






























































GitOps leverages Git’s strengths to achieve reliable, automated, and consistent infrastructure and application management, making it well-suited for modern DevOps practices and containerised environments like Kubernetes.
Kubernetes is an open source container orchestration platform that automates the deployment, scaling, and management of containerised applications. It provides a powerful and flexible solution for managing containerised workloads in a highly efficient and scalable manner.
Kubernetes plays a central role in modern cloud-native application development and has become the de facto standard for container orchestration due to its powerful features, scalability, and wide adoption within the industry.
Key features of Kubernetes
Here are the key features that distinguish the versatility of this platform.
Container orchestration: Kubernetes manages the deployment and operation of containers, allowing developers to focus on application logic rather than infrastructure details.
Automatic scaling: Kubernetes can automatically scale the number of container replicas based on defined resource utilisation metrics, ensuring applications are highly available and can handle varying loads.
Service discovery and load balancing: Kubernetes provides built-in service discovery and load balancing mechanisms, making it easy for containers to communicate with each other and distribute incoming traffic.
Self-healing: Kubernetes continuously monitors the health of containers and can automatically restart or replace unhealthy containers to maintain application availability.
Rollouts and rollbacks: Kubernetes supports rolling updates, enabling seamless application updates without downtime. It also allows easy rollbacks to a previous version in case of issues.
Storage orchestration: Kubernetes manages persistent storage for containers, enabling applications to store and access data that persists across container restarts.
Configurations and secrets management: Kubernetes allows you to define configuration data and secrets separately from the application code, promoting security and easy management.
Horizontal and vertical scaling: Kubernetes supports both horizontal scaling (increasing the number of replicas) and vertical scaling (increasing container resources like CPU and memory) to meet varying workload demands.
Batch processing and Cron jobs: Kubernetes provides support for batch processing workloads and scheduling periodic jobs using Cron expressions.
Multi-cloud and on-premises support: Kubernetes is cloud-agnostic and can run on various cloud providers as well as on-premises data centres.
Architecture of Kubernetes
Understanding the architectural foundation of the Kubernetes platform is essential for harnessing its full potential in orchestrating modern applications.
Master node: The control plane consists of several components running on the master node, including the API server, etcd (key-value store), controller manager, and scheduler. The master node manages the overall state of the cluster and makes decisions about scheduling, scaling, and maintaining desired state.
Worker nodes: Worker nodes are the worker machines responsible for running containers. Each worker node runs a container runtime (e.g., Docker), and the Kubernetes agent called kubelet, which communicates with the master node.
Pods: The smallest deployable units in Kubernetes are pods. A pod can contain one or more tightly coupled containers sharing the same network name space and volumes.
Services: Services provide stable endpoints to access pods and enable load balancing across replicas of an application.
Deployments and ReplicaSets: Deployments and ReplicaSets are used to manage the life cycle of pods, ensuring a specified number of replicas are running and enabling updates and rollbacks.
Deploying applications in Kubernetes
Each application deployment has specific requirements, such as configuring environment variables, setting resource limits, and handling dependencies. Kubernetes offers a flexible and robust platform to manage a variety of containerised applications, making it suitable for various use cases, from microservices to large-scale applications.
Deploying applications in Kubernetes involves several steps to ensure that your containerised applications are up and running in the cluster. Here’s a high-level overview of the process.
Containerise your application: The first step is to package your application into a container image. This typically involves writing a Dockerfile that specifies the application’s runtime environment and dependencies.
Build and push the container image: Once the Dockerfile is ready, you build the container image using a container runtime like Docker. After building, you push the image to a container registry like Docker Hub, Google Container Registry, or Amazon Elastic Container Registry (ECR).
Create Kubernetes manifests: Kubernetes uses YAML files called manifests to define the desired state of your application. Manifests include details such as the container image, resource requirements, environment variables, networking, and more.
Deployments or StatefulSets: To manage your application’s replicas, you can use either deployments (for stateless applications) or StatefulSets (for stateful applications that require stable network identities).
