





























































Mastering MLOps depends on creating a culture of continuous learning and innovation, understanding of MLOps components, and practical implementation strategies, where every iteration brings us closer to excellence.
MLOps, short for machine learning operations, is a discipline dedicated to streamlining the entire machine learning (ML) process. It acts as the bridge between data science and IT operations, ensuring smooth and efficient deployment of ML models into production. For organisations aiming to maximise the value of their ML initiatives, implementing MLOps is crucial. Essentially, MLOps operationalises machine learning, making sure models are developed, deployed, and maintained in a scalable, reliable manner aligned with broader organisational goals.
Importance of MLOps in machine learning projects
As organisations increasingly recognise the value of machine learning in decision-making and automation, the need for a systematic approach to manage ML models in real-world environments becomes critical. Here are some key reasons why MLOps is essential.
- Efficiency and agility: MLOps facilitates a more efficient and agile development process by automating repetitive tasks, reducing manual errors, and enabling quick adaptation to changing requirements.
- Scalability: As machine learning projects grow in complexity and scale, it provides a framework for scaling the development and deployment processes, ensuring that organisations can handle increased workloads seamlessly.
- Reliability and stability: MLOps practices emphasise rigorous testing, version control, and continuous monitoring, leading to more reliable and stable ML models in production. This is crucial for applications where accuracy and consistency are paramount.
- Collaboration across teams: The technology encourages collaboration between data scientists, engineers, and operations teams. This interdisciplinary approach ensures that the unique challenges of both ML development and IT operations are addressed cohesively.
- Faster time-to-value: By automating processes and implementing continuous integration and deployment, MLOps accelerates the time it takes to move from model development to deployment, allowing organisations to realise the value of their ML investments sooner.
Goals and objectives of MLOps implementation
The implementation of MLOps is guided by specific goals and objectives, aiming to improve the overall effectiveness and efficiency of machine learning initiatives. Key goals include:
- Automation: Implement automated workflows for model training, testing, deployment, and monitoring to reduce manual intervention, minimise errors, and accelerate the development life cycle.
- Consistency: Ensure consistency in environments across development, testing, and production stages, reducing the risk of discrepancies that can impact model performance.
- Scalability: Design MLOps processes to handle increased workloads and accommodate the growing complexity of machine learning models as organisations scale their ML initiatives.
- Continuous integration and deployment: Enable seamless integration of changes to ML models and deploy new versions rapidly, allowing organisations to adapt to evolving data and business requirements.
- Monitoring and feedback: Establish robust monitoring mechanisms to track model performance, detect anomalies, and provide timely feedback to data scientists for continuous improvement.
- Security and compliance: Implement security measures and compliance checks to address data privacy concerns, ethical considerations, and regulatory requirements, ensuring responsible and legal use of machine learning models.
- Cross-functional collaboration: Foster collaboration between data science, engineering, and operations teams to create a cohesive and integrated approach to MLOps, breaking down silos and ensuring a shared understanding of goals and challenges.
