





























































Lex is a computer program that generates lexical analysers. It is commonly used with the Yacc parser. Originally distributed as proprietary software, some versions of Lex are now open source.
I would like to start by saying that the creator is as important as the creation. Lex and Yacc are the creators of a compiler and an interpreter, respectively. To be specific, Lex is used in the first phase of compilation, which is called the lexical analysis phase, as a lexical analyser generator; while Yacc is used in the second, parsing phase as a parser generator. You may feel that since you are not into compilers, this article is of no use for you. Yet, if you use the pattern matching algorithm, this article will help you.
The lexical analysis phase involves the processing of words, the core of which is the identification of patterns in the input. You might have used different pattern matching algorithms. When searching for a single pattern, if we use C for the search, a nested loop containing a conditional statement may be required, though that may not be so simple. Ten patterns may need a minimum of 10 conditional statements if a simple line of code is required for checking a pattern. This is where Lex comes in with the wand of regular expressions.
Lex was developed by Mike Lesk and Eric Schmidt in 1975. According to them, Lex is a program generator designed for lexical processing of character input streams. This is done with the help of regular expressions. Lex identifies the input strings based on the regular expressions specified in the program. Sample programs in this article were run using Flex. Depending on the version used, commands and programs may vary slightly.
Installing Lex
Installation in Linux: Lex is proprietary software, though open source alternatives to it are available. Flex or fast lexical analyser is one such package. To install Flex, type the following command in the terminal:
sudo apt-get install flex
Installation in Windows: In Windows, installation is done by simply downloading the package and running the program. When you install, make sure that the package is not installed in the folder Program Files.
Regular expressions
Before going into the details of Lex, a quick overview of regular expressions is required. The name itself implies that the regularity of something can be expressed using a regular expression. Let’s suppose we have the following set of sentences:
- Sharon is 27 years old.
- Stephy is 29 years old.
- Sunny is 56 years old.
- Shyamala is 46 years old.
We can see that in all the above sentences, the first word begins with ‘S’ followed by a sequence of characters. The next word is ‘is’, then comes a two digit number which is followed by ‘years old’. This pattern can be represented using a regular expression such as:
S[a-z]+ is [0-9]{2} years old.
Here, S[a-z]+ denotes that one or more occurrences of any character from ‘a’ to ‘z’ can follow ‘S’, and [0-9]{2} represents any two-digit number. Note that blank spaces are used to separate each word in the sentences and are used similarly in the regular expression also.
According to Wikipedia, a regular expression is a sequence of characters that define a search pattern, mainly for use in pattern matching with strings, or string matching. The following are some of the notational short-hand symbols used in a regular expression:
- The ‘.’ (dot) is the wild card character that matches any single character.
- | stands for ‘or’. A|b means either A or b.
- – stands for a range of characters.
- ‘?’ is used to represent zero or one instance. ‘cars?’ can represent either car or cars.
- + represents one or more instances of an entity.
- * represents zero or more instances of an entity.
- ( ) is for grouping a sequence of characters.
- Character classes: [abc] represents a| b| c.
Given below are the rules for naming an identifier in C:: - It must begin with an underscore or an alphabet.
- It can be followed by zero or more underscores, a letter of the alphabet or a number.
We can write the regular expression as:
[a-zA-Z_]([a-zA-Z_0-9])*
Intelligent people always find easy ways to get their job done. It may be difficult to repeatedly write ‘a-zA-Z’ for letters of the alphabet. Hence, the idea emerged to give names to regular expressions that are frequently used and are lengthy.
Regular definitions allow one to give names to regular expressions. These short names help to avoid repeatedly writing lengthy regular expressions.
As an example, l -> a-zA-Z and d -> 0-9. Given this regular definition, a regular expression for identifiers can be re-written as:
( l | _)( l | d |_)*
The structure of a Lex program
To quote from the book of Genesis, where the Biblical version of the creation of the world is described, “And God said, ‘Let there be light’ and there was light.” Likewise, the Lex compiler said, “Let there be the file lex.yy.c: and there was lex.yy.c.” But wait, before discussing lex.yy.c, we must discuss the structure of a Lex program, which consists of the following sections:
- Definition section
- Rule section
- User defined subroutines
The definition section: The definition section starts with %{ and ends with %}. We can write C program segments within this section. Everything contained within this section will be directly copied to the generated C file. Conventions for comments in C can be followed for inserting comments in this section. If we write comments outside %{ %}, we must indent them with a single white space for the Lex compiler to understand them as comments.
e.g. %{
/* This is a sample program.
