

Open source software has an array of tools that deal with high speed Big Data, of which Apache Storm is very popular. This article discusses various aspects of Apache Storm
Big Data analytics is one of the key areas of research today, and uses assorted approaches in data science and predictive analysis. There are a number of scenarios in which enormous amounts of data are logged every day and need deep evaluation for research and development. In medical science, there are numerous examples where processing, analysis and predictions from huge amounts of data are required regularly. As per reports from First Post, data of more than 50 petabytes is generated from each hospital of 500 beds in the USA. In another research study, it was found that one gram of DNA is equivalent to 215 petabytes in digital data. In another scenario of digital communication, the number of smart wearable gadgets has increased from 26 million in 2014 to more than 100 million in 2016.
The key question revolves around the evaluation of huge amounts of data growing at great speed. To preprocess, analyse, evaluate and make predictions on such Big Data based applications, we need high performance computing (HPC) frameworks and libraries, so that the processing power of computers can be used with maximum throughput and performance.
There are many free and open source Big Data processing tools that can be used. A few examples of such frameworks are Apache Storm, Apache Hadoop, Lumify, HPCC Systems, Apache Samoa and ElasticSearch.

MapReduce technology
Of the above-mentioned tools, Apache Storm is one of the most powerful and performance-oriented real-time distributed computation systems under the free and open source software (FOSS) paradigm. Unbound and free flowing data from multiple channels can be effectively logged and evaluated using Apache Storm with real-time processing, compared to batch processing in Hadoop. In addition, Storm has been effectively adopted by numerous organisations for corporate applications with the integration of some programming language, without any issues of compatibility. The state of clusters and the distributed environment is managed via Apache Zookeeper within the implementation of Apache Storm. Research based algorithms and predictive analytics can be executed in parallel using Apache Storm.
MapReduce is a fault-tolerant distributed high performance computational framework which is used to process and evaluate huge amounts of data. MapReduce-like functions can be effectively implemented in Apache Storm using bolts, as the key logical operations are performed at the level of these bolts. In many cases, the performance of bolts in Apache Storm can outperform MapReduce.
Key advantages and features of Apache Storm
The key advantages and features of Apache Storm are that it is user friendly, free and open source. It is fit for both small and large scale implementations, and is highly fault tolerant and reliable. It is extremely fast, does real-time processing and is scalable. And it performs dynamic load balancing and optimisation using operational intelligence.

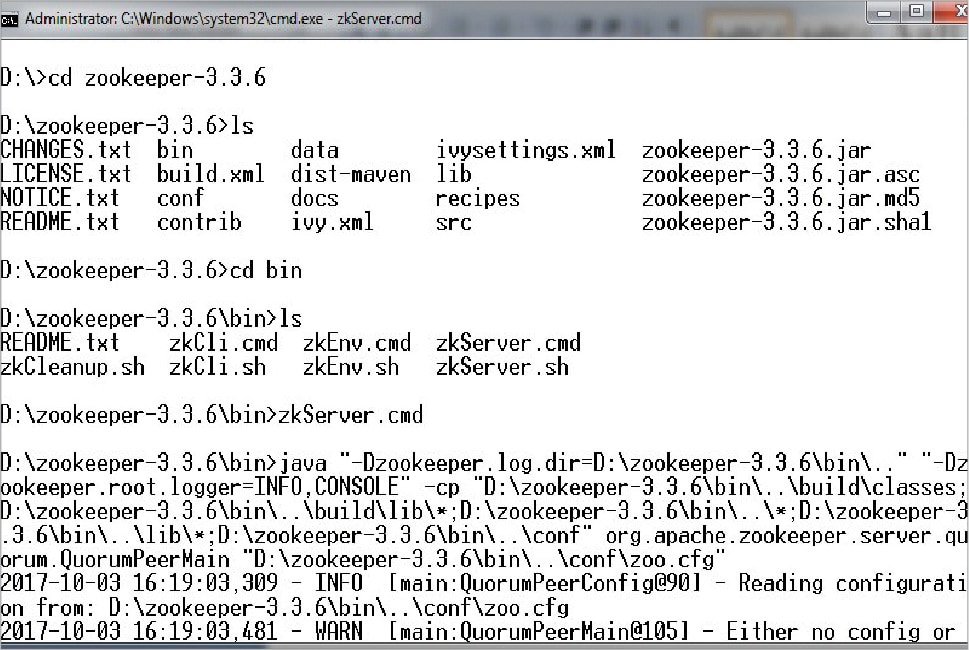
Installing Apache Storm and Zookeeper on a MS Windows environment
First, download and install Apache Zookeeper from https://zookeeper.apache.org/.
