





























































Spark SQL is the module in the Spark ecosystem that processes data in a structured format. It internally uses the Spark Core API for its process, but the usage is abstracted from the user. This article dives a little deeper and tells you what’s new in Spark SQL 3.x.
with Spark SQL, users can also write SQL-styled queries. This is essentially helpful for the wide user community that is proficient in structured query language or SQL. Users will also be able to write interactive and ad hoc queries on the structured data. Spark SQL bridges the gap between resilient distributed data sets (RDDs) and relational tables. An RDD is the fundamental data structure of Spark. It stores data as distributed objects across a cluster of nodes suitable for parallel processing. RDDs are good for low-level processing, but are difficult to debug during runtime and programmers cannot automatically infer schema. Also, there is no built-in optimisation for RDDs. Spark SQL provides the DataFrames and data sets to address these issues.
Spark SQL can use the existing Hive metastore, SerDes, and UDFs. It can connect to existing BI tools using JDBC/ODBC.
Data sources
Big Data processing often needs the ability to process different file types and data sources (relational and non-relational). Spark SQL supports a unified DataFrame interface to process different types of sources, as given below.
Files
- CSV
- Text
- JSON
- XML
JDBC/ODBC
- MySQL
- Oracle
- Postgres
Files with schema
- AVRO
- Parquet
Hive tables
- Spark SQL also supports reading and writing data stored in Apache Hive.
With DataFrame, users can seamlessly read these diversified data sources and do transformations/joins on them.
What’s new in Spark SQL 3.x
In the previous releases (Spark 2.x), the query plans were based on heuristics rules and cost estimation. The process from parsing to logical and physical query planning, and finally to optimisation was sequential. These releases had little visibility into the runtime characteristics of transformations and actions. Hence, the query plan was suboptimal because of the following reasons:
- Missing and outdated statistics
- Suboptimal heuristics
- Wrong estimation of costs
Spark 3.x has enhanced this process by using runtime data for iteratively improving the query planning and optimisation. The runtime statistics of a prior stage are used to optimise the query plan for subsequent stages. There is a feedback loop that helps to re-plan and re-optimise the execution plan.
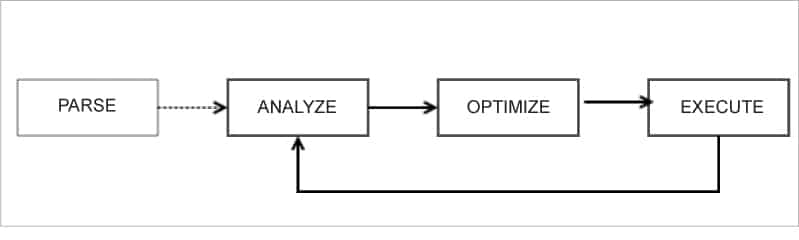
Adaptive query execution (AQE): The query is changed to a logical plan and finally to a physical plan. The concept here is ‘reoptimisation’. It takes the data available during the prior stage and reoptimises for subsequent stages. Because of this, the overall query execution is much faster.
AQE can be enabled by setting the SQL configuration, as given below (default false in Spark 3.0):
spark.conf.set(“spark.sql.adaptive.enabled”,true)
Dynamically coalescing shuffle partitions: Spark determines the optimum number of partitions after a shuffle operation. With AQE, Spark uses the default number of partitions, which is 200. This can be enabled by the configuration:
spark.conf.set(“spark.sql.adaptive.coalescePartitions.enabled”,true)
Dynamically switching join strategies: Broadcast Hash is the best join operation. If one of the data sets is small, Spark can dynamically switch to Broadcast join instead of shuffling large amounts of data across the network.
Dynamically optimising skew joins: If the data dispersion is not uniform, data will be skewed and there will be a few large partitions. These partitions take up a lot of time. Spark 3.x optimises this by splitting the large partitions into multiple small partitions. This can be enabled by setting:
spark.conf.set(“spark.sql.adaptive.skewJoin.enabled”,true)
Other enhancements
In addition, Spark SQL 3.x supports the following.
Dynamic partition pruning: 3.x will only read the partitions that are relevant based on the values from one of the tables. This eliminates the need to parse the big tables.
Join hints: This allows users to specify the join strategy to be used if the user has knowledge of the data. This enhances the query execution process.
ANSI SQL compliant: In the earlier versions of Spark, which are Hive compliant, we could use certain keywords in the query which would work perfectly fine. However, this is not allowed in Spark SQL 3, which has full ANSI SQL support. For example, ‘cast a string to integer’ will throw runtime exception. It also supports reserved keywords.
Newer Hadoop, Java and Scala versions: From Spark 3.0 onwards, Java 11 and Scala 2.12 are supported. Java 11 has better native coordination and garbage correction, which results in better performance. Scala 2.12 exploits new features of Java 8 and is better than 2.11.
Spark 3.x has provided these useful features off-the-shelf instead of developers worrying about them. This will improve the overall performance of Spark significantly.


















{kind=link}