






























































This is the second part of the two-part series where we continue to uncover the magic of container technology. The first part was published in the September 2020 issue of Open Source For You.
In the first part, we briefly went over what containers are and the reason why they came into existence, by discussing the problem statement that they aimed to solve. We started out on building a container from scratch. During the process, we covered namespaces and the important part that they play in container technology, and now, we shall be continuing from where we left off.
Having made the necessary changes to the code as discussed in the last part, if we now run our script as it is, we will notice that the results that we get are still not quite different. To understand why, we need to know what exactly happens behind the scenes when we run the ps command.
It turns out that ps looks at /proc directory to find out what processes are currently running on the host. If we run ls /proc from our host OS and then from our container, we can see that the contents of the /proc directory in both cases are one and the same. To overcome this hurdle, we want the ps of our container to be looking at a /proc directory of its own. In other words, we need to provide our container its own file system. This brings us to an important concept of containers: layered file systems.
Layered file systems
Layered file systems are how we can efficiently move whole machine images around. They are the reason why the ship does not sink. At a basic level, layered file systems optimise the call to create a copy of the root file system for each container. There are numerous ways of doing this.
Btrfs (https://btrfs.wiki.kernel.org/) uses copy on write (COW) at the file system layer. Aufs (https://en.wikipedia.org/wiki/Aufs) uses union mounts. Since there are so many ways to achieve this step, we will just use something simple. We will make a copy of the file system. It is slow, but it works.
To do this, I have a copy of the Lubuntu file system copied in the path specified below. The same can be seen in the screenshot provided in Figure 1, as I have touched HOST_FS and CONTAINER_FS as two files within the root of the host and within the copy of our Lubuntu FS.
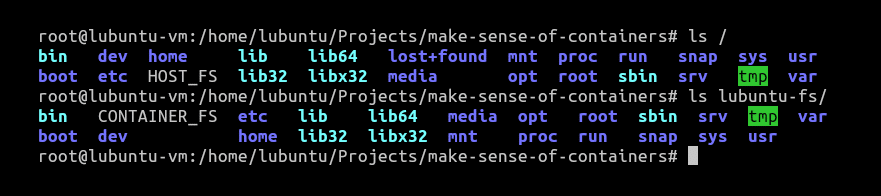
We will now have to let our container know about this file system and ask it to change its root to this copied file system. We will also have to ask the container to change its directory to / once it’s launched.
func child() {
// Stuff that we previously went over
must(syscall.Chroot(“/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs”))
must(syscall.Chdir(“/”))
must(cmd.Run())
}
Upon running this, we get our intended file system. We can confirm it in Figure 2 as we can see CONTAINER_FS, the file that we created in our container.
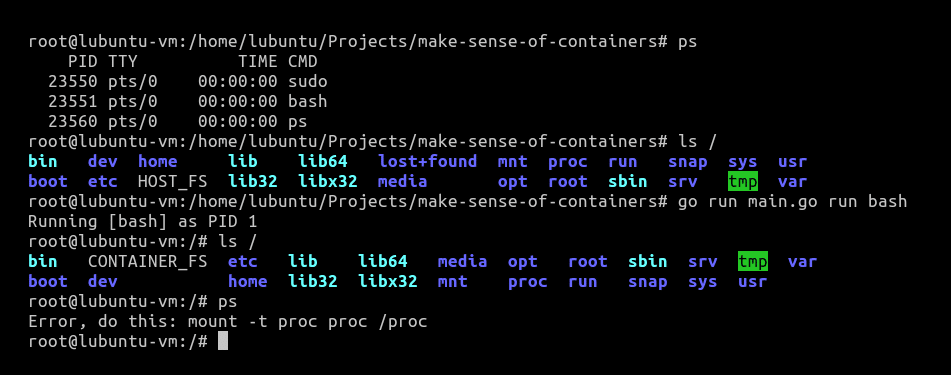
However, despite all of these efforts, ps still remains a problem.
This is because while we provided a new file system for our container using chroot, we forgot that /proc in itself is a special type of virtual file system.
/proc is sometimes referred to as a process information pseudo-file system. It doesn’t contain ‘real’ files but runtime system information like system memory, devices mounted, hardware configuration, etc. For this reason, it can be regarded as a control and information centre for the kernel. In fact, quite a lot of system utilities are simply calls to files in this directory. For example, lsmod is the same as cat /proc/modules. By altering files located in this directory you can even read/change kernel parameters like sysctl while the system is still running.
