






























































Computer vision tasks include methods for acquiring, processing, analysing and understanding digital images, and in general, deal with the extraction of multi-dimensional data from the real world in order to produce numerical or symbolic information.
Computer vision (CV) is a discipline that relates to the visual perception and analysis of computers and cameras. The visual input method for computers is a camera. A majority of all computer vision algorithms focus on extrapolating interesting features from images/videos that are captured by a camera. This field has many applications in the field of robotics. For example, the preliminary versions of Stanford University’s Stanley (a self-driving car) used a pair of stereo cameras for visual perception.
Technology today is shifting to a more cloud and Internet oriented setting. Traditional software is being replaced by Web apps. If eventually, everything is going to be ported to a Web platform, it would be wise to start incorporating the Web into upcoming technologies. Similarly, one could think of shifting CV to a browser platform as well. In fact, there are various libraries that provide browser based support for computer vision. These include Tracking.js. First, let it be clear that a browser based system for this article refers to front-end code only, involving just HTML5, CSS, and JavaScript.


Basic computer vision and the browser
Computations are carried out upon images, with the fundamental unit being a pixel. Algorithms involve mathematical operations on a pixel or a group of pixels. This article addresses a few hackneyed CV algorithms and their ports to a front-end system. To start with, basic concepts like images and canvas are to be understood first.
An HTML image element refers to the ‘<img></img>’ tag. It is, essentially, adding an image to a Web page. Similarly, to process or display any graphical units, the ‘<canvas></canvas>’ element is used. Each of these elements has attributes such as height, width, etc, and is referred to via an ID. The computation part is done using JavaScript (JS). A JS file can be included either at the head or body of an HTML document. It contains functions that will implement the aforementioned operations. For drawing any content upon a canvas, a 2D rendering reference called context is supposed to be made.
Here’s how to access images, as well as canvas and context, from JS:
//getting image, canvas and context var im = document.getElementById(“image_id”); var canvas = document.getElementById(“canvas_id”); var context = canvas.getContext(“2d”); //accessing a rectangular set of pixels through context interface var pixel = context.getImageData(x, y, width, height); //displaying image data context.putImageData(image, start_point_x, start_point_y);
Using a local Web cam from a browser
Accessing a Web cam from the browser first requires user consent. Local files with a URL pattern such as file:/// are not allowed. Regular https:// URLs are permitted to access media.
Whenever this feature is executed, the user’s consent will be required. Any image or video captured by a camera is essentially media. Hence, there has to be a media object to set up, initialise and handle any data received by the Web cam. This ability of seamless integration is due to media APIs provided by the browser.
To access the Web cam with a media API, use this code:
navigator.getUserMedia = ( navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia );
In the above code, navigator.getUserMedia will be set if the media exists. To get control of media (refers to camera), use the following code:
navigator.getUserMedia({
video: true
},handle_video, report_error );
On the successful reception of a frame, the handle_video handler is called. In case of any error, report_error is called.
To display a frame, use the following code:
var video_frame = document.getElementById(“myVideo”); video_frame.src = window.URL.createObjectURL(stream); //stream is a default parameter //provided to handle_video
For further details, regarding a camera interfacing with the browser, refer to https://github.com/kushalvyas/trackingjs_ofy/.

The basic image processing algorithms
JS stores an image as a linear array in RGBA format. Each image can be split into its respective channels, as shown below:
var image = context.getImageData(0, 0, canvas.width, canvas.height);
var channels == image.data.length/4;
for(var i=0;i<channels;i++){
var red_component_pixel = image.data[i*4 + 0];
var green_component_pixel = image.data[i*4 + 1];
var blue_component_pixel = image.data[i*4 + 2];
}
Computation of gray scale images
A gray scale image is one in which all colour components are normalised to have equal weightage. If an 8-bit image is considered, the colour gray is obtained when the number of RGB bits equals 1.
To solve this, there is a simple formula, which creates a weighted sum of pixel values to yield a gray image:
gray[pixel] = 0.21*red_component_pixel + 0.72*green_component_pixel + 0.07*blue_component_pixel'
On applying the above formula to each pixel, split into its components, one gets an equivalent gray pixel.
Computation of binary and inverted images
A binary image is in black and white (BW). The conversion of an image from colour to BW is done through a process called thresholding, which classifies each pixel as white or black based on its value. If the value is greater than a particular threshold, it will be set to 255, else 0.
if(red_component_pixel > threshold_red &&
green_component_pixel > threshold_green &&
blue_component_pixel > threshold_blue){
//make pixel == white
image.data[pixel] = 255;
}else{ image.data[pixel] = 0; }
Just as we have negatives for a photograph, similarly, the inversion of colour space of any image converts all pixels into a negative. This can simply be done by subtracting each pixel value from 255.

