






























































ONNX or Open Neural Network Exchange (onnx.ai) is a community project created by Facebook and Microsoft. It is intended to provide interoperability within the AI tools community. ONNX unlocks the framework dependency for AI models by bringing in a new common representation for any model, which allows easy conversion of a model from one framework to another.
Deep learning with neural networks is accomplished through computation over dataflow graphs. Developers use frameworks such as CNTK, Caffe2, Theano, TensorFlow, PyTorch and Chainer to represent a computational graph. All these provide interfaces that make it simple for developers to construct computation graphs and runtimes that process the graphs in an optimised way. The graph serves as an intermediate representation (IR) that captures the specific intent of the developer’s source code, and is conducive for optimisation and translation to run on specific devices (CPU, GPU, FPGA, etc).
The pain point with many frameworks is that each one of them follows its own representation of a graph with similar capabilities. In simple words, a model is bound to a framework with the stack of API, graph and runtime. We can’t take a model from one framework to another. Besides this, frameworks are typically optimised for certain specific characteristics, such as fast training, supporting complicated network architectures, inference on mobile devices, etc. It’s up to the developer to select a framework that is optimised for one of these characteristics. Additionally, these optimisations may be better suited for particular stages of development. This leads to significant delays between research and production due to the necessity of conversion.
ONNX was launched with the goal of democratising AI, by empowering developers to select the framework that works best for their project, at any stage of development or deployment. The Open Neural Network Exchange (ONNX) format is a common IR to help establish this powerful ecosystem. By providing a common representation of the computation graph, ONNX helps developers choose the right framework for their task, allows authors to focus on innovative enhancements, and enables hardware vendors to streamline optimisations for their platforms.
ONNX provides the definition of an extensible computation graph model, as well as definitions for built-in operators. Each computation graph is structured as a list of nodes forming an acyclic graph. Here, the node is defined as a piece of a computational block with one or more inputs and one or more outputs. Each node is a call to an operation. The graph also has metadata to document or describe the model. Operators are implemented externally to the graph, but the built-in operators are portable across frameworks. Every framework supporting ONNX will provide implementations of these operators on the applicable data types.
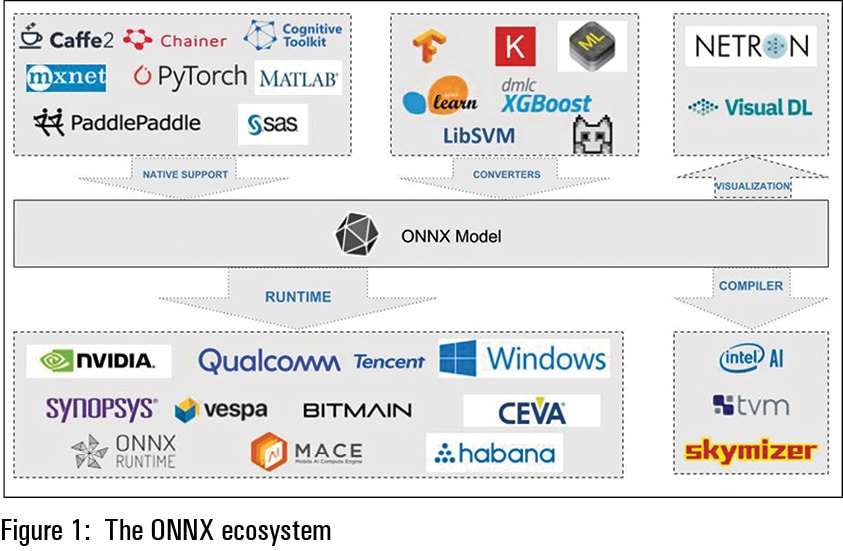
As of today, ONNX supports various frameworks like Caffe2, Chainer, Cognitive toolkit, MxNet, PyTorch, PaddlePaddle, MATLAB and SAS. ONNX also supports various converters for TensorFlow, Keras, CoreML, Scikit Learn, XGBoost, LibSVM and NCNN(Tencent). The execution runtimes supported by ONNX are NVIDIA, Qualcomm, Bitmain, Tencent, Vespa, Windows, Synopsys, Ceva, Mace, Habana and, recently, Onnx Runtime. There are also compilers for ONNX models from Intel AI, Skymizer and TVM. NETRON and VisualDL help ONNX to visualise and manipulate graphs.
With the wide range of frameworks, converters, runtimes, compilers and visualisers, ONNX unlocks the dependencies and allows developers to make their own choices regarding frameworks and tools. ONNX has two variants. The base variant is for machine learning based on neural networks. Another variant, ONNX-ML, adds additional operators and data types for classical machine learning algorithms.
More details about ONNX Intermediate Representation (IR), operator information and graph utilities can be found at https://github.com/onnx/onnx.
