




























































Large language models are trained on massive datasets, enabling them to generate intelligent content. Prompt engineering is the art of creating efficient prompts to direct these models to get the intended results. Both must focus on responsible AI, so that the content that is generated is unbiased, respectful and in line with moral values.
Generative AI is a subset of deep learning. It uses artificial neural networks, which can process both labelled and unlabelled data using supervised, unsupervised, and semi-supervised methods. Large language models (LLMs) are also a subset of deep learning. Deep learning models or machine learning models, in general, can be classified into two types — discriminative and generative.
The discriminative model learns the conditional probability distribution or p(Y|X), and it classifies as a dog and not a cat. The generative model captures the joint probability p(X, Y) or just p(X) if there are no labels, predicts the conditional probability that this is a dog, and can then generate a picture of a dog (Figure 1). In essence, generative models can create new data instances while discriminative models discriminate between different data instances.
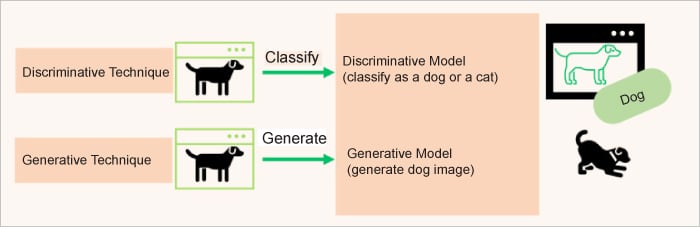
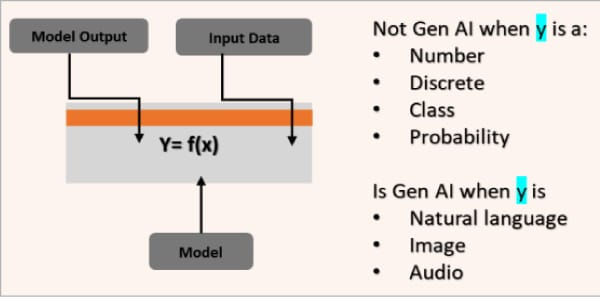
Figure 2 explains the distinction between generative AI and traditional AI.
LLMs are types of foundation models trained on massive datasets, enabling them to understand and generate natural language and other forms of content to perform various tasks. Microsoft has embraced interfaces such as Open AI’s ChatGPT-3 and GPT-4, which make LLMs readily accessible to the general public. These interfaces mark a substantial advancement in natural language processing (NLP) and artificial intelligence. Other market leaders are Google’s PaLM models and Meta’s Llama models, which are bidirectional encoder representations from transformers.
Owing to the extensive volume of data needed to train them, LLMs are designed to understand and produce writing like a person, among other types of content. They can translate into languages other than English, infer from context, produce coherent and contextually relevant responses, summarise content, respond to queries (both general and FAQ-related), and even help with creative writing or code-generating activities. They can also be used for writing code, or translating between programming languages.
Not all generative AI tools are built on LLMs, but all LLMs are a form of generative AI. Generative AI is a broad category for a type of AI, referring to any artificial intelligence that can create original content. LLMs are the text-generating part of generative AI.
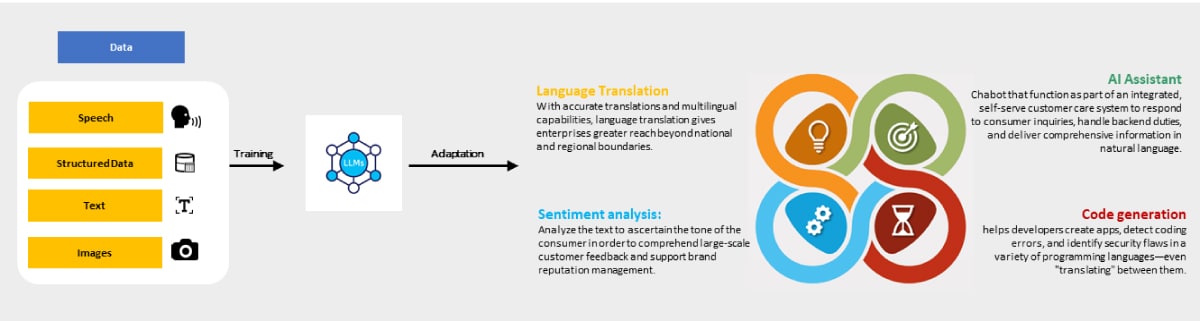
LLM models can perform various business and personal tasks when trained and given appropriate prompts. Figure 3 shows some of the popular use cases.
