

Here’s a comprehensive insight into the transformative power of AI in visual data analysis, covering advanced deep learning models and their potential impact. We’re on the brink of an era where machines can ‘see’ as well as humans. How will this reshape our world?
Visual data (image and video data) is by far the most diverse and demanding media, and is growing at an unbelievable speed. From social media platforms capturing everyday moments to surveillance systems monitoring public spaces, the sheer volume of visual content presents a remarkable opportunity for discovery and understanding.
Despite the significant strides made in visual data analysis using current models, the field of deep learning continues to evolve, promising even more powerful and efficient solutions. More scalable and robust methods are required to efficiently index, retrieve, organise, interpret, and interact with so much visual data with greater accuracy and speed. Such new models will, in turn, facilitate making giant leaps in fields as diverse as self-driving cars, content recommendation systems, artistic creations, and visual searches. How can these advancements revolutionise visual data analysis research and push the boundaries of what we thought possible?
This article delves into the rapid innovation of AI, specifically in the context of visual data analysis, reflecting on how these advances will impact the methods in use today and improve efficiency. It will also look at the challenges present in the process. While it is impossible to detail every development, it will try to provide a comprehensive picture of how working and experimenting with AI in visual data analysis has changed the machine learning (ML) community.
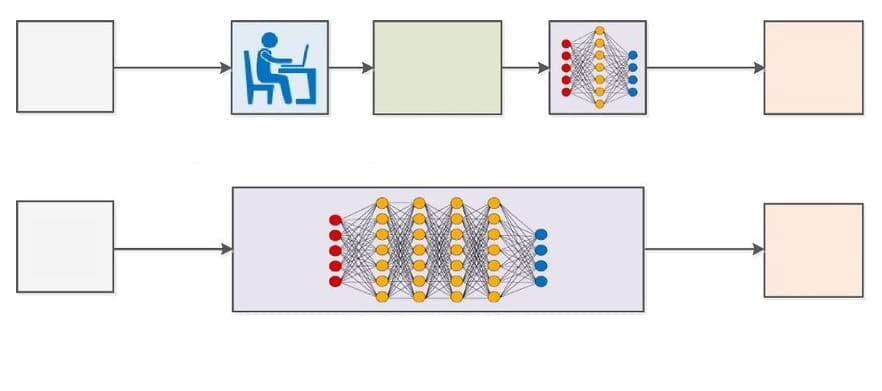
Deep learning (DL) has revolutionised the traditional (computer vision based) approach, which required extensive manual engineering of features. It has pushed the boundaries of artificial intelligence to unlock potential opportunities across industry verticals.
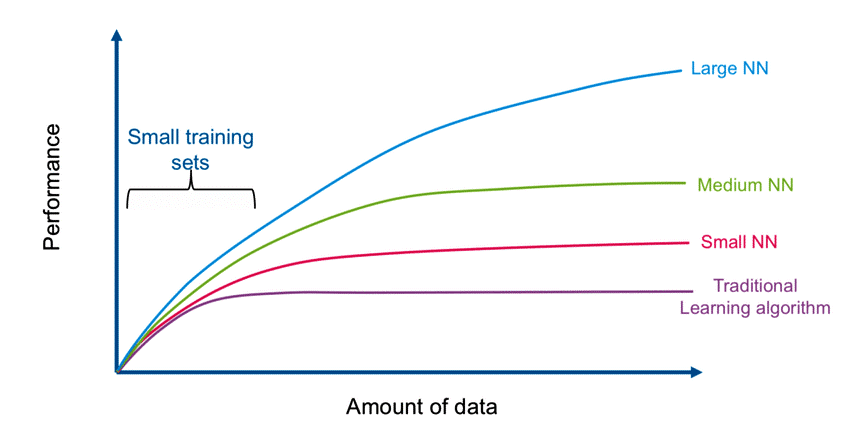
Advantages of DL based analysis
Rapid advancements in DL and enhancements in device capabilities like memory capacity, computing power, power consumption, and image sensor resolution have accelerated the spread of vision-based applications. In contrast to traditional image processing techniques, DL helps achieve greater accuracy in tasks such as object detection, image classification, image filtering, simultaneous localisation and mapping (SLAM), and semantic segmentation.
