






























































Code generators bring the fun back into coding. This article lists their benefits and tells how they can be used in different ways, efficiently and effectively.
What does an enthusiastic programmer dream of? Getting to spend every day trying to solve real-world problems using interesting concepts and clever algorithms. And what do we really do as professional developers? Spend hours on a vast set of boring and artificial problems like npm dependency issues.
One of these boring and annoying problems is the creation and maintenance of boilerplate code. That’s when we start exploring code generators. They first help us, then bring the fun back in, and transport us to a whole different frontier. What’s more interesting? This is a rare case of the lazy becoming prolific!
Let’s see what code generators can offer, where they are used, and how to make their use effective and efficient.
Code generators
What exactly do we mean by code generators? Compilers are the most basic kinds of code generators, generating Assembly or machine code from high-level language instructions. There are in-language code generation features too, like macros and generics. However, our focus will be on the kinds like preprocessors and transpilers, which generally convert between high-level languages, and those which generate programs or snippets from the declarative specifications that we give in YAML or JSON.
Code generation or better language?
Isn’t code generation like a workaround? Why not pick a supreme language and use it directly instead of generating code in multiple stages?
First, the goal of code generation is not always to overcome language limitations. Just think about auto-generating HTML documentation for your API. You are not trying to overcome the limitation of Go or PHP here, right?
Second, general-purpose languages will always have tradeoffs or weak areas and you’ll have to do something about it. Think of Go before generics. Think of powerful languages with unfriendly syntaxes. And even if there is a superior language, what if you are working on an existing codebase?
Also, code generators tend to be problem-specific. Not general-purpose, not even domain-specific, but problem-specific. That makes them so effective.
Finally, who said code generators cannot be languages? There is m4, a macro processor that is Turing-complete, and there is PHP, a templating system, which everybody considers to be more of a programming language.
The advantages of generative programming span from the ease and speed of development to maintainability, consistency, and memory safety and security. They can also be handy with shared code where librarification is hard or less efficient (microservices, maybe?). And then there is fun.
Too much talk. Let’s see some examples.
Example: OpenAPI
Consider writing an API server. You not only have to write the handlers, but add code for routing, security checks, parameter extraction, validation, etc, which most of the time don’t have anything to do with business logic. But things don’t end there. You also have to provide documentation and client SDKs in various languages, keep them updated and in sync.
This is where OpenAPI comes in. With OpenAPI, you specify your API in a YAML or JSON file, and then use different generators to generate boilerplate code, client SDKs, documentation, etc. All you have to write manually is the business logic (well, most of the time).
Figure 1 shows a sample OpenAPI workflow. Here some Go code is auto-generated from the API spec api.yml, which is combined with manually written Go code (kept in a separate file) to build the final server binary. The same YAML file can be fed into another tool to generate the HTML documentation.
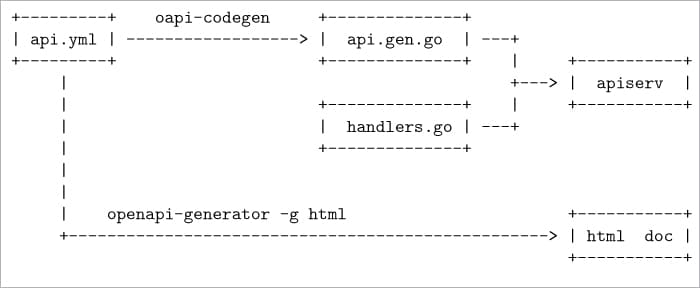
Here is a part from the YAML input, which is a spec for an API with two endpoints to find the sum and difference of two numbers:
/calc/sum: get: description: Returns the sum of the given numbers. parameters: - name: x in: query required: true schema: type: integer # “y” needs quoting because y is boolean yes in YAML - name: “y” in: query required: true schema: type: integer responses: ‘200’: description: The sum.