Services: To expose your application to the network and enable load balancing, you create a Kubernetes service. The service provides a stable IP address and DNS name for your application.
Persistent storage (if needed): If your application requires persistent storage, you can define PersistentVolumeClaims (PVCs) and PersistentVolumes (PVs) to provide durable storage to your application.
Namespaces: Namespaces allow you to logically divide your cluster, isolating different applications and teams from each other.
Apply manifests to the cluster: Once your manifests are ready, you apply them to the Kubernetes cluster using the ‘kubectl apply’ command or through a CI/CD pipeline.
Monitoring and observability: Set up monitoring and logging solutions to track the health and performance of your applications in the cluster. Popular tools include Prometheus, Grafana, and ELK stack.
Continuous deployment (optional): Implement a CI/CD pipeline to automate the deployment process, allowing changes to be automatically rolled out to the cluster when code is pushed or merged.
Testing and validation: Before deploying to production, thoroughly test your application in staging or testing environments to catch any potential issues.
Scaling and updating: Kubernetes provides mechanisms to scale your application based on demand, as well as rolling updates and rollbacks for seamless application updates.
Pain points in Kubernetes deployment
Kubernetes deployments can encounter several challenges and complexities that may lead to operational inefficiencies and increased risks.
Manual configuration management: Kubernetes configurations, such as YAML files describing pods, services, and deployments, are typically managed manually. This manual approach can lead to human errors, configuration drift, and inconsistencies between environments.
Lack of version control: Traditional Kubernetes configurations might not be stored in version control systems like Git, making it difficult to track changes, collaborate effectively, and roll back to previous configurations if issues occur.
Inefficient deployment process: The absence of automation can result in slower and error-prone deployment processes. Manually applying changes to Kubernetes clusters can be time-consuming and increase the likelihood of misconfigurations.
Difficulty in auditing and compliance: Without version control and proper tracking, it becomes challenging to maintain an audit trail of changes made to the Kubernetes infrastructure.
Limited collaboration: In team environments, collaboration between developers and operations personnel can be challenging when managing Kubernetes configurations manually. Communication gaps and misunderstandings may occur.
Complex rollbacks: Rolling back changes to a previous stable state can be a complex and manual process, potentially leading to downtime and service disruptions.
Inconsistent environments: Manually managing configurations for different environments (e.g., development, staging, production) can result in inconsistencies, leading to unexpected behaviour and making it harder to test and reproduce issues.
Security vulnerabilities: Manually applying changes to Kubernetes may increase the risk of security vulnerabilities, especially if there are deviations from best practices or if proper access controls are not enforced.
DevOps bottlenecks: Without automation, development teams might rely heavily on operations personnel to manage deployments and configurations, leading to DevOps bottlenecks and slower delivery cycles.
Scalability challenges: As Kubernetes clusters and applications grow in complexity, manual management becomes less scalable and may hinder efficient scaling and maintenance of the infrastructure.
Let us look at how to mitigate these challenges and promote streamlined, collaborative, and secure operational workflow that aligns well with modern DevOps practices and containerised environments.
GitOps
GitOps is a modern software development and operations approach that uses version control systems, typically Git, as the single source of truth for managing infrastructure and application configurations. The core idea behind GitOps is to treat the entire system as code and use Git workflows to automate the deployment and management of applications in a containerised environment, such as Kubernetes.
Key principles of GitOps
Here we explore how GitOps leverages version control for automated and declarative management, bringing simplicity and efficiency to modern software workflows.
Declarative infrastructure as code: In GitOps, all aspects of infrastructure and application configurations are defined declaratively in code, specifying the desired state of your system rather than writing imperative commands to achieve that state.
Git as source of truth: Git is used as the central repository to store the desired state of the system. Any changes to the infrastructure or application configurations must be made through commits to the Git repository.
Continuous deployment and automation: GitOps workflow emphasises continuous deployment and automation. Changes made to the Git repository trigger automated processes and apply those changes to the target environment.