Since neural networks used in DL are trained rather than programmed, applications following this approach often require less fine-tuning and expert analysis. The availability of a humongous amount of video data in today’s system supports this cause. While computer vision algorithms tend to be more domain-specific, DL, on the other hand, provides superior flexibility because CNN (convolutional neural networks, a popular model in deep learning) models can be retrained using a custom data set for any use case without requiring manual engineering of features.
Deep learning has found widespread applications in healthcare for diagnosing diseases from radiological images, in autonomous vehicles for object detection and autonomous driving, in finance for fraud detections, as well as in retail and ecommerce, manufacturing and industry, security and surveillance for facial recognition, and more.
Limitations of DL models
Even though advances are being continuously made, DL based models presently find limited applications. Their deployment flexibility is also very low due to the following reasons:
- Huge training data available for making accurate decisions
- The device possesses high-computing power (i.e., CPU,
GPU, TPU, etc) - Uncertainty about a positive feature-engineering outcome (i.e., selecting the most suitable feature yielding the desired outcome), especially in the case of unstructured media (audio, text, images)
- Deployment restricted to high-performance devices (unsuitable for embedded, microcontrollers)
- Less or no domain expertise available
Due to their widespread applications and high effectiveness, these deep learning models are being researched and improved continuously. The focus is on improvising the optimisation and training techniques to improve speed, and make training on large data sets more efficient. Efforts are also being made to enhance the decision-making process of such models and the robustness of the system.
Here are some new and promising DL models.
Vision transformer (ViT)
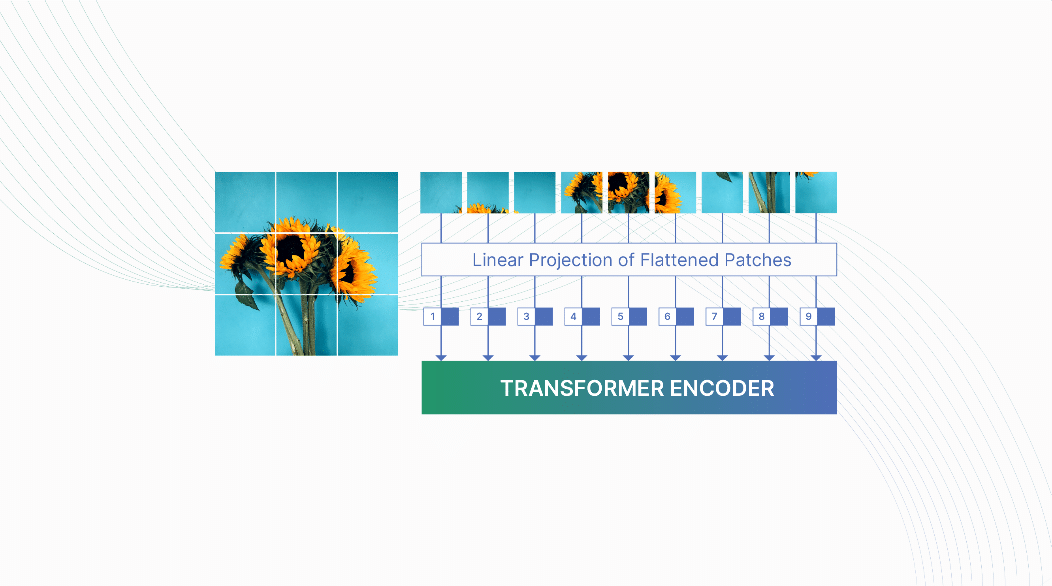
Convolution struggles to relate spatially distant concepts. Each convolution filter is bound to operate only on a small neighbourhood of pixels. Relating concepts spatially apart is often vital, but CNNs struggle to do so. Increasing the kernel size or adding more depth to the CNN mitigates the problem, but it adds model and computational complexity without explicitly solving the issue. Vision transformers address this challenge by using a self-attention mechanism that operates at a ‘global’ scale. It is a deep learning model that applies the transformer architecture to image recognition tasks.