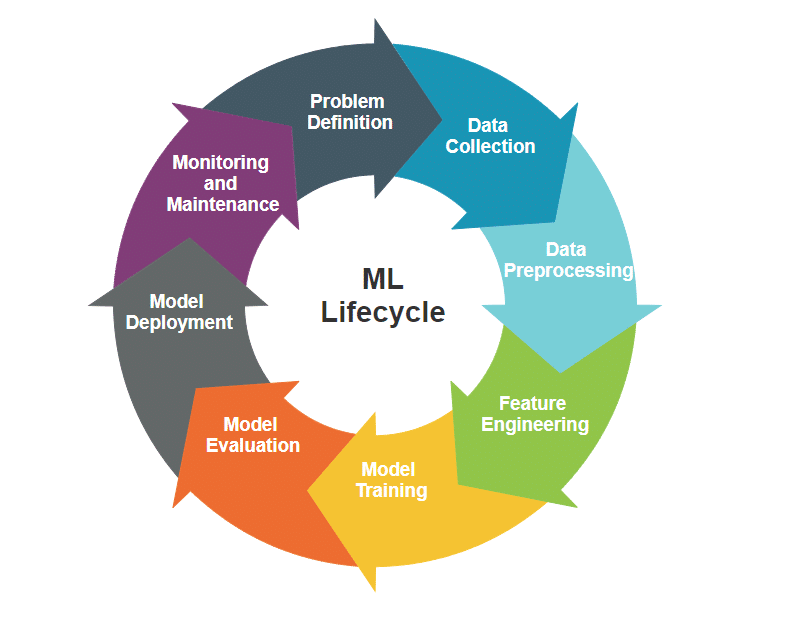
Overview of the machine learning life cycle
The machine learning life cycle refers to the end-to-end process of developing, deploying, and maintaining machine learning models. This life cycle typically involves several distinct stages.
- Problem definition: Clearly defining the problem or task that the machine learning model aims to solve.
- Data collection: Gathering relevant and sufficient data that will be used to train and evaluate the model.
- Data preprocessing: Cleaning and preparing the collected data to ensure it is suitable for training and testing.
- Feature engineering: Selecting and transforming features in the dataset to increase the model’s predictive capabilities.
- Model training: Utilising algorithms to train the machine learning model on the prepared dataset.
- Model evaluation: Assessing the model’s performance using metrics relevant to the specific problem at hand.
- Model deployment: Integrating the trained model into a production environment for practical use.
- Monitoring and maintenance: Continuously monitoring the model’s performance in the real world and making necessary updates or improvements.
| DevOps vs MLOps While DevOps and MLOps share some common principles, they differ in their focus and application. |
||
| DevOps | MLOps | |
| Focus | Collaboration and communication between software development and IT operations teams | Specifically tailored for machine learning projects, addressing the unique challenges of ML model development, deployment, and maintenance |
| Goal | Accelerating the software development life cycle, increasing collaboration, and promoting automation | Integrating machine learning workflows seamlessly into the broader DevOps framework, ensuring the reliability and scalability of machine learning systems |
Continuous integration and continuous deployment (CI/CD) in MLOps
In MLOps, CI/CD principles are adapted to accommodate the complexities of machine learning workflows, allowing for the seamless integration and deployment of models. This ensures that changes in code, data, or model architecture are tested and deployed efficiently.
Continuous integration (CI)
- Objective: Automate the integration of code changes from multiple contributors into a shared repository.
- Benefits: Detecting and resolving integration issues early, ensuring a more stable and reliable codebase.
Continuous deployment (CD)
- Objective: Automate the deployment of code changes into production or staging environments.
- Benefits: Accelerate the delivery of new features, improvements, and bug fixes with minimal manual intervention.
Model versioning and model registry
Effective model versioning and registry practices are critical in MLOps to maintain transparency, traceability, and ensure the successful deployment and monitoring of machine learning models in production.
| Model versioning | Model registry | |
| Purpose | Track and manage different versions of machine learning models | Centralised repository for storing and managing trained machine learning models |
| Benefits | Enable reproducibility, facilitate collaboration, and provide a historical record of model changes | Facilitate model discovery, sharing, and deployment across various environments |
| Implementation | Utilise version control systems (e.g., Git) to track changes in model code, and data configuration | Employ tools like MLflow, TensorBoard, or proprietary solutions to catalogue and organise models in a registry |
Components of MLOps
1. Data versioning and management
Data versioning and management are critical components of MLOps that focus on organising, tracking, and controlling changes to datasets throughout the machine learning life cycle.
- Version control: Version control systems such as Git are employed to track changes made to datasets, ensuring reproducibility and traceability in experiments.
- Dataset cataloguing: A systematic cataloguing system is implemented to manage different versions of datasets, facilitating collaboration among data scientists and maintaining a historical record of dataset changes.