Hence, we need to mount /proc for our ps command to be able to work.
func child() {
// Stuff that we previously went over
must(syscall.Chroot(“/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs”))
must(syscall.Chdir(“/”))
// Parameters to this syscall.Mount() are:
// source FS, target FS, type of the FS, flags and data to be written in the FS
must(syscall.Mount(“proc”, “proc”, “proc”, 0, “”))
must(cmd.Run())
// Very important to unmount in the end before exiting
must(syscall.Unmount(“/proc”, 0))
}
You can think of syscall.Mount() and syscall.Unmount() as the functions that are called when you plug-in and safely remove a pen-drive. In the same way, we mount and unmount our /proc file system in our container.
After all these efforts, now if we run ps from our container, we can finally see that we have PID 1! This means that we have finally achieved process isolation. We can see that our /proc file system has been mounted by doing ls /proc, which lists the current process information of our container.
One small thing that we need to check is to see the mount points of proc. We will do that by first running mount | grep proc from our host OS. We will then launch our container and run the same command again. With our container still running, we will once again run mount | grep proc to check the mount points of proc.
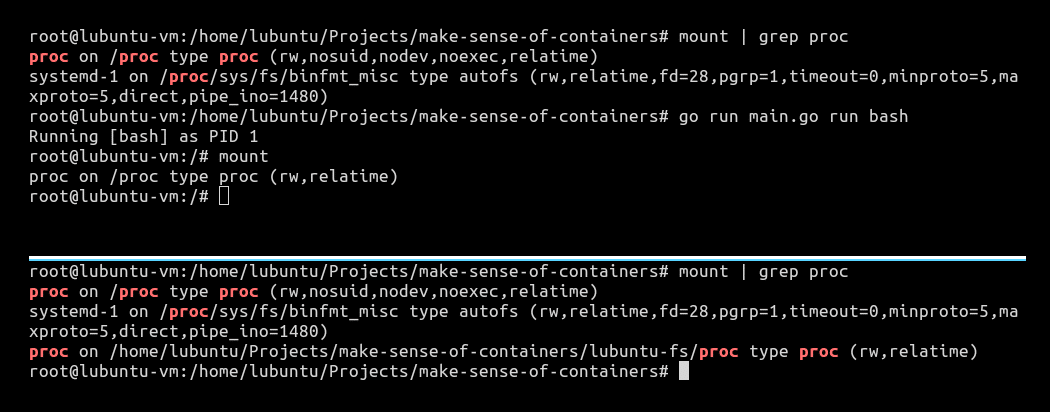
As we can see in Figure 3, if we run mount | grep proc from our host operating system (OS) with our container running, the host OS can see where proc is mounted in our container. This should not be the case. Ideally, our containers should be as transparent to the host OS as possible. To fix this, all we need to do is to add MNT namespace to our script:
func run() {
// Stuff we previously went over
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
Now if we observe the mount points from our host OS with the container running by using mount | grep proc again, we can see that our container’s mount point is invisible to our host OS.
We can now say that we have a truly isolated environment. We can also assign our container some arbitrary hostname, just so that there is a better distinction between our host and our containerised environments.
func child() {
// Stuff that we previously went over
must(syscall.Sethostname([]byte(“container”)))
must(syscall.Chroot(“/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs”))
must(syscall.Chdir(“/”))
must(syscall.Mount(“proc”, “proc”, “proc”, 0, “”))
must(cmd.Run())
must(syscall.Unmount(“/proc”, 0))
}
Running it gives the output as can be seen in Figure 4.

This gives us a fully running, fully functioning container!
There is, however, one more important concept that we haven’t covered yet. While namespaces provide isolation and layered file systems provide us with a root file system for our container, we need Cgroups for resource sharing.
Cgroups
Cgroups, also known as ‘Control Groups’ and previously referred to as ‘Process Groups’, are perhaps one of Google’s most prominent contributions to the software world. Fundamentally, Cgroups collect a set of processes or task ids together and apply limits to them. While namespaces isolate processes, Cgroups enforce resource sharing between processes.
Just like /proc, Cgroups too are exposed by the kernel as a special file system that we can mount. We add a process or thread to a Cgroup by simply adding process ids to a tasks file, and then read and configure various values by essentially editing files in that directory.
func cg() {
// Location of the Cgroups filesystem
cgroups := “/sys/fs/cgroup/”
pids := filepath.Join(cgroups, “pids”)
// Creating a directory named ‘pratikms’ inside ‘/sys/fs/cgroup/pids’
// We will use this directory to configure various parameters for resource sharing by our container
err := os.Mkdir(filepath.Join(pids, “pratikms”), 0755)
if err != nil && !os.IsExist(err) {
panic(err)
}
// Allow a maximum of 20 processes to be run in our container
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/pids.max”), []byte(“20”), 0700))
// Remove the new cgroup after container exits
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/notify_on_release”), []byte(“1”), 0700))
// Add our current PID to cgroup processes
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/cgroup.procs”), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func child() {
fmt.Printf(“Running %v as PID %d\n”, os.Args[2:], os.Getpid())
// Invoke cgroups
cg()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
// Stuff that we previously went over
must(syscall.Unmount(“/proc”, 0))
}
On running our container, we can see the directory ‘pratikms’ created inside /sys/fs/cgroup from our host. It has all the necessary files in it to control resource sharing within our container.