The model takes an input image, splits it into smaller patches, and flattens them into sequences. Then it produces lower-dimensional linear embeddings from the flattened patches and adds positional embedding. Next, the sequence is fed as an input to a standard transformer encoder to pretrain the model with image labels (fully supervised on a huge data set). Finally, it is fine-tuned on the downstream data set for image classification.
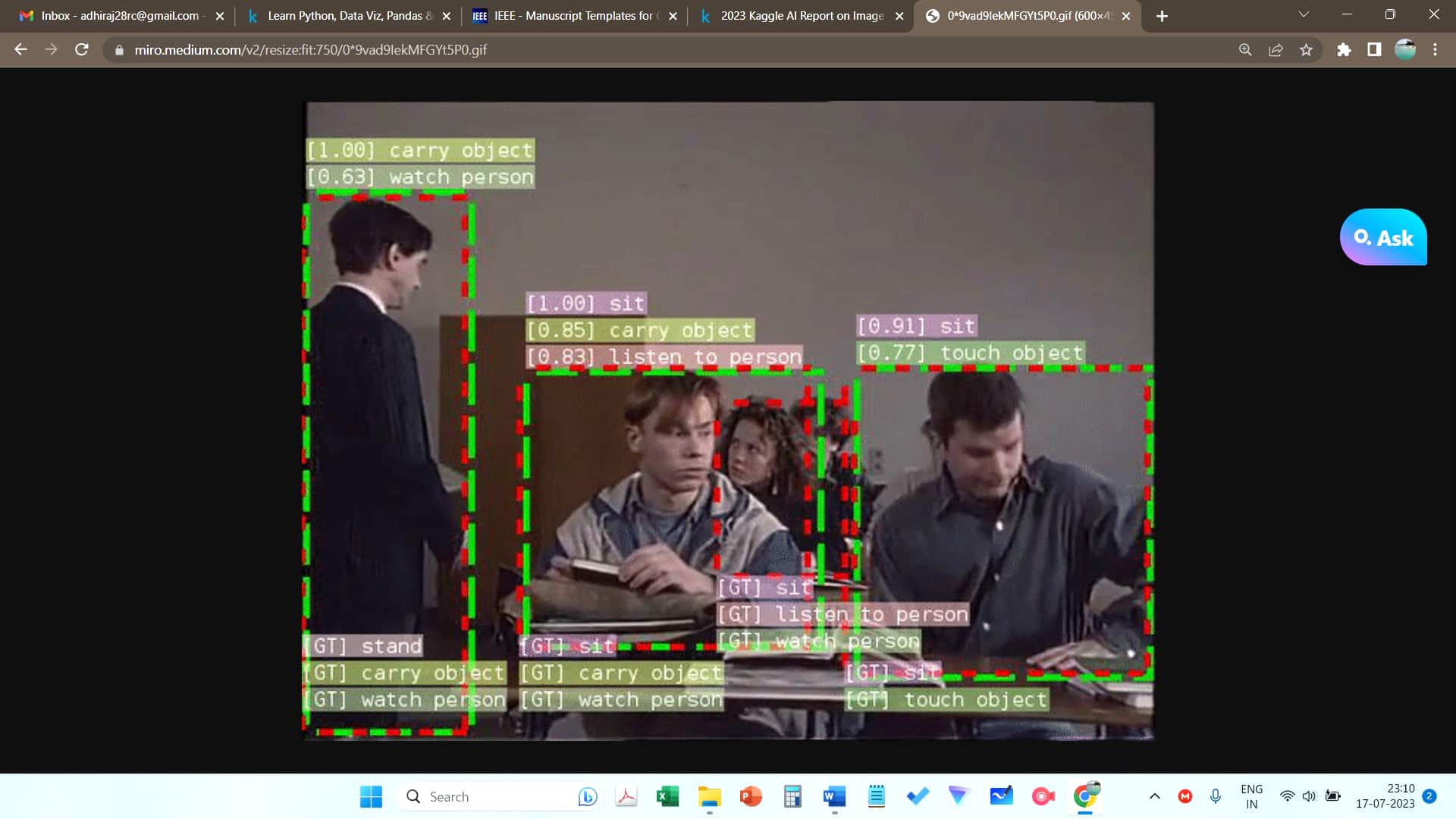
ViT is seen as an alternative to CNN in tasks that require capturing the global relationship and understanding the context of image patches. Figure 4 illustrates the image classification output of vision transformers.