This will be copied to C file
This section contains # define, extern, and global declarations (if any)
*/
%}
This section may also contain regular definitions. But the regular definitions are defined outside %{ %}. It is optional to include regular definitions.
The rule section: This section starts and ends with %%. All the rules for translation are defined within this section. Each rule has a pattern and an action part separated by a white space. The patterns are specified using a regular expression. ‘|’(a vertical bar) can be used to separate patterns for which the action is the same.
For example:
abc |sdf {printf(“strings”);}
…results in printing ‘strings’ if the input contains either ‘abc’ or ‘sdf’. The rules are considered in the order in which they are specified. Let me explain this point with the help of an example.
The input contains “int a=10; char name[10]=”sharon” ” and rules are specified as:
%%
[a-zA-Z]+ { printf(“strings”);}
int|char|break {printf(“keywords”);}
%%
The first rule says that any combination of letters from A to Z or a to z can be identified as a string. So ‘a’, ‘name’, and ‘sharon’ will be identified as strings. Even though ‘int’ and ‘char’ are keywords, they too are combinations of letters from a to z, resulting in Lex identifying them as strings. Now let us change the order of the rules:
%%
int|char|break {printf(“keywords”);}
[a-zA-Z]+ { printf(“strings”);}
%%
This set of rules will identify ‘int’ and ‘char’ in the input file as keywords and ‘a’, ‘name’, and ‘sharon’ as strings for the same input. Thus the order in which rules are specified does matter in Lex programs.
Another notable feature is that Lex patterns will match a given input character or string only once and execute the action for the longest possible match.
For example, the input contains a string ‘intimacy’. It can be thought of as resulting in printing ‘int’ as the keyword and ‘imacy’ as the string. But since Lex carries out the action for the longest possible match, ‘intimacy’ will be identified as the string.
User defined subroutines: This section includes the definition of the main( ) function and other user defined functions which will be copied to the end of the generated C file. The definition of main() is optional, since it is defined by the Lex compiler.
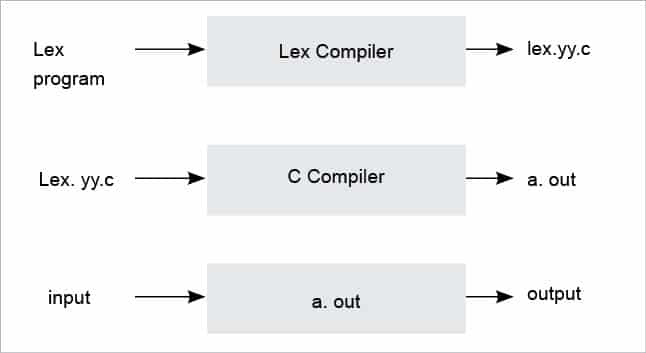
Program execution
A Lex file can be saved with the .l or .lex extension. Once the program is compiled using a Lex compiler, a C file lex.yy.c is generated. It is then compiled to get an a.out file, which accepts the input and produces the result. Diagramatic representation of the same is shown in Figure 1.
The following command is used to compile a program using the Lex compiler:
lex file_name.l
The C file generated — lex.yy.c — can be compiled using a gcc compiler:
gcc lex.yy.c -lfl
The above code generates the executable file a.out. The lfl or ll (depending on the alternatives to Lex being used) options are used to include the library functions provided by the Lex compiler.
./a.out < input_file_name
The above command will give the desired output.
Sample program 1
The following is a Lex program to count the number of characters in a file:
%{
int charCount;
%}
//This comment is to tell that following is the rule section
%%
[a-zA-Z.] { charCount++;}
%%
main()
{
yylex();
printf("%d \n", charCount);
}
Sample input_1: abs. +as
Sample output_1: +7
Sample input_2: abs.as
Sample output_2: 6
All the user defined variables must be declared. In this example, the variable charCount is declared in the definition section. Otherwise, when the lex.yy.c file is compiled, the C compiler will report the error ‘charCount undeclared’. The regular expression [a-zA-Z.] represents any letter in the English alphabet or a . (dot). Whenever a letter or . (dot) is encountered, charCount is incremented by one. It is to be noted that when you want to use . (dot) literally outside [ ], not as a wild card character, put a \(backslash) before it.