Reconciliation loop: GitOps employs a reconciliation loop to ensure that the actual state of the system matches the desired state defined in the Git repository. If any deviations are detected, the system automatically makes corrections to bring itself back to the desired state.
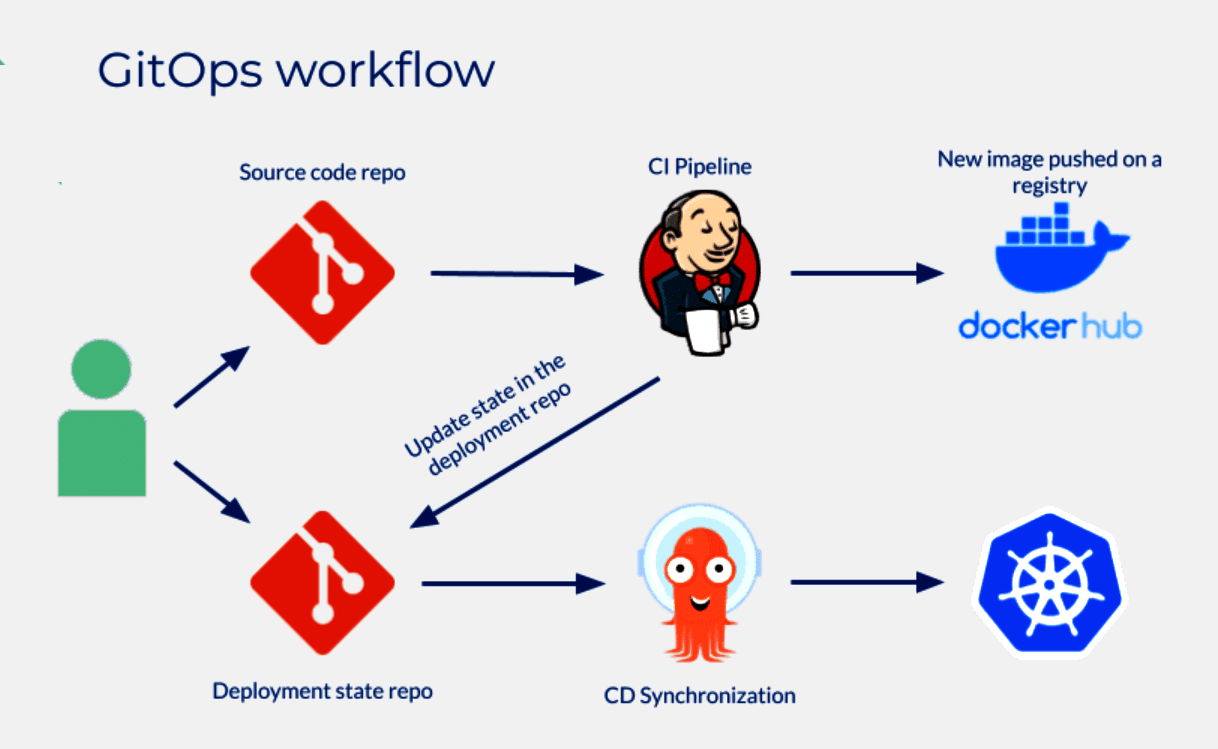
How GitOps works
The GitOps workflow typically involves these steps for seamless orchestration.
a. Desired state in Git: Developers define the desired state of the infrastructure and applications in Git repositories as code. This includes Kubernetes manifest files, application configurations, and other related resources.
b. Git repository as source of truth: The Git repository becomes the source of truth for the entire system. Any changes to the system should be made through Git commits.
c. Continuous deployment: A GitOps operator or tool (e.g., Flux, Argo CD) watches the Git repository for changes. When changes are detected, the operator applies those changes to the Kubernetes cluster automatically.
d. Reconciliation loop: The GitOps operator continuously reconciles the actual state of the cluster with the desired state defined in the Git repository. If any drift is detected, it brings the cluster back to the desired state by applying the necessary changes.
Benefits of GitOps
Embracing GitOps empowers modern teams to achieve greater efficiency and reliability in their software delivery processes.