Understanding LLMs from a developer’s perspective
Artificial intelligence has undergone a revolution because of LLMs. These cutting-edge AI models are revolutionising how humans engage with technology by enabling the development of robust software applications through APIs. For developers, LLMs provide a plethora of new features, and come in two main categories:
- Base LLMs
- Instruction-tuned LLMs
A language model that creates text based on the input it gets without clear instructions or direction is commonly referred to as a ‘base LLM’. With the help of text training data, which is frequently gathered from a variety of sources, including the internet, base LLM is trained to anticipate the next word based on the most likely word that will follow. On the other hand, a language model that receives explicit instructions or assistance during the text creation process is referred to as ‘instruction-tuned’ LLM. This can entail imposing strict constraints or guidelines to affect the model’s results. Instruction-tuned LLM training often begins with a basic LLM that has been trained on a large volume of text data. Afterwards, inputs and outputs consisting of instructions and sincere attempts to comply with them are used to further train and fine-tune the system.
To make the system even more beneficial and instruction-tuned, it is frequently improved through the use of a method known as reinforcement learning from human feedback, or RLHF. Because instruction-tuned LLMs have been shown to be helpful, honest, and harmless, many real-world usage scenarios have switched to them. Compared to basic LLMs, they are less likely to produce harmful outputs.
Tuning LLMs
The most common way to interact with the LLM while creating and testing prompts is through an API. Tweaking these settings is important to improve the reliability and desirability of responses. The typical configurations or tuning you would encounter while utilising various LLM providers are described here.
Temperature: For tasks like fact-based QA, you might want to use a lower temperature value to encourage more factual responses.
top_t: A sampling technique with temperature, called nucleus sampling, allows you to control how deterministic the model is. Increasing top_t to a higher value will create a more diverse response. The general recommendation is to alter temperature or top_t but not both.
Max length: By changing the max length, you can control how many tokens the model produces, thereby avoiding lengthy or irrelevant responses and controlling costs.
Stop sequence: Specifying stop sequences is another way to control the length and structure of the model’s response.
Frequency penalty: The next token is subject to a penalty known as the frequency penalty. The likelihood that a term will reappear decreases with increasing punishment. This configuration reduces word repetition in the model’s responses.
Presence penalty: Similar to frequency penalty, the presence penalty is a constant penalty for repeated tokens, preventing excessive repetition. It can be increased for innovative or diversified text, or reduced for maintaining focus. The penalty is equal for tokens appearing twice or ten times.
As with top_p and temperature, it is generally advised to change the presence penalty or frequency but not both. Remember that the version of LLM you use will affect your results.
Prompt engineering basics
Prompt engineering is essentially the art of creating efficient prompts or inputs to direct AI language models towards intended results. It focuses on creating and refining prompts to effectively apply and construct LLMs for a range of use cases and applications (Figure 4).
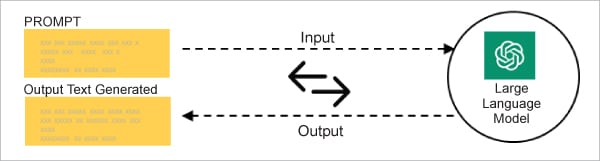
Prompt engineering skills help to better understand the capabilities and limitations of LLMs. Researchers use it to improve safety and the capacity of LLMs on a wide range of common and complex tasks such as question-answering and arithmetic reasoning. Prompt engineering is a tool used by developers to create reliable and efficient prompting methods that communicate with LLMs and other tools.
