose not to use the Linux page cache, which is built for synchronous operation. As mentioned earlier, everything is asynchronous in Scylla, so this decision was essentially made for us. While the Linux page cache has been the recipient of a lot of great work by Linux developers, it’s a general-purpose data structure. We recognised that a special-purpose cache would deliver better performance. The Linux page cache is also global, whereas Scylla is threads-per-core. We realised it would be more efficient to split the cache so that we had a separate cache for each core; thereby, we eliminated all the locking that would otherwise be required.
Due to the complexity of Cassandra’s caches, it was easy deciding to build our own cache and to make it a unified one. A unified cache can dynamically tune itself to the current workload rather than having multiple different caches that need to be tuned by the user. Scylla caches objects itself, and thus always controls their eviction, their memory footprint, and can dynamically balance the different types of cache it stores. Scylla has controllers — memtable controller, compaction controls and (coming soon) cache controller — to dynamically adjust their sizes. Once the data isn’t cached in memory, Scylla will generate a continuation task to read the data asynchronously from the disk using DMA. Seastar will execute it in a usec (1 million tasks/core/sec) and rush to run the next task. There’s no blocking, no heavyweight context switch, no waste, and no tuning.
For Scylla users, this design decision means higher ratios of disk to RAM. Each node can serve a larger amount of data; so you can use smaller clusters and more fully utilise the larger disks that are available today.
Design decision 6: I/O scheduler
To manage the data on disk, both Cassandra and Scylla use an algorithm called the Log Structured Merge Tree, which relies on background operations to perform things like compaction as well as other maintenance operations, like streaming. Issues arise when these background operations compete with user queries, thereby reducing throughput—a scenario no user would opt for.
It became clear to us that we needed to control all of the I/O going through the system. The way to do this is with a scheduler that allows the types of requests—whether they are foreground requests or background requests—to be tagged. These requests can then be metered, and the scheduler can decide the priority to be given to each class of operations.
This design decision helps Scylla users meet their SLAs. They spend less time tuning, and yet can be sure that background operations complete as quickly as possible without impacting performance. For example, if you’re commissioning a new node or decommissioning an old one, you can simply tell Scylla to perform the operation without having to worry about the speed at which it happens. The operation will automatically run at the fastest speed that does not reduce system throughput.
Design decision 7: Autonomous database
This overarching design decision incorporates some (for example: Design decisions (1) and (2)) of the choices we’d already made. Our vision has always been to provide a database that dynamically tunes itself to varying conditions. We knew that Cassandra users spend a lot of their time tuning; so we decided to build a database that monitors all the operations and adjusts the rate of the internal processors to achieve a balance.
This autonomous approach made much more sense to us than saddling users with elaborate guides and explanations on how to tune for all the changing workloads that a database must contend with. Not only does an autonomous database greatly reduce the administrative burden, it also means that users can always push the database to its limits and it will always fully utilise available resources.
A foundation for success
Of course, there have been countless other decisions we’ve had to make. However, these seven foundational decisions set the course for everything we did thereafter. I’m happy to report that we haven’t done much second guessing about our early decisions.
Now that we’ve reached parity with Apache Cassandra, we’re soon to embark on our second wave of innovation. We have lots of ideas about how to improve Scylla, and we’re happy to have many users to help guide us through this next phase.
To learn more about Scylla, read use cases and benchmarks at http://www.scylladb.com or try our open source database for yourself.

















Awesome! Really very happy to say, your post is very helpful to us. Enjoyed reading the article.