Here are the handwritten handlers in Go, which perform the actual logic:
func (calc Calc) GetCalcSum(w http.ResponseWriter,
r *http.Request,
params GetCalcSumParams) {
fmt.Fprintf(w, “%d\n”, params.X + params.Y)
}
func (calc Calc) GetCalcDiff(w http.ResponseWriter,
r *http.Request,
params GetCalcDiffParams) {
fmt.Fprintf(w, “%d\n”, params.X - params.Y)
}
That’s it. The YAML file has 43 lines, and handwritten Go code has less than sixty lines. oapi-codegen generated 351 lines that contain parameter extraction, validation, error messages, etc. Here are the auto-generated validation and error messages in action:
$ curl ‘localhost:8080/calc/diff?y=12’ parameter “x” in query has an error: \ value is required but missing $ curl ‘localhost:8080/calc/diff?x=10&y=someString’ parameter “y” in query has an error: \ value someString: an invalid integer: invalid syntax
Example: enum stringification in C
Many times we need to print the name of an enum member in C, usually for logging or debugging purposes. But such information is not available to the program at runtime. So we end up writing an array that contains string constants representing the enum members, like this:
// XXX Manually keep in sync with the array opstr
typedef enum Operation {
OP_SUM,
OP_DIFF,
OP_LARGEST,
OP_SMALLEST,
} Operation;
// XXX Manually keep in sync with the enum
const char * opstr[] = {
“OP_SUM”,
“OP_DIFF”,
“OP_LARGEST”,
“OP_SMALLEST” };
Now opstr[OP_LARGEST] would give us the string “OP_LARGEST”.
But see how we had to put a comment asking future maintainers to keep the blocks in sync? What if they (read: us) missed those comments? That would depend on the mistake. If changes were made in the beginning or middle for either structure, we’d get incorrect logs, without ever realising it. If the enum got a new value OP_DIV at the end and the array was never updated, our program would probably crash with a SEGFAULT (because opstr[OP_DIV] points to invalid memory area now).
Now let’s write a Makefile that invokes grep and sed to automate the generation of the array.
opstr.gen.h: main.c
(echo ‘// Do not edit this file!’ &&\
echo ‘const char * opstr[] = { ‘ &&\
grep -E ‘^\s*OP_[A-Z]+,$$’ main.c|\
sed -E ‘s/^\s*(OP_[A-Z]+),$$/ “\1”,/’ &&\
echo ‘};’) > opstr.gen.h
Once this file is in place, a simple make command will make sure the array is generated from the enum if it is missing, or is regenerated if the enum has been updated.
go generate
Go has parallels to both the stringification concept and make used in the last example. Since Go has its own build system instead of Makefiles, there is a special annotation called go:generate and the go generate command to invoke external generators.
Rob Pike, famous programmer and one of the creators of Go, lists its uses in the Go codebase itself in an official blog entry (go.dev/blog/generate):
“… generating Unicode tables in the unicode package, creating efficient methods for encoding and decoding arrays in encoding/gob, producing time zone data in the time package, and so on.”
One tool used in combination with go generate is stringer, whose purpose is similar to the enum stringification we saw above.
In the wild
Code generators are everywhere — from UNIX to Go and k8s ecosystems. Here is a quick listing to give you an idea:
- Compiler compilers: lex, yacc, etc
- Transpilers
- Build system generators: Automake, CMake, qmake, etc
- GUI builders: Glade, Qt Designer, etc
- Configuration generators: update-grub
- In the Web world
-
- CSS pre-processors: SaSS, LESS, Stylus
- k8s: kompose, kustomize, helm, etc
- Interface/binding generators: SIP for Python (used for PyQt, wxPython, etc), PyBindGen, SWIG, etc.
- Flexible: Telosys from Eclipse (DB/model to any kind of code based on templates)
- protoc with gRPC Go plugin
- m4 – a general-purpose macro processor from the 70s, part of UNIX
I’m yet to try some of the above.
Drawbacks
Code generators are not without drawbacks. To begin with, they can generate truly ugly code. They’re so mechanical that not even debuggers like gdb can help. Outputs of lex and bison are examples for this. Sometimes this is for better performance. But generators in general can be less efficient too. This is because tools have to be general and won’t be able to optimise for individual use cases. (But you can write your own, right?)
Compiler generators are also known for bad error reporting. This could be one reason some major compilers and interpreters use handwritten parsers.
One could argue that the use of generators makes you not know what’s happening behind the scenes. But this is not a hard restriction.
The declarative nature of the input to the generators can be an advantage and disadvantage at the same time. Advantage in the sense that it makes sure we have some sort of specification for our APIs, workflows, etc. But the problem is, we might end up ruining those same specs to work around generator limitations.
Some tips
Okay, code generators are helpful. But what can we do on our part to make up for their shortcomings and make the whole process even better? Here are some tips.
- Be aware of the licensing restrictions of the particular tools you use.
