






























































As we move towards a world where data will drive everything, protecting this data is one of our highest priorities. From the primitive need of just having another copy of data just in case the hard disk crashes, to real-time data protection with near-zero RTO and RPO, data protection technology has made tremendous progress in the last 20 years or so. Even so, almost all methods still use snapshots as a basic tool. This write-up attempts to understand how snapshots work.
As the name suggests, snapshots are just a snap of the file system/volume/disk or, in other words, a point-in-time image. But what exactly is a point-in-time image? Let’s get a little deeper into understanding what snapshots really are, how they work and, more importantly, what makes them an indispensable feature in data protection technology. A snapshot can be that of a disk, a volume, a file system, or even of a single file. So, if a disk is being snapped, its snapshot will be on another disk. Similarly, the snapshot of a file system is another file system, and of a file is another file, as we see in case of vmdk files in VMware. However, the underlying concept of a snapshot is similar.
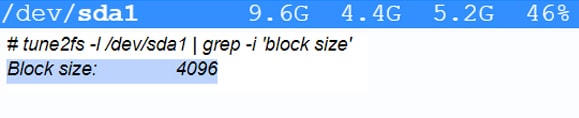
As memory is divided into pages to address and locate data in it, the smallest unit of a data storage program is a logical block. Every file system divides the disk space into logical units of blocks of a size specified during creation. Block size usually depends on the type of workload. For instance, workloads that have larger files like databases use large size blocks. Every file is a collection of such blocks. When a new file is created, it is allocated an inode, which stores the first block address from where the file begins and the total number of blocks the file is allocated. Each time new data is written to the file, a number of blocks are allocated to it by the file system program. Figure 1 displays the block size of 4K of an Ext4 file system on Ubuntu.
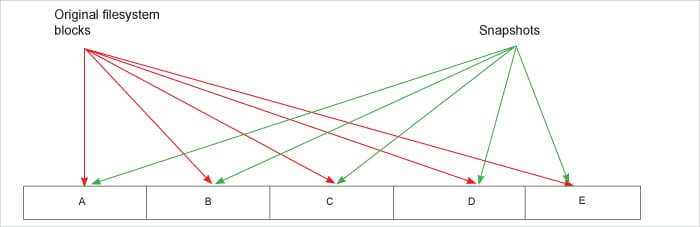
A file system basically consists of a superblock, journal, bitmaps and data blocks. The bulk of data is in data blocks. When a file system snapshot is triggered, all its blocks (excluding the data blocks) are copied to the snapshot. The data blocks of the original file system are in a 1:1 mapping with the data blocks of the snapshot. What this means is that the actual data continues to reside on the original file system. As seen in Figure 2, the snapshot only points to the same data blocks on the file system. So, when a backup application requests to read a particular file, the snapshot locates the starting data block of the file, reads the block on the original file system, and returns the data to the application. Since there is no actual data that is being read and written, snapshots are almost instantaneous. All the time they take is just to copy the metadata to know file allocations.
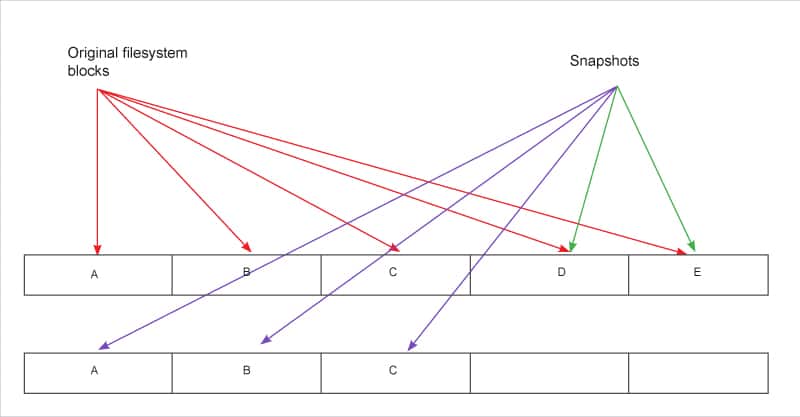
Further, as shown in Figure 3, when the files on original file systems are to be modified, a copy-on-write mechanism ensures that the data blocks of files being edited are first copied to the snapshot data blocks before modifying the original data blocks. It is here that the data is copied block by block from the file system to snapshots. Over a period of time, when all the files on the original file systems have been modified, all its data blocks are copied to the snapshot before being overwritten. Hence, the snapshot consists of all the blocks of that data which existed on the file system at the time the snapshot was triggered. In other words, a snapshot is the image of the file system at that point of time when the snapshot was triggered.
Given that snapshots provide an alternate handle to access the file systems, the read requests from backup applications do not hinder the operations of production applications. Apart from backups, some of the additional benefits of a snapshot are:
- Ability to restore the file system to a previous state
- Reduction of load on original file system
- Test and development
- Snapshots are also an important component because they fire the replications which play an important role in overall data protection implementation. Given the network bandwidth limitations, copying all the data over the network from the original file system is usually not feasible. A snapshot of the original file system is created, and the replication tool copies this data to the replication site or on the cloud over the network. Once the replication is complete, subsequent data is then synced between the original and its replica. Features like compression and deduplication play a major role here to mitigate the network limitations.While snapshots are a great data protection tool, they are not free from risks and limitations. Some of these are:
- As the snapshots refer to original file system data blocks, any corruption in the original files also corrupts the snapshot.
- Snapshots can fail to get restored.
- Multiple snapshots tax the original file system.
- The original file system is frozen for active IO when snapshots are taken. This delay blocks applications from accessing data. This might risk applications with intensive IOs.
OpenZFS used by many open source storage products, viz, FreeNAS/TrueNAS, has a well implemented snapshot mechanism. As it supports different commercial and open source backup software, FreeNAS is a fantastic choice for primary and secondary storage.




















{kind=link}