Next, configure and run Zookeeper with the following commands:
MSWindowsDrive:\> cd zookeeper-Version MSWindowsDrive:\ zookeeper-Version> copy conf\zoo_sample.cfg conf\zoo.cfg MSWindowsDrive:\ zookeeper-Version> .\bin\zkServer.cmd
The following records are updated in zoo.cfg:
tickTime=2000 initLimit=10 syncLimit=5 dataDir= MSWindowsDrive:/zookeeper-3.4.8/data
Now, download and install Apache Storm from http://storm.apache.org/ and set STORM_HOME to MSWindowsDrive:\apache-storm-Version following in environment variables.
Perform the modifications in storm.yaml as follows:
storm.zookeeper.servers: – “127.0.0.1” nimbus.host: “127.0.0.1” storm.local.dir: “D:/storm/datadir/storm” supervisor.slots.ports: – 6700 – 6701 – 6702 – 6703
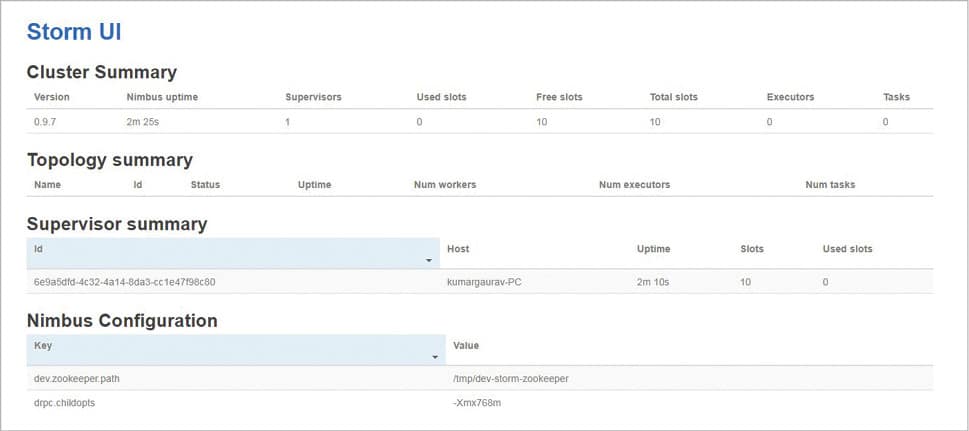
In the MS Windows command prompt, go to the path of STORM_HOME and execute the following commands:
1. storm nimbus 2. storm supervisor 3. storm ui
In any Web browser, execute the URL http://localhost:8080 to confirm the working of Apache Storm.