- Data lineage: A clear understanding of the data lineage is established, tracking how it evolves. This is crucial for debugging, compliance, and maintaining a transparent data pipeline.
2. Model training and evaluation
Model training and evaluation involve developing and assessing machine learning models.
- Algorithm selection: Appropriate algorithms based on the nature of the problem and characteristics of the data are chosen.
- Feature engineering: This enhances the model’s ability to learn by selecting, transforming, or creating features from the dataset.
- Hyperparameter tuning: This optimises the model’s hyperparameters to improve its performance.
- Evaluation metrics: These define and measure metrics to assess the model’s accuracy, precision, recall, and other relevant criteria.
3. Model deployment and monitoring
Model deployment and monitoring are crucial steps in transitioning a trained model into a production environment.
- Deployment process: This employs CI/CD pipelines to automate the deployment of models, ensuring a smooth transition from development to production.
- Scalability: The deployment process is designed to handle varying workloads and scale resources as needed.
- Monitoring tools: Robust monitoring systems are implemented to track the model’s performance, detect anomalies, and ensure it operates within specified parameters.
- Logging: Logging mechanisms are set up to capture relevant information, facilitating debugging and troubleshooting during deployment.
4. Feedback loops and iterative model improvement
Feedback loops and iterative model improvement establish mechanisms for continuous learning and refinement based on real-world performance.
- User feedback: This collects feedback from end users and stakeholders to understand how the model behaves in real-world scenarios.
- Performance monitoring: Continuously monitors the model’s performance in production, identifying potential issues or opportunities for improvement.
- Model retraining: Uses the collected feedback and monitoring data to improve the model iteratively. This may involve retraining with new data or adjusting model parameters.
- Agile practices: Implements agile development practices to facilitate quick iterations and adaptations to evolving requirements and insights.
| Tools and technologies in MLOps As organisations embrace MLOps principles, the selection of appropriate tools and technologies becomes pivotal. The key MLOps tools and technologies are briefly described in the table below. |
||
| Component | Description | Tools and technologies |
| Version control systems for code and data | Version control is a fundamental aspect of MLOps, ensuring the traceability and reproducibility of code and data changes throughout the machine learning lifecycle. | Git
SVN (Subversion) |
| CI/CD pipelines for machine learning | Continuous integration and continuous deployment (CI/CD) pipelines streamline the process of building, testing, and deploying machine learning models. | Jenkins
CircleCI |
| Model registry and management tools | Model registry and management tools centralise the storage and organisation of trained machine learning models, facilitating discovery, sharing, and deployment. | MLflow
TensorBoard |
| Monitoring and logging solutions | Monitoring and logging solutions are crucial for maintaining the health and performance of machine learning models in production. | Prometheus
ELK Stack (Elasticsearch, Logstash, Kibana) Grafana |
Implementing MLOps in practice: A quick guide
Getting MLOps up and running doesn’t have to be complicated. Here is a concise guide to help you navigate the key steps in implementing MLOps within your organisation.
Step 1. Assess your current ML workflow
Main objective
- Gain a comprehensive understanding of your existing machine learning (ML) workflow to identify strengths, weaknesses, and areas for improvement.
Action steps
Outline your current ML processes — from data preparation to model deployment.
- Engage with stakeholders to pinpoint challenges and bottlenecks.
- Establish metrics for model training times, deployment frequency, and overall efficiency.
- Evaluate the effectiveness of communication and feedback mechanisms between teams.
Step 2. Define MLOps processes for your team
Main objective
- Develop clear MLOps processes to ensure collaboration, accountability, and efficiency within your team.
Action steps
- Clearly define the roles and responsibilities of data scientists, ML engineers, and operations.
- Document end-to-end workflows for model development, testing, deployment, and monitoring.
- Set up governance policies for version control, data management, and security.
- Foster a culture of continuous learning through regular training sessions and knowledge-sharing.
Step 3. Select appropriate tools for your environment
Main objective
- Choose tools that align with the specific needs and constraints of your organisation’s ML projects.