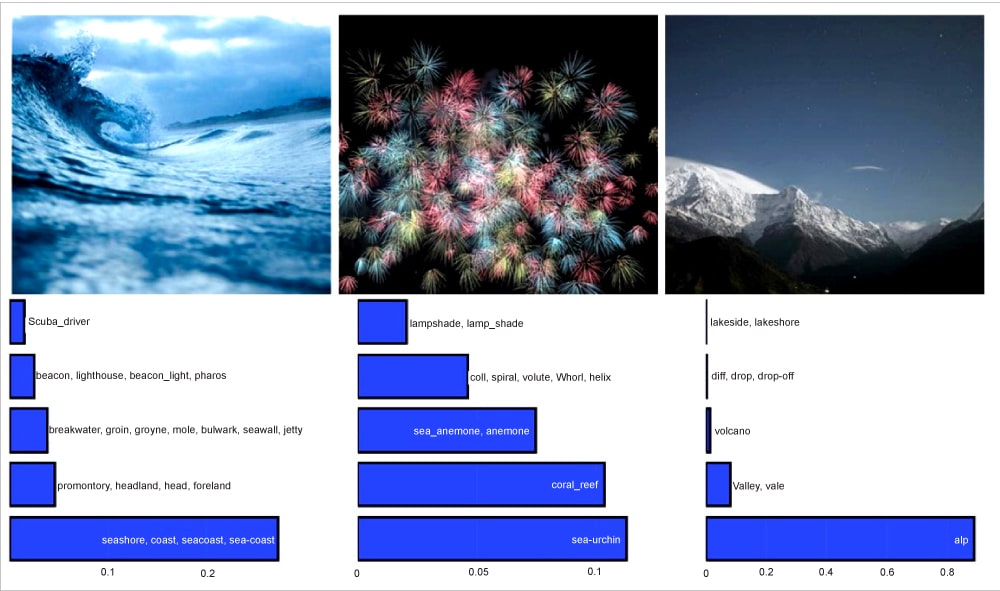
So how are image classification models used for video analysis? Well, videos are just sequences of images. We make use of sequence models along with the image model to analyse videos.
While image models like ViT and CLIP are primarily designed to analyse individual images, they may not be able to effectively capture the temporal dynamics present in videos. These include motion, action, and scene dynamics. Sequence models can model the temporal dependencies between frames, enabling them to capture these dynamics effectively.
Use of sequence models alongside image models is vital, and their applications are found in action recognition, video captioning, or identifying specific objects or events within a video. Figure 5 gives an example of video analysis using ViT.