Elements of a prompt
In prompt engineering, various elements play a critical role in shaping the user’s prompt and obtaining the desired output. Let’s explain each of these.
Role: The role defines the particular function or identity that the model is anticipated to carry out during the conversation. It establishes the tone and degree of skill anticipated from the model’s answers.
Instruction: A particular task or directive that you would like the model to follow.
Context: Extraneous data or outside context that can direct the model towards more appropriate answers.
Input data: The information or query for which we are looking for a response.
Output indicator: Indicates the format or kind of output.
Constraint: The guidance should support readability and efficiency in a large-scale project environment while also improving the code’s performance and cleanliness.
Figure 5 shows examples of the different elements of a prompt.

Prompting techniques
Let’s now take a quick look at the more sophisticated prompt engineering techniques that help accomplish complicated tasks, and enhance LLM performance and reliability.
Zero-shot prompting: Zero-shot prompting refers to giving the model a prompt that is not included in the training set but allows it to provide the desired outcome.
Example
User prompt:
Classify the text into positive, neutral or negative. Text: That idea was awesome.
Few-shot prompting: LLMs perform poorly on more difficult tasks when operating in the zero-shot mode. Few-shot prompting can help the model perform better by guiding it using demonstrations provided in the prompt. The demonstrations are used to condition the model for later instances in which we want it to produce a response.
Example
User prompt:
Classify the text into positive, neutral, or negative. Classification: Positive Text: The furniture is small. Classification: Neutral Text: I don’t like your attitude Classification: Negative Text: That idea was awesome. Classification:
Chain-of-thought prompting: There are several uses for chain-of-thought prompting, ranging from arithmetic problem solving to explaining intricate thinking tasks. In educational contexts, where comprehending the process of problem-solving is just as crucial as finding the solution, this is advantageous. It can also be used in programming assistants and customer support bots.
Retrieval-augmented generation (RAG)
RAG was created because LLMs like GPT had limitations. While LLMs have proven to be quite good at producing text, their applicability in the real world is restricted since they often do not produce responses that are appropriate for the context. RAG aims to bridge this gap by offering a system that excels at interpreting user intent and delivering perceptive, context-aware replies.
RAG is essentially a hybrid model that seamlessly blends two significant components. Retrieval-based approach is the process of gathering data from outside knowledge sources, like databases, documents, and web pages. Generative models, on the other hand, are highly adept at producing language that makes sense and is pertinent to the circumstance. What distinguishes RAG is its ability to strike a balance between these two factors, creating a win-win collaboration that allows it to comprehend user enquiries completely and produce accurate, contextually rich answers.
The information capacity constraint of traditional language models is addressed by retrieval augmented generation (RAG). Traditional LLMs rely on outside knowledge sources to supplement their limited memory, often known as ‘parametric memory’. RAG introduces a ‘non-parametric’ memory. This greatly broadens LLMs’ body of knowledge, enabling them to offer more thorough and precise solutions.
Prompt engineering principles: Designing effective prompts
| Best practice | What this means | Examples |
| Clarity | You should be very explicit about what you want the model to accomplish in the prompt. Stay clear of uncertainty. | Task: Translate a sentence from English to French.
Unclear prompt: ‘Translate this.’ Effective prompt: ‘Please translate the following English sentence into French: ‘How are you today?’’ |
| Context matters | If you provide relevant context or background information in your instructions, the model’s understanding and response accuracy will be significantly improved. It’s like alerting your AI model a little in advance. | For example, it might help to include the source language when requesting an AI model to translate a sentence. ‘Translate the following sentence from English to Hindi: [sentence]’ gives the model the necessary background knowledge to translate the text accurately. |
| Mitigating bias | Biases in AI outcomes can be eliminated with the help of better prompt engineering. By providing clear and objective directions, developers can reduce the likelihood of delivering sensitive or biased information. | Use open-ended questions: Open-ended questions encourage models to explore content, provide comprehensive analysis without generating specific responses, and encourage exploration of various aspects of the prompt.