Simplified operations: GitOps simplifies the deployment and management of applications by using familiar Git workflows, reducing the need for complex manual operations.
Consistency and reproducibility: By managing configurations as code in Git, GitOps ensures that the same configuration used in development is applied to staging and production environments, leading to consistency and reproducibility.
Version control and collaboration: Git provides version control, enabling teams to collaborate effectively, review changes, and maintain a history of system modifications.
Automated auditing and compliance: GitOps enables easier auditing and compliance tracking since all changes are recorded in Git repositories.
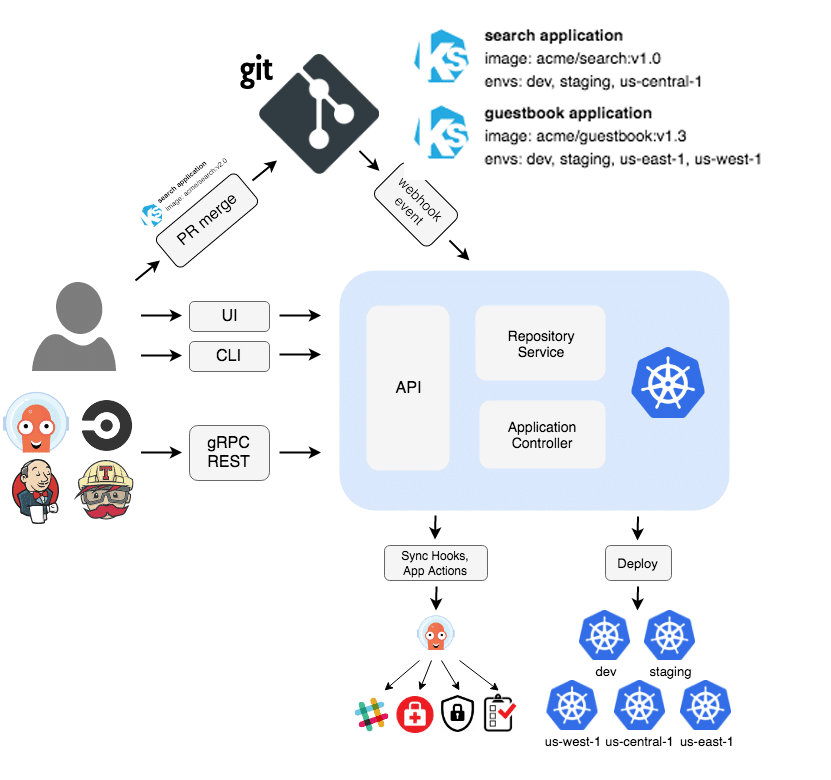
GitOps tools
GitOps tools provide continuous delivery and deployment and adhere to the GitOps approach, where the desired state of the infrastructure and applications is version-controlled in Git repositories. These tools continuously monitor the repositories for changes and automatically apply those changes to the target environment, typically a Kubernetes cluster. Though several open source tools like Jenkins-x, Spinnaker, Kustomize and GitLab are available, we will quickly look into the workings of two widely adopted tools — Argo CD and Flux.
Argo CD
Argo CD is an open source continuous delivery tool that provides a powerful and efficient way to manage Kubernetes applications, offering automated continuous delivery and the benefits of the GitOps workflow that runs on top of Kubernetes.
With Argo CD, you can define your application configurations declaratively in Git repositories and have Argo CD automatically reconcile the state of your applications to match the desired state defined in those repositories. It is widely adopted by organisations looking to simplify application deployments, reduce manual interventions, and improve the overall reliability of their Kubernetes environments.
How to Argo CD Works
Application definition: You define your application specifications, including the deployment manifests, service configurations, and any other required resources, in a Git repository.
Argo CD server: The Argo CD server continuously monitors the Git repository for changes. When a change is detected, the server initiates a reconciliation process.
Reconciliation: During reconciliation, Argo CD compares the desired state in the Git repository with the actual state in the Kubernetes cluster. If there are differences, Argo CD makes the necessary changes to bring the cluster in line with the desired state.
