

We live in an era where data is growing at a huge pace and will continue to do so as new technologies evolve. This data needs to be pipelined in order to be managed and analysed. Apache Beam helps with that.
Across the globe, tons of data is being generated every moment, thanks to:
- Social communication networks
- E-commerce platforms
- Supply chain management
- Stock markets
- Maps/location data
- Fraud detection in banking and finance
- Log files monitoring and analysis
- Electronic health records
- E-governance data sets
To process such data effectively, there is a need to integrate data pipelines so that congestion-free communication can take place.
Data flow pipelines and batch processing
The term data pipeline refers to the effective and rapid process of transporting data from its source to its destination (including the data warehouse). Data undergoes several transformations and optimisations along the road, ultimately arriving in a form suitable for analysis and business insights.