When you write the rule section, make sure that no extra white space is used. Unnecessary white space will cause the Lex compiler to report an error.
In the main() function, yylex() is being called, which reads each character in the input file and is matched against the patterns specified in the rule section. If a match is found, the corresponding action will be carried out. If no match is found, that character will be written to the output file or output stream. In this program, the action to be performed when ‘+’ is encountered is not specified in the rule section. So it is written directly to the output stream. Hence sample output_1.
The lex.yy.c file
The following is a description of the generated C file lex.yy.c. The Lex compiler will generate static arrays that serve the purpose of a finite automata, using the patterns specified in the rule section. A switch-case statement corresponding to the rule section can be seen in the file lex.yy.c. The following code segments are from lex.yy.c, obtained by compiling sample program 1.
switch ( yy_act )
{ /* beginning of action switch */
case 0: /* must back up */
/* undo the effects of YY_DO_BEFORE_ACTION */
*yy_cp = (yy_hold_char);
yy_cp = (yy_last_accepting_cpos);
yy_current_state = (yy_last_accepting_state);
goto yy_find_action;
case 1:
YY_RULE_SETUP
#line 7 "eg3.lex"
{ charCount++; }
YY_BREAK
case 2:
YY_RULE_SETUP
#line 8 "eg3.lex"
ECHO;
YY_BREAK
This is generated corresponding to the rule section in the sample program. We can see that case 0 is for input retraction. This is needed because it may be that only after reading the next character does the compiler understand that the character read is part of the next token. In that case, the file pointer needs to be retracted. Case 1 includes the action specified in Rule 1, to increment the value of the variable charCount. Case 2 is for simply printing the unrecognised symbol to the output stream. ECHO, seen in Case 2, is a macro name and its definition is as follows:
#define ECHO do { if (fwrite( yytext, yyleng, 1, yyout )) {} } while (0)
ECHO will simply write the content of yytext to the output stream. The use of yytext is mentioned in the next section.
The definition of YY_BREAK, a macro name seen in Case 2 of the above switch case block, is as follows:
/* Code executed at the end of each rule. */ #ifndef YY_BREAK #define YY_BREAK break; #endif
Thus YY_BREAK is to break the flow of execution.
Built-in functions and variables
The Lex compiler provides us with a number of built-in variables and functions. Some of them are listed below.
- The Lex library contains the definition of main() function. Programmers can either simply include main() from the library or can define their own main(). The main() function defined in the library contains a call to the function yylex( ). The default definition of main() is as follows:
main(int ac, char **av) { return yylex( ) ; }The variable yytext is a character array that contains a character/group of characters read from the input file for matching with any pattern specified in the rule section.
- The function yywrap( ) returns 1 if EOF is encountered, otherwise 0 is returned. One can modify this function according to one’s needs so that it may return 1 until all the files required are read.
- The variable yylen is the length of string in yytext.
- Some alternatives of Lex define the variable yylineno. It keeps track of the line number which is required for error reporting. yylineno is updated when the pattern for the new line (\n) is matched.
Sample program 2
The following program will make it clear how users can define their own sub-routines to use in a Lex program.
%%
[0-9]+ {display(yytext);}
. {}
%%
display(char a[])
{
printf("%s\n",a);
}
The above program prints nothing but the combination of digits in the input to the output stream. We can see that the second pattern specified in the rule section is a simple . (dot) and the action part specified as ‘{}’. This means whenever this pattern matches, do nothing. You can see the variable yytext, which contains the current lexeme, is passed as the argument to the user defined function display(). Another point to be noted is that this program does not contain a main() function. The default definition of main() must be included while this program is compiled. Otherwise an error will be generated. As stated earlier, the definition of main() can be included by compiling lex.yy.c with the lfl or ll options.
Lex is a very powerful tool that can be used to manipulate text that involves patterns. It gains its power from regular expressions. Luckily, the Lex language is compatible with C, a very commonly used programming language known to even high school students and thus, many of the problems solved using C can be coded in Lex. This simple tool makes the job of programmers easier.
We cannot downgrade the role of Lex to that of merely a simple pattern matcher. It finds application in the lexical analysis phase of a compiler too. More details about the construction of a lexical analyser using Lex can be seen in the book ‘Compilers: Principles, Techniques and Tools’ by Alfred V. Aho, Ravi Sethi and Jeffrey D. Ullman.
