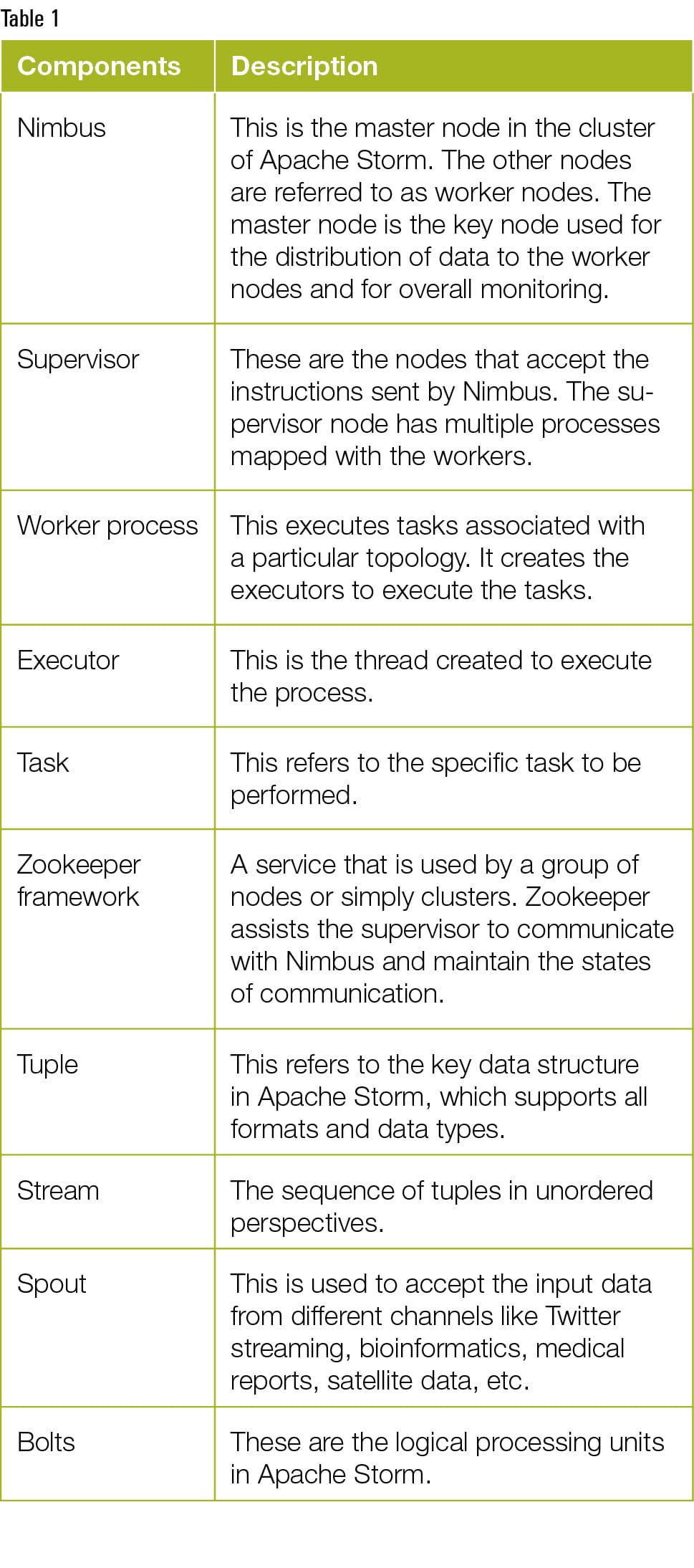
Apache Storm is associated with a number of key components and modules, which work together to do high performance computing. These components include Nimbus Node, Supervisor Node, Worker Process, Executor, Task and many others. Table 1 gives a brief description of the key components used in the implementation of Apache Storm.
 Extraction and analytics of Twitter streams using Apache Storm
Extraction and analytics of Twitter streams using Apache Storm
To extract the live data from Twitter, the APIs of Twitter4j are used. These provide the programming interface to connect with Twitter servers. In the Eclipse IDE, the Java code can be programmed for predictive analysis and evaluation of the tweets fetched from real-time streaming channels. As social media mining is one of the key areas of research in order to predict popularity, the code snippets are available at https://www.opensourceforu.com/article_source_code/2017/nov/ storm.zip can be used to extract the real-time streaming and evaluation of user sentiments.
Scope for research and development
The extraction of data sets from live satellite channels and cloud delivery points can be implemented using the integrated approach of Apache Storm to make accurate predictions on specific paradigms. As an example, live streaming data that gives the longitude and latitude of a smart gadget can be used to predict the upcoming position of a specific person, using the deep learning based approach. In bioinformatics and medical sciences, the probability of a particular person getting a specific disease can be predicted with the neural network based learning of historical medical records and health parameters using Apache Storm. Besides these, there are many domains in which Big Data analytics can be done for a social cause. These include Aadhaar data sets, banking data sets and rainfall predictions.



{kind=link}