Setting it up
ONNX is released as a Python package and can be installed and verified. ONNX graph representation is based on protobuf; hence, protobuf is a dependency for ONNX. On Ubuntu Linux, the following command can install protobuf dependencies:
test@test-pc:~$ sudo apt-get install protobuf-compiler libprotoc-dev
The ONNX Python package can be installed and verified from the Python package manager as shown below:
test@test-pc:~$ pip3 install onnx test@test-pc:~$ python3 -c “import onnx”
ONNX is just a graphical representation and when it comes to executing an ONNX model, we still need a back-end. In this example, we use the TensorFlow back-end to run the ONNX model and hence install the package as shown below:
test@test-pc:~$ pip3 install onnx_tf test@test-pc:~$ python3 -c “from onnx_tf.backend import prepare”
Now we have the setup ready to build a model in ONNX and execute it in the TensorFlow back-end.
Alternatively, ONNX is also published as Docker images for CPU and GPU environments. Those who are familiar with Docker can use the following command to set up the ONNX Docker environment:
docker run -it --rm onnx/onnx-docker:cpu /bin/bash
Use the following command for environments with GPU support. This option requires NVIDIA-Docker as a prerequisite.
nvidia-docker run -it --rm onnx/onnx-docker:gpu /bin/bash
An example
This simple example demonstrates how to build a simple graph and execute it on the TensorFlow back-end. Copy the following snippet of code to add two tensors as test.py.:
# Imports from ONNX from onnx import helper, TensorProto from onnx_tf.backend import prepare import numpy as np # Input shape and dtype in_shape = (2, 3) dtype = “float32” out_shape = in_shape # Make use of helper to construct a node to produce “out” by adding “in1” and “in2”. z = helper.make_node(“Add”, [‘in1’, ‘in2’], [‘out’]) # Make a graph that produce z from inputs named “in1” and “in2” graph = helper.make_graph([z], ‘_test’, inputs = [helper.make_tensor_value_info(“in1”, TensorProto.FLOAT, list(in_shape)), helper.make_tensor_value_info(“in2”, TensorProto.FLOAT, list(in_shape))], outputs = [helper.make_tensor_value_info(“out”, TensorProto.FLOAT, list(out_shape))]) # Now make an ONNX model from graph. model = helper.make_model(graph, producer_name=’_test’) # Input data for graph inputs. x = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) y = np.array([[3.0, 3.0, 3.0], [3.0, 3.0, 3.0]]) # Use the backend and prepare the ONNX model for execution. tf_rep = prepare(model) # Run the tensorflow representation with inputs. output = tf_rep.run([x, y]) # Output print(“Output:”, output)
Run the above sample code; it produces the following output, which is a result of adding two input tensors.
test@test-pc:~$ python3 test.py Output: Outputs(out=array([[4., 5., 6.], [7., 8., 9.]], dtype=float32))
In the above example, we built a simple graph by constructing ONNX nodes. This example uses the TensorFlow back-end for execution. ONNX offers a wide range of back-end support to execute the same ONNX model. The following section explains how to use a converter to import a pretrained graph from a different framework and then execute it.
Using a converter
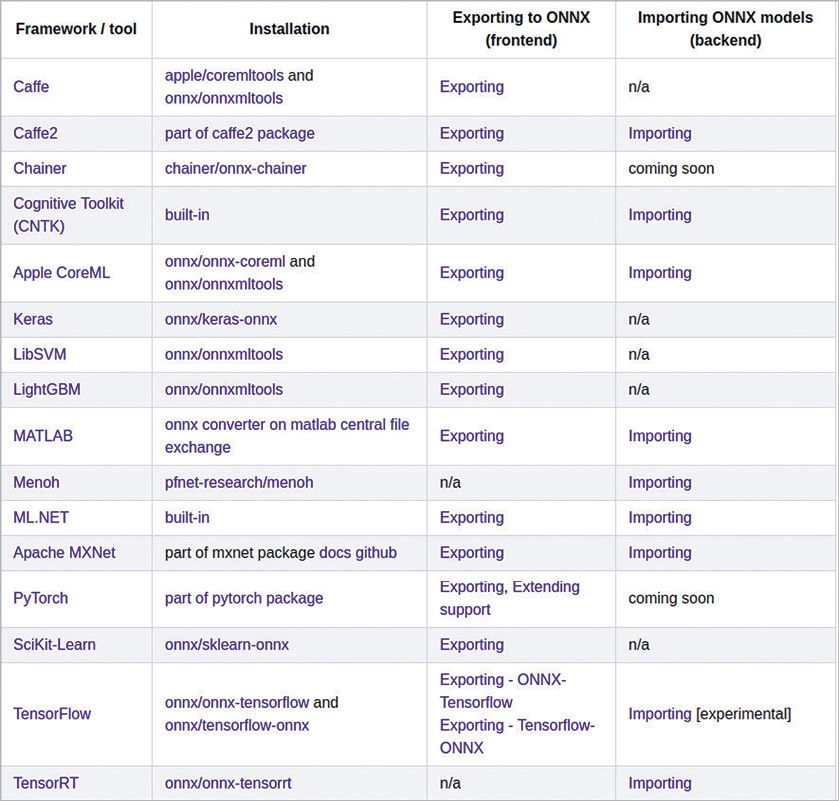
As its name suggests, ONNX is aimed at exchanging AI models across frameworks. ONNX has a project called ‘onnxmltools’ (https://github.com/onnx/onnxmltools) which has converters for various frameworks like CoreML, Scikit Learn, Keras, SparkML, LightBGM, LibSVM and XGBoost. For TensorFlow models, the project is ‘tensorflow-onnx’ (https://github.com/onnx/tensorflow-onnx), which provides the converter utility.