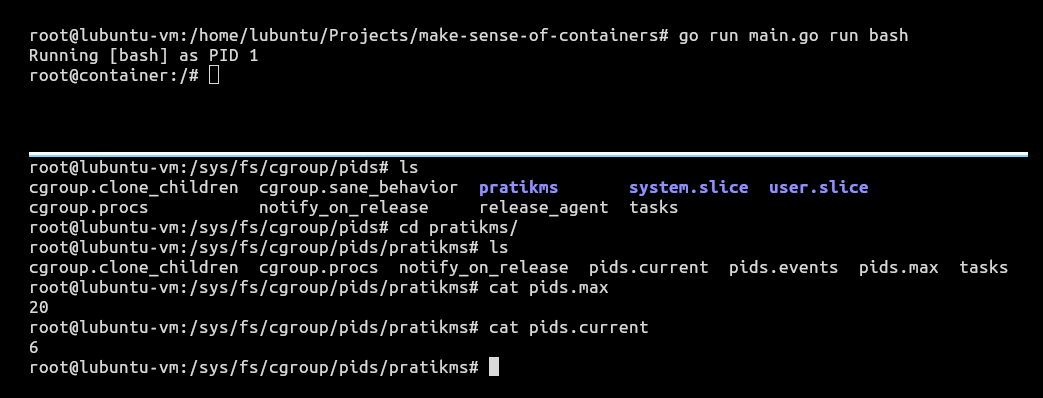
When we cat pids.max from our host, we can see in Figure 5 that our container is limited to running a maximum of 20 processes at a time. If we cat pids.current, we can see the number of processes currently running in our container. Now, we need to test the resource limitation that we applied on our container.
:() { : | : & }; :
No, this is not a typo. Neither did you read it wrong. It is essentially a fork bomb. A fork bomb is a denial-of-service attack wherein a process continuously replicates itself to deplete available system resources, slowing down or crashing the system due to resource starvation.
To make more sense of it, you can literally replace the ‘:’ in it with anything. For example, :() { : | : & }; : can also be written as forkBomb() { forkBomb | forkBomb &}; forkBomb. It means that we’re declaring a function forkBomb(), the body of which recursively calls itself with forkBomb | forkBomb and runs it in the background using &. Finally, we call it using forkBomb. While this works, a fork bomb is conventionally written as :() { : | : & }; :, and that is what we will proceed with.
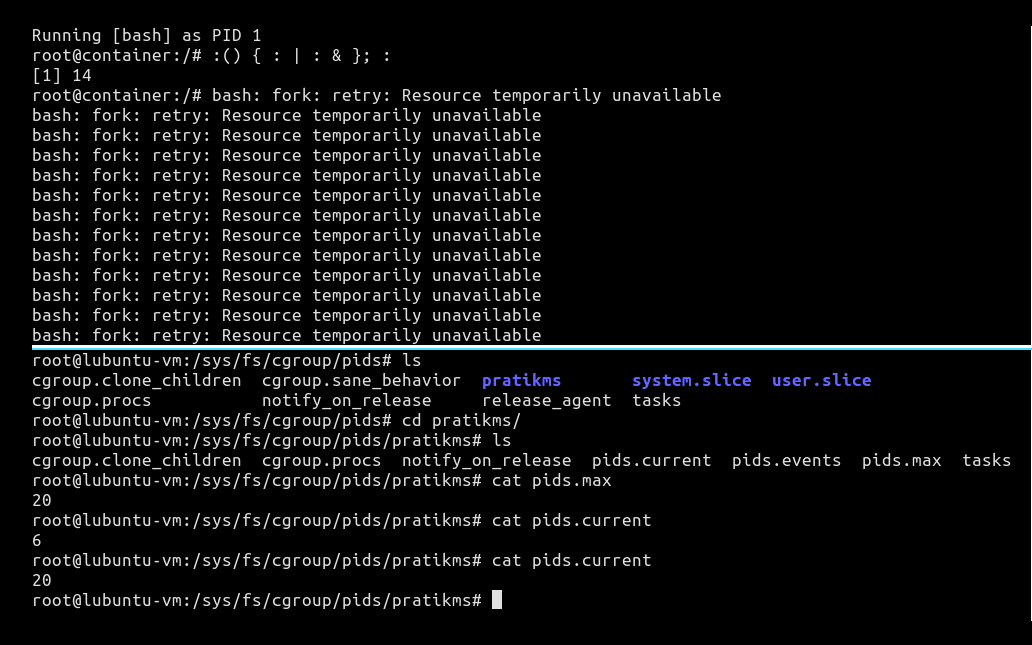
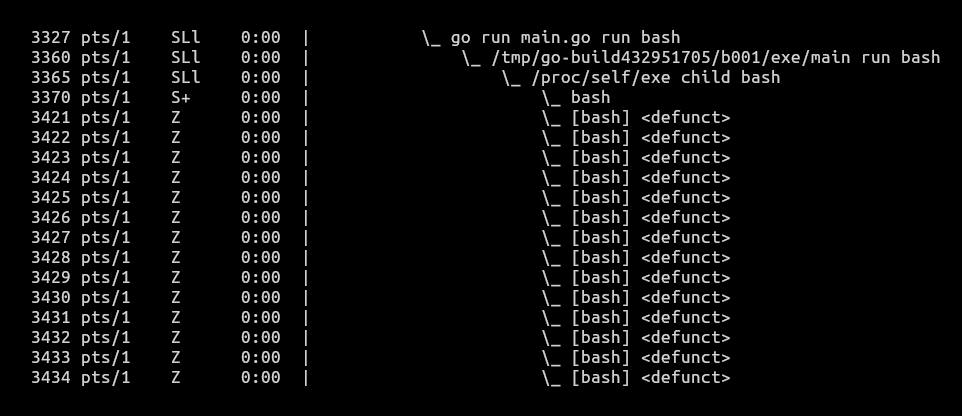
As we can see in Figure 6, the current number of processes running within our container were six. After we triggered the fork bomb, the current number of running processes increased to 20 and remained stable there. We can confirm the forks by observing the output of ps fax in Figure 7.
Putting it all together
So here it is — a super simple container, in less than 100 lines of code. Obviously, this is simple. If you use it in production, you are crazy and, more importantly, on your own. But I think seeing something simple will give you a really useful picture of what’s going on. In case you missed anything from the first part of this two-part series, this code snippet can serve as a reference.
package main
import (
“fmt”
“io/ioutil”
“os”
“os/exec”
“path/filepath”
“strconv”
“syscall”
)
func must(err error) {
if err != nil {
panic(err)
}
}
func cg() {
cgroups := “/sys/fs/cgroup/”
pids := filepath.Join(cgroups, “pids”)