The tracking.js library
According to GitHub, tracking.js is a lightweight JS library that offers a variety of computer vision algorithms with HTML5 and JS. Some algorithms implemented here are for colour tracking, face detection, feature descriptors and the other utility functions. To set up tracking.js for your Web page, include build/tracking.js inside your ‘<head>’. For more details, one can visit tracking.js documentation. It is highly detailed and illustrated.
Colour tracker using tracking.js: To initialise a colour tracker, first use the following commands:
var myTracker = new tracking.ColorTracker(['yellow']); myTracker.on(“track”, color_tracking_callback); var mT = tracking.track(“#myVideo”, myTracker);
In the above code snippet, color_tracking_callback is a callback which will receive a list of all possible locations where the given colour is present. Each location is a rectangle object, comprising attributes which are ‘x, y, width and height’. x and y are the starting points of the rectangle.
The natural action for tracking is to make a bounding box around the region we are interested in. Therefore, the boundingBox function plots a rectangle around the region of interest. Context variable is used here to perform any canvas drawing methods. context.stroke() eventually prints it on the canvas.
function color_tracking_callback(list_rect){
list_rect.data.forEach(drawBoundingBox);
}
function drawBoundingBox(rect){
context.beginPath();
context.strokeStyle = “red”;
context.lineWidth = “2”;
context.rect(rect.x, rect.y, rect.width, rect.height);
context.stroke();
}
Starting and pausing the tracking process
To start the tracking process, tracking.js provides a call to start( ) and stop( ) methods.
mT.stop(); //to stop tracking mT.start(); //to start tracking
Setting up custom colours for tracking
As seen, the input to a colour tracker is a list of probable colours (e.g., [yellow]). As the definition suggests, a colour tracker must be able to track colours. Tracking.js provides a method registerColor that handles user-specified custom colours.
tracking.ColorTracker.registerColor('<color_name>' , callback_color);
The =callback_color callback will have input arguments as red, blue and green values. Since this is a custom colour, one has to define the RGB ranges. If the RGB argument meets the range, the function returns true, else it’ll return false.
function callback_color(r , g, b){
if(r > r_low && r < r_high && g > g_low && g < g_high && b > b_low && b < b_high){
return true;
}
return false;
}
Here, r_low, r_high, etc, refer to the lower and upper bounds of the threshold values, respectively. Having registered the colour, one can simply append color_name to color_list in tracking.ColorTracker (color_list).
Face tagging using tracking.js
Facebook has this feature whereby one can tag one’s friends. There are different sets of mathematical frameworks developed to perform visual recognition as well as detection, of which one of the most robust options is the Viola-Jones Detection framework.
A brief introduction to Viola Jones: Each human face has multiple features, with many significant discernible visual differences which are the inputs that help in face recognition. These are known as Haar Cascades (which you can look up in /src/detection/training/haar). Examples for significant variations in facial features include:
- Location of the eyes and nose
- Size of the eyes, nose, etc
- Mutual contrast between facial features
By training over such features, the detection framework is made to locate areas of an image containing regions that satisfy the above constraints, thereby aiding in face detection.
To integrate your front-end with face recognition, tracking.js provides another script located in build/data/face-min.js. This basically loads the Viola Jones parameters over trained data, including face-min.js as well as tracking.min.js files.
To initialise and use the face tracker, type:
var face_tracker = new tracking.ObjectTracker(“face”);
face_tracker.setInitialScale(param_for_block_scaling);
face_tracker.setEdgesDensity(classifier_param_for_edges_inside_block);
face_tracker.setStepSize(block_step_size);
var mTracker = tracking.track("#myVideo", face_tracker, {camera:'true'});