Avoid any assumptions: Assumptions can lead to partial responses in models, such as the user’s assumption that assistive robots are effective for dementia, causing a positive sentiment. Avoiding this assumption helps provide a less partial response in the second prompt. Use inclusive language: Inclusive language refers to language that does not discriminate against any particular group of people, such as ’humanity’ instead of ‘mankind’. Use multiple LLMs: Using multiple LLMs for response generation ensures a balanced and unbiased view, as no single LLM is perfect. |
| Specify output format | Less effective prompt: Extract the entities mentioned in the text below. Extract the following 4 entity types: company names, people names, specific topics, and themes.
Effective prompt: Extract the important entities mentioned in the text below. First extract all company names, then extract all people names, then extract specific topics which fit the content. Desired format: |
|
| Length matters | AI interfaces may have character counts, but extremely long prompts can be challenging for AI systems to handle. | To address these challenges, users can break down long prompts into smaller, more focused segments or provide clear and concise instructions to guide the model’s response. |
| Avoid conflicting words or sentences | Prompts with ambiguous or contradictory terms, such as ‘detailed’ and ‘summary’, can cause conflicting information for the model. Prompt engineers ensure consistency in prompt formation. | Prompts should use positive language and avoid negative language, with a rule of thumb being ‘do say ‘do’ and don’t say ‘don’t’.’ AI models are trained to perform specific tasks, so asking for an exception is meaningless unless compelling. |
| Cut down on ‘fluffy’ and vague descriptions | Prompts with vague words may produce incorrect results. | Less effective prompt: The description for this product should be fairly short, a few sentences only, and not too much more.
Effective prompt: Use a 3 to 5 sentence paragraph to describe this product. |
Landscape of open source LLMs
Bard, GPT3, GPT4, etc, are closed LLMs that perform exceptionally well; however, since they are not open source, they come with specific limitations.
- Limited user control: Closed LLMs developed by large tech companies lack customisation options. Users can’t access the underlying architecture or weights of these models, preventing fine-tuning or tailoring them to specific requirements. This limited control hinders innovation and restricts users from fully leveraging the models’ capabilities.
- External service dependency: To use closed LLMs, users must interact with API endpoints hosted by the respective companies. This dependency on external services introduces latency issues and potential downtime if the service provider experiences outages. Users are also subject to the pricing and availability policies set by the service provider.
- Data privacy concerns: When using closed LLMs for inference on sensitive data, users must trust that the data sent to external API endpoints is handled securely. The lack of control over data handling and processing raises privacy risks, especially when dealing with confidential or personal information. Compliance with privacy regulations and data protection laws becomes a concern for users.
On the other hand, open source LLMs offer users transparency, flexibility, and control, making them an appealing option compared to closed models. These models vary in architecture, number of parameters (impacting performance and hardware needs), datasets used for training, and licences (determining their usage). Open source LLMs provide transparency, flexibility, and customisation options, allowing researchers, developers, and users to advance natural language processing and create innovative language-based solutions.
Nevertheless, open source LLMs are inferior to closed source LLMs, such as GPT-4. This is because closed source LLMs have greater training data and computational capacity.
Let’s delve into some prominent open source LLMs and their key attributes.
LLaMA created by Meta: Most leading companies in the LLM market have chosen to develop their LLM in secret. However, Meta has set itself apart. In July 2023, LLaMA 2, a pre-trained generative text model with seven to seventy billion parameters, was released for research and commercial use. Reinforcement learning from human feedback (RLHF) has helped to refine it. It’s a generative text model that can be customised for a range of natural language production activities, including programming jobs, and can be utilised as a chatbot. Open, customised versions of LLaMA 2, Llama Chat, and Code Llama have already been made available via Meta.