err := os.Mkdir(filepath.Join(pids, “pratikms”), 0755)
if err != nil && !os.IsExist(err) {
panic(err)
}
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/pids.max”), []byte(“20”), 0700))
// Remove the new cgroup after container exits
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/notify_on_release”), []byte(“1”), 0700))
must(ioutil.WriteFile(filepath.Join(pids, “pratikms/cgroup.procs”), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func child() {
fmt.Printf(“Running %v as PID %d\n”, os.Args[2:], os.Getpid())
cg()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte(“container”)))
must(syscall.Chroot(“/home/lubuntu/Projects/make-sense-of-containers/lubuntu-fs”))
must(syscall.Chdir(“/”))
must(syscall.Mount(“proc”, “proc”, “proc”, 0, “”))
must(cmd.Run())
must(syscall.Unmount(“/proc”, 0))
}
func run() {
cmd := exec.Command(“/proc/self/exe”, append([]string{“child”}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func main() {
switch os.Args[1] {
case “run”:
run()
case “child”:
child()
default:
panic(“I’m sorry, what?”)
}
}
Again, as stated before, this is in no way a production-ready code. I do have some hard-coded values in it, like the value of the path to the file system, and also the hostname of the container.
If you wish to play around with the code, you can get it from my GitHub repo (https://github.com/pratikms/demystifying-containers). But, at the same time, I do believe this is a wonderful exercise to understand what goes on behind the scenes when we run that docker run <image> command in our terminal. It introduces us to some of the important OS concepts that containers generally leverage, like namespaces, layered file systems, Cgroups, etc.
Containers are important – and their prevalence in the job market is incredible. With cloud, Docker and Kubernetes getting closer with each new day, the demand for containers will only grow.
Going forward, it will be imperative to understand the inner workings of a container. With this knowledge, we can attempt to look at the magic that goes on in a container orchestrator like Kubernetes. But that’s for a different article!

















{kind=link}