face_tracker.on("track", handle_faces);
The function handle_faces is a callback fired for handling detected regions. As mentioned earlier, tracking.js returns a list containing Rect objects. In the application discussed, the detected faces will be tagged via a JavaScript prompt. Once the prompt value is taken, the face is identified and tracked with the given name as well as indexed for UI purposes. The complete code can be obtained at //githublink. If the face is detected initially, or there is a state change of tracking (stop/start), the prompt is re-called and the data is stored within an array. For tracking purposes, each newly obtained Rect object is compared with the previously recorded nearset face. Comparison is based on the minimum Euclidean distance. If not returned, then it is recalculated.
Features extraction and matching
In simple terms, any significant discernible parts of the image can be defined as a feature. These can be corner points, edges or even a group of vectors oriented independently. The process of extracting such information is called feature extraction. Various implementations exist for feature extraction and descriptors, such as SIFT, SURF (feature descriptors) and FAST (corner detection). Tracking.js implements BRIEF (Binary Robust Independent Elementary Features) and FAST (Features from Accelerated Segmentation Test). Input to the system is first a gray image. The following code extracts corner points (points of interest) based on FAST.
var gray = tracking.Image.grayscale(input_image, width, height); var corners = tracking.Fast.findCorners(gray, width, height);
Each feature point can be referred to as a location. But to be able to perform any operations, these locations are converted into descriptors, which can be considered as a list of vectors that define a given feature. Comparison operators are applied upon these vectors. To find descriptors, tracking.js uses the BRIEF framework to extrapolate descriptor vectors from given feature points.
var descriptors = tracking.Brief.getDescriptors(gray, width, corners);
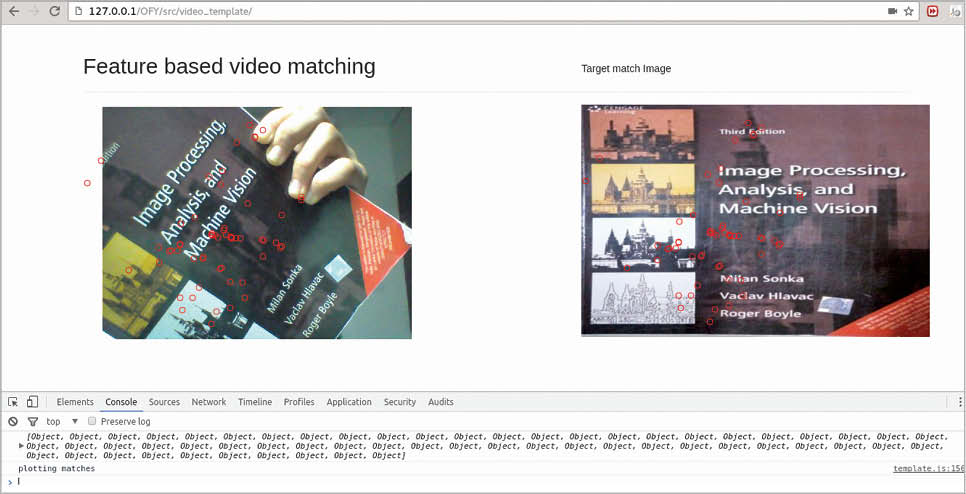
Having got the points of interest from an image as well as their descriptors, we can design a scenario wherein one can track based on templates. Given a video frame and a fixed image, features can be used to match and identify where the fixed image can be located. However, there can be false positives.
var matches = tracking.Brief.reciprocalMatch(corner_scene, descriptor_scene ,corner_target, descriptor_target);
// calculates the matching points between the scene and the target image.
matches.sort(function(a, b){
//matches can be further filtered by using a sorting functin
// Either sort according to number of matches found:
return b.length – a.length;
// or sort according to confidence value:
return b.confidence – a.confidence
}
The matches obtained can be sorted on the basis of their length, i.e., the number of matches obtained, and on their confidence value, as to how well the points match. Having arranged the matches, efficient matching of the target template image and the scene image can be carried out. It is simply a task of graphics now. Just iterate over the two arrays and mark the appropriate feature points on the canvas, as follows:
function plot_matches(matches){
for (var i = 0; i < matches.length; i++) {
var color = "red";
context.lineWidth = "2px";
context.fillStyle = color;
context.strokeStyle = color;
context.beginPath();
context.arc(matches[i].keypoint1[0], matches[i].keypoint1[1], 4, 0, 2*Math.PI);
context.stroke();
}
}
The above function plots the matches only for the scene image, since the reference context is made with respect to one canvas element. For plotting matches on the target template image, a context reference has to be made to its respective canvas element.
Computer vision on the front-end can be used for various applications, not only to produce various image effects but also applications like browser based gesture control, etc. The advent of JavaScript libraries has helped to make this possible. The code can be found at https://www.github.com/kushalvyas/trackingjs_ofy



















{kind=link}