Action steps
- Identify the unique requirements of your ML projects, considering factors like data volume and deployment environments.
- Research and evaluate tools for version control, CI/CD, model registry, and monitoring.
- Conduct small-scale pilot projects to test the selected tools in real-world scenarios.
- Grasp an iterative approach, adjusting your toolset based on evolving project needs.
Step 4. Integrate MLOps with existing DevOps processes
Main objective
- Seamlessly integrate MLOps with your organisation’s existing DevOps processes for a unified and efficient approach.
Action steps
- Recognise commonalities between DevOps and MLOps processes.
- Facilitate workshops involving both DevOps and MLOps teams for knowledge sharing.
- Adapt DevOps principles to machine learning workflows, emphasising automation and collaboration.
- Establish unified CI/CD pipelines to streamline both traditional software development and ML model deployment.
Best practices for successful MLOps implementation
Ten key best practices for successful MLOps implementation are:
- Define roles and responsibilities: Clearly define the roles of data scientists, ML engineers, and operations. This ensures accountability and a shared understanding of individual contributions throughout the ML life cycle.
- Regular team syncs: Conduct regular sync meetings between cross-functional teams to facilitate communication, share insights, and address any bottlenecks or concerns promptly.
- Automate workflow processes: Leverage automation tools to streamline end-to-end workflows, from data preprocessing and model training to deployment and monitoring. Automation reduces manual errors, accelerates processes, and ensures consistency.
- Continuous integration and continuous deployment (CI/CD): Establish CI/CD pipelines to automate the testing and deployment of models, promoting a continuous and reliable delivery process.
- Cross-functional teams: Foster collaboration between data science, engineering, and operations teams. Encourage a culture of knowledge-sharing and cross-functional collaboration to harness diverse expertise.
- Shared documentation: Create and maintain comprehensive documentation that is accessible to all team members. This documentation should cover processes, workflows, and best practices.
- Real-time monitoring: Implement robust monitoring systems to track the performance of deployed models in real-time. Monitoring helps detect anomalies, ensures model reliability, and enables quick response to issues.
- Establish key performance indicators (KPIs): Define and monitor key metrics such as model accuracy, latency, and resource utilisation to gauge model performance against expected benchmarks.
- Version control for code and data: Utilise version control systems for both code and data. This ensures reproducibility, traceability, and the ability to roll back to previous states, supporting collaboration and experimentation.
- Containerisation: Implement containerisation (e.g., Docker) to encapsulate models and their dependencies, providing consistency across development, testing, and production environments.
Common challenges and how to overcome them for implementing MLOps
While MLOps streamlines the deployment of machine learning models, it comes with its set of challenges. Addressing these challenges is crucial for a successful MLOps implementation.
1. Data management challenges
- Challenge: Managing diverse datasets with varying formats and sizes.
- Solution: Implement robust data versioning, cataloguing, and lineage tracking to maintain data quality and reproducibility.
2. Model deployment complexity
- Challenge: Complexities in deploying models to production environments.
- Solution: Utilise containerisation (e.g., Docker) and orchestration tools (e.g., Kubernetes) to simplify deployment and ensure consistency across environments.
3. Lack of collaboration
- Challenge: Siloed teams lead to a lack of collaboration.
- Solution: Promote cross-functional collaboration through shared documentation, collaborative workshops, and fostering a culture of knowledge-sharing.
4. Model drift and performance decay
- Challenge: Models lose accuracy over time due to changing data patterns.
- Solution: Implement automated monitoring for model drift and establish retraining schedules based on performance metrics.
5. Security and compliance concerns
- Challenge: Ensuring data privacy and compliance with industry regulations.
- Solution: Incorporate security measures such as encryption, access controls, and regular audit processes to adhere to compliance standards.
To put it simply, MLOps is your key to unleashing the full power of machine learning. It’s not just a process; it’s a way of thinking that drives organisations toward long-lasting success and innovation in the world of data science.


















{kind=link}