Application deployment: Argo CD deploys and manages your applications using Kubernetes manifests, Helm charts, or other supported application definition formats.
Application synchronisation: Argo CD keeps the applications continuously synchronised with the Git repository. Any changes made directly to the cluster are automatically reverted, ensuring that the desired state remains consistent.
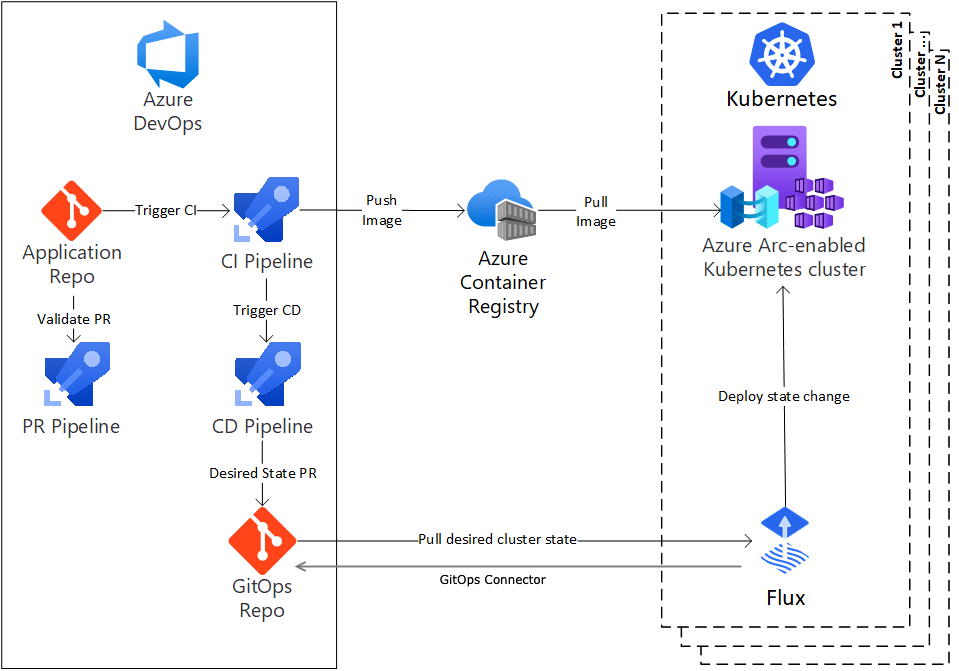
Flux
Flux is an open source continuous delivery tool that follows the GitOps approach to automate the deployment and management of applications in Kubernetes. Similar to Argo CD, Flux uses Git as the single source of truth for defining the desired state of applications and infrastructure configurations. It continuously monitors Git repositories and automatically synchronises the Kubernetes cluster with the configurations defined in those repositories.
How Flux works
Application definitions: You define the desired state of your applications and infrastructure configurations in a Git repository using Kubernetes manifests or Helm charts.
Flux controller: The Flux controller continuously monitors the Git repository for changes. It checks for new commits and updates to the defined configurations.
Reconciliation: When changes are detected, the Flux controller initiates a reconciliation process. It compares the cluster’s actual state with the desired state defined in the Git repository.
Automated deployment: Flux automatically applies the changes to the cluster, deploying and managing applications based on the configurations defined in Git.
Synchronisation: Flux keeps the cluster continuously synchronised with the Git repository. Any changes made directly to the cluster are reverted during the next synchronisation to ensure that the cluster remains in sync with the desired state.
Both Argo CD and Flux provide support for Helm charts, allowing you to deploy Helm releases using the CI/CD pipeline. Additionally, you can set up custom policies in both tools to define the automated deployment behaviour, such as automated vs manual deployments and strategies for updating application versions.
It’s essential to secure access to the Kubernetes cluster and the Git repository to prevent unauthorised changes. By integrating Argo CD or Flux with your CI/CD pipeline, you can establish a robust and automated GitOps-based workflow for deploying applications and configurations to your Kubernetes cluster with ease.
Disclaimer: This article expresses the views of the author and not of the organisation he works in.


















{kind=link}