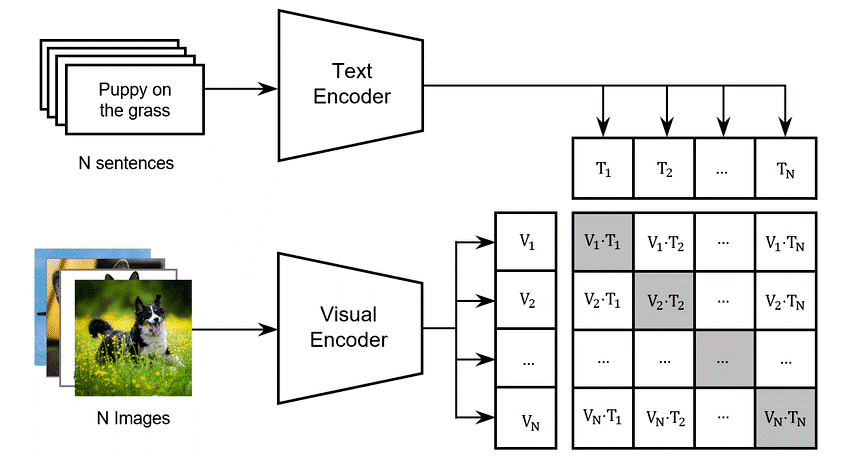
Contrastive language-image pretraining (CLIP)
In recent years, there has been a surge of interest in multimodal machine learning, which aims to develop models that can understand and generate information from both textual and visual inputs. CLIP has gained significant attention for its ability to bridge the gap between natural language processing (NLP) and computer vision (CV), enabling a more comprehensive understanding of multimodal data. It leverages the power of large-scale unsupervised pretraining to learn joint representations of images and their associated textual descriptions. The approach relies on a contrastive learning framework, which trains a model to pull together pairs of matching images and text while pushing apart non-matching pairs. By learning to associate relevant images and textual descriptions, CLIP can form a rich and coherent representation of the underlying semantic content much like the ‘zero-shot’ capabilities of GPT-2 and GPT-3.
Simple contrastive learning (SimCLR)
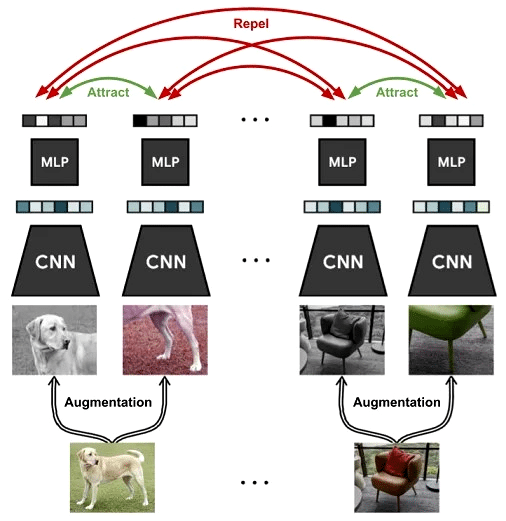
Self-supervised learning has emerged as a powerful paradigm in the field of deep learning, enabling models to learn meaningful representations from unlabelled data. SimCLR is one such self-supervised learning model. It has gained a significant amount of attention for its ability to train highly effective deep neural networks without the need for manual annotations. SimCLR operates on the principle of contrastive learning, where the model learns to differentiate between similar and dissimilar pairs of augmented views of the same image. It aims to maximise agreement between augmented versions of the same sample while minimising agreement between samples from different classes. By doing so, it effectively learns to capture the underlying semantic information present in the data.
One of the key factors that sets it apart is its simplicity. The approach utilises a straightforward two-step training procedure. First, the model learns representations through a base encoder network, and then a projection head is applied to map the learned representations to a latent space. By training the model with many diverse and augmented samples, SimCLR effectively learns to extract highly informative and discriminative features.
Momentum contrast (MoCo)
Unsupervised representation learning has also gained immense attention in the field of deep learning. Momentum contrast learning is one such unsupervised learning model that has proven to be a powerful framework for training highly effective neural networks without the need for manual annotations. MoCo builds upon the principles of contrastive learning, which aims to maximise agreement between similar samples while minimising agreement between dissimilar ones. However, what sets MoCo apart is its integration of a dynamic memory bank, which serves as a source of negative samples. By maintaining a queue of previously generated representations, MoCo enables models to learn from a broader context and capture more diverse features.