These converters basically enable converting an AI model from one framework to another. Let’s look at the example of importing a pretrained TensorFlow model into ONNX, and then infer and save it in the ONNX format.
Download and extract the Mobilenet pretrained model from http://download.tensorflow.org/models/mobilenet_v1_2018_08_02/mobilenet_v1_1.0_224.tgz.
Extracting this will have a TensorFlow protobuf as shown below:
test@test-pc:~$ ls mobilenet_v1_1.0_224 Mobilenet_v1_1.0_224.ckpt.data-00000-of-00001 Mobilenet_v1_1.0_224.ckpt.meta Mobilenet_v1_1.0_224_frozen.pb Mobilenet_v1_1.0_224.ckpt.index
Use the following sample and load the TensorFlow model, convert to an ONNX model and infer using the ONNX Runtime back-end.
# Tensorflow imports import tensorflow as tf # Numpy import numpy as np #Onnx from onnx import load # Tensorflow to ONNX converter import tf2onnx # OnnxRuntime backend import onnxruntime.backend as backend # Import the Tensorflow protobuf into session tf.reset_default_graph() with tf.gfile.FastGFile(“./mobilenet_v1_1.0_224_frozen.pb”, ‘rb’) as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) graph = tf.import_graph_def(graph_def, name=’’) with tf.Session() as sess: # Use tf2onnx converter and build onnx_graph onnx_graph = tf2onnx.tfonnx.process_tf_graph(sess.graph, input_names=[“input:0”], output_names=[“MobilenetV1/Predictions/Reshape_1:0”]) # Make ONNX model from graph model_proto = onnx_graph.make_model(“test”) # Optionally the ONNX model can be saved as a serialized protobuf. with open(“mobilenet_v1.onnx”, “wb”) as f: f.write(model_proto.SerializeToString()) # A ONNX saved model can be loaded by load utility. model_new = load(“mobilenet_v1.onnx”) # Prepare some random test data in_shape = (1, 224, 224 , 3) data = np.random.uniform(size=in_shape).astype(‘float32’) # We can now use any ONNX backend to execute the graph # Here we use onnxruntime backend. # Prepare backend session with ONNX model sess = backend.prepare(model_new, ‘CPU’) # Execute on backend output = sess.run(data) # Output print(“Output:”, output)
The above example uses the tf2onnx package, which is a converter for TensorFlow to ONNX. For many frameworks, these converters are natively available, and for others there is an exclusive tool for conversion. A complete list of converters available for various frameworks is shown in Figure 2.
ONNX Model Zoo
To enable developers to start using ONNX, the community has hosted Model Zoo (https://github.com/onnx/models), which is a collection of pretrained state-of-art models in the ONNX format for image classification, object detection, image segmentation, gesture analysis, image manipulation, speech and audio processing, machine translation, language modelling and the visual question answering dialogue. A wide variety of Jupyter notebooks is available under this project, which helps developers to start with ease.
Deployment
ONNX deployment is possible in various targets starting from Android and iOS devices to AWS Lambda, Amazon SageMaker and Azure back-ends. A range of tutorials demonstrating various deployment scenarios can be found at https://github.com/onnx/tutorials#end-to-end-tutorials.
ONNX Runtime
ONNX Runtime is a new initiative from Microsoft towards ONNX’s very own deployment runtime environment for ONNX models. It supports CUDA, MLAS (Microsoft Linear Algebra Subprograms), MKL-DNN and MKL-ML for computation acceleration. There is ongoing collaboration to support Intel MKL-DNN, nGraph and NVIDIA TensorRT. ONNX Runtime supports Python, C#, C and C++ API on Windows, Linux and Mac operating systems.
ONNX Runtime is released as a Python package in two versions—onnxruntime is a CPU target release and onnxruntime-gpu has been released to support GPUs like NVIDIA CUDA. With hardware acceleration and dedicated runtime for ONNX graph representation, this runtime is a value addition to ONNX.
Contributors
ONNX is licensed under MIT. It is supported by a wide range of community members from across academic institutions like the Technical University of Munich and MIT, from Facebook and Microsoft, along with many freelancers and anonymous contributors.
