- Use tools like indent and gofmt to reformat the generated code so that it becomes easy to read and debug. This will also get rid of formatting-related compiler warnings.
- Use linters and other static analysis tools to check for code quality and potential bugs.
- Make sure to write and run tests, especially for auto-generated validators. If you’re auto-generating tests, check them manually and lock them.
- Although it’s an anti-pattern to commit and push generated artefacts, treat auto-generated code like a regular source and include it in the repo. This will be helpful for others trying to build your project on a platform which the generator doesn’t support. It’ll be helpful to you too when the generator becomes obsolete in future.
- Finally, and most importantly, try to make code generation part of your pipeline, if it makes sense. I’ll explain.
Making it part of the pipeline
Is code generation a one-time process or something that is to be done every time you build the software?
For some cases, it doesn’t make sense to put the generation in the pipeline. Maybe you are migrating your project from one programming language to another, or choosing a different set of supporting systems so that the configuration files need to be migrated.
Here it’s clear that you’ll be running the converter only once. The original source files are archived, generated files become the new source, and the generator is never run again.
But in some other cases, you are not planning for a migration. Maybe you need something in different formats, or maybe you need boilerplate related to your handwritten code. In such situations you won’t be archiving or throwing away the original source. Here it makes sense to put things in a pipeline. The Makefile in our C enum stringification example is an example for this. The source file is checked for updates every time we build the software and the generation commands are run if there is something new.
But what if you had to make manual changes to the generated code and still want it auto-updated whenever the source changes? Let’s see an example.
Don’t give up on the pipeline: kompose example
kompose is a tool that helps you generate Kubernetes YAML files from Docker Compose files. It is intended to be a one-time process because there is no one-to-one mapping between Docker Compose and Kubernetes. So you are guaranteed to be making changes to the generated files. But what if you want to keep both Docker Compose and Kubernetes versions in parallel, auto-applying changes in the Docker Compose while still keeping your edits to the generated configuration?
I had faced a similar challenge. These were my additions:
- k8s image pull policy and image pull secret, which were missing in the Docker Compose version
- Services ignored by kompose because the ports are not exposed in the Docker Compose version
- Configuration for initContainers, which was missing in the Docker Compose version
Instead of choosing to convert once and keep both versions in sync manually, I chose the following solutions, respectively, for each of the above:
- Use kompose annotations kompose.image-pull-policy, kompose.image-pull-secret in the Docker Compose file itself, so that kompose knows to add them.
- Write files for missing services manually.
- Use a patch file to add the initContainers section.
This way, things will be reproducible while still keeping customisations. Of course it doesn’t make sense to do this if the differences outnumber similarities.
nguigen
I’ve been developing desktop applications for more than a decade. Although trivial, they’ve been used by others, which means I had to regularly update, port and package these apps. nguigen (short: ngg) is a project that I started as a solution to several difficulties I experienced as part of this.
It is a general-purpose programming language and a code generator that aims to generate code for multiple languages, platforms and GUI toolkits from a single, mostly generic codebase. This is different from solutions like Electron because we’re going native here and there is zero overhead. Once mature enough, it could be used to generate C/GTK, C++/Qt, Android and Web apps.
Its C output is already mature and is being used to self-host the compiler (i.e., ngg compiler is written in ngg itself). nguigen offers more expressiveness and compile-time semi-automatic memory management when generating C code. This is important since the C ecosystem remains far superior to many alternatives and one would choose to stick with it.
nguigen is not released yet, but the plan is to release it as free (libre) software. Learn more at nandakumar.co.in/software/nguigen/.
Codegen in the nguigen ecosystem
The development of nguigen itself depends on code generation. Apart from being written in itself and self-compiled to C, parts of the source are auto-generated from mappings written in TSV (tab-separated values) files.
Makefiles with correct dependencies are auto generated using ngg itself and a bash script. This comes handy during major refactorings.
The parser is also auto-generated from grammar specs. Usually lex and bison are used for this purpose, but for nguigen, I wrote my own.
And, finally, there is h2ngg, a simple tool to auto-generate ngg interfaces (like header files) for external libraries like GTK.
Write your own code generators
Maybe you’ve already noticed it: this talk is not just about existing code generators. It’s about the advantages and fun of generative programming, which can only be enjoyed at its maximum if you write your own generators. They benefit from being problem-specific.
How to do that? Maybe you can begin with Makefiles and shell scripts. Use some Python. lex and bison will be overkill, unless you are trying to create a language.




















{kind=link}