MoCo incorporates a dynamic memory bank and a momentum update mechanism. This momentum update facilitates a more stable and robust learning process, allowing the model to accumulate knowledge from previous iterations. Consequently, MoCo enhances the representation learning process by incorporating a broader range of negative samples through its memory bank. One of the significant advantages of MoCo is its scalability. By leveraging a large memory bank, MoCo can efficiently store and utilise negative samples from a vast unlabelled data set. This scalability leads to more comprehensive and diverse representation learning, enabling models to capture richer and more discriminative features.
| Traditional techniques | Replaced by |
| CNNs, feature extraction methods, region-based CNNs, image classification models, object detection models, GANs |
Vision transformers |
| Image captioning models, visual question answering models, image retrieval models | CLIP |
| Transfer learning techniques | Vision transformers, CLIP, SimCLR |
| Self-supervised learning methods | SimCLR, MoCo, vision transformers |
| Image segmentation models, video understanding models | Vision transformers, CLIP |
| Data augmentation methods | SimCLR, MoCo |
| Few-shot learning methods, anomaly detection models, video action recognition models, image compression techniques | Vision transformers, CLIP |
Applications of the latest models
I have briefly explained the most trending research topics in the visual data analysis field. We have also seen applications of CNNs, RNNs, and other deep learning models in healthcare, security, etc. Yet, the question remains: how will these newer models replace traditional techniques?
Vision transformers: Vision transformers can replace traditional CNNs and feature extraction methods in image classification, object detection, and segmentation tasks. They offer improved performance in understanding and analysing images.
CLIP: CLIP can replace traditional techniques in tasks like image classification, image retrieval, and multimodal tasks such as image captioning and visual question answering. It combines vision and language understanding, enabling models to comprehend and generate information from textual and visual inputs.
SimCLR: SimCLR can replace traditional techniques in representation learning tasks. It learns meaningful representations from unlabelled data, enhancing image classification and transfer learning applications.
MoCo: MoCo enhances representation learning and can replace traditional techniques in tasks such as image classification, object detection, and transfer learning.
In conclusion, rapid advancements in AI and deep learning models have propelled visual data analysis to new heights. The benefits of deep learning, such as improved accuracy and flexibility, along with the emergence of innovative models like vision transformers, CLIP, SimCLR, and MoCo, have transformed traditional techniques. These advancements have opened doors to groundbreaking applications across various domains. However, the following challenges still require further research.
Model interpretability: Interpretability is the degree to which a human can understand the cause of a decision. The higher the interpretability of a machine learning model, the easier it is for someone to comprehend why certain decisions or predictions have been made. Model interpretability of deep neural networks (DNNs) has always been a limiting factor for use cases requiring explanations of the features involved in modelling. This is the case for many industries such as financial services.
Robustness and adversarial defence: Adversarial attacks have revealed vulnerabilities in deep learning models. The community has identified the need for robust models that can withstand adversarial perturbations and maintain performance under different conditions. Efforts have been made to develop defences against adversarial attacks, study model robustness, and improve generalisation capabilities.
Data efficiency and generalisation: Deep learning models often require large amounts of labelled data for effective training. The need for data efficiency and better generalisation has been recognised to overcome the limitations of data availability and reduce reliance on labelled examples.
Multimodal and cross-modal learning: Multimodal data is data that uses multiple modalities. Combining and integrating information from multiple modalities, such as text, images, video, and audio, has gained importance for tasks like multimedia understanding, sentiment analysis, and human-computer interaction.
Deep learning is reshaping the way we see and understand the world around us. The future holds limitless possibilities as we continue to unlock the potential of AI in unravelling the mysteries of visual data.