BLOOM: Launched in 2022, BLOOM is an autoregressive LLM trained to continue text from a prompt on massive quantities of text data utilising industrial-scale computational resources. It was developed over the course of a year-long joint initiative with volunteers from over 70 nations and researchers from Hugging Face.
BLOOM’s release was a significant turning point towards the democratisation of generative AI. One of the most potent open source LLMs, BLOOM has 176 billion parameters, and can produce accurate and coherent text in 46 languages as well as 13 programming languages.
The foundation of BLOOM is transparency; anybody can run, examine, and enhance the project by having access to the training data and source code. BLOOM is available for free usage inside the Hugging Face network.
Falcon 180B: The new Falcon 180B indicates that the difference between proprietary and open source large language models is narrowing fast, as already indicated by the Falcon 40B, which ranked #1 on Hugging Face’s scoreboard for big language models.
Falcon 180B, which was made available by the Technology Innovation Institute of the United Arab Emirates in September 2023, is being trained using 3.5 trillion tokens and 180 billion parameters. Hugging Face indicates that Falcon 180B can compete with Google’s PaLM 2, the LLM that runs Google Bard, given its amazing processing capacity. Falcon 180B has already surpassed LLaMA 2 and GPT-3.5 in a number of NLP tasks.
It’s crucial to remember that Falcon 180B needs significant processing power in order to operate, while being free for usage in both commercial and research settings.
BERT: BERT, which stands for Bidirectional Encoder Representations from Transformers, was introduced by Google as an open source LLM in 2018, and quickly reached state-of-the-art performance in numerous natural language processing applications.
BERT is one of the most well-known and often used LLMs because of its cutting-edge features from the early days of LLMs and the fact that it is open source. Google declared in 2020 that BERT had been integrated into Google Search and was available in more than 70 languages.
Responsible AI through ethical prompt engineering
The act of creating input enquiries or prompts for AI models in a way that minimises biases and encourages fairness is known as ethical prompt engineering. In essence, ethical prompt engineering makes sure that the output of AI is consistent with moral standards and human values.
If AI models’ responses are not closely monitored and analysed, they could reinforce negative prejudices. Biased employment algorithms, distorted newsfeed content, and unjust treatment of people by face recognition systems are a few instances of AI bias in action.
The role of ethics in prompt engineering can be likened to a guiding compass. It directs the creation and formulation of prompts to ensure that they lead to AI responses that are equitable, respectful, and in line with our moral values. The answers to these questions should ensure that AI’s responses are fair, non-discriminatory, and respectful.
Like any technological advancement, prompt engineering has a great deal of potential advantages as well as disadvantages. On the one hand, clever hints can improve AI’s functionality and increase its effectiveness and efficiency. These questions can direct AI to help with routine chores, offer insights across a range of domains, and even push the limits of creativity. In addition, well-designed prompts can guarantee that AI recognises and honours a wide range of gender identities and experiences, which promotes diversity.
However, inadequate prompt design can lead to AI responses that are prejudiced, biased, or misinformed. For example, an inadequately sensitive question regarding gender identities may cause AI to produce insulting or discriminatory responses. In quick engineering, ethical factors can reduce these risks and guarantee that the advantages of AI are achieved without sacrificing inclusivity, fairness, or respect.
Integrating ethics into AI development is a positive step that begins at the design phase and continues throughout the life cycle of development.
First and foremost, development teams must be trained on the ethical implications of AI and motivated to take these factors into account when designing and developing new products. These teams can further assure the development of inclusive and respectful prompts by incorporating varied perspectives. Second, it’s critical that AI systems are transparent. Developers ought to record their design choices and provide them for outside inspection. Because of this transparency, which promotes responsibility and trust, possible biases and ethical issues can be recognised and corrected.
Companies should encourage constant communication and cooperation with stakeholders. It is possible to increase the likelihood that an AI system will uphold moral principles as it develops. Incorporating ethics into AI involves more than just preventing damage or unfavourable consequences. The goal is to fully utilise AI to benefit all people, not just a small percentage.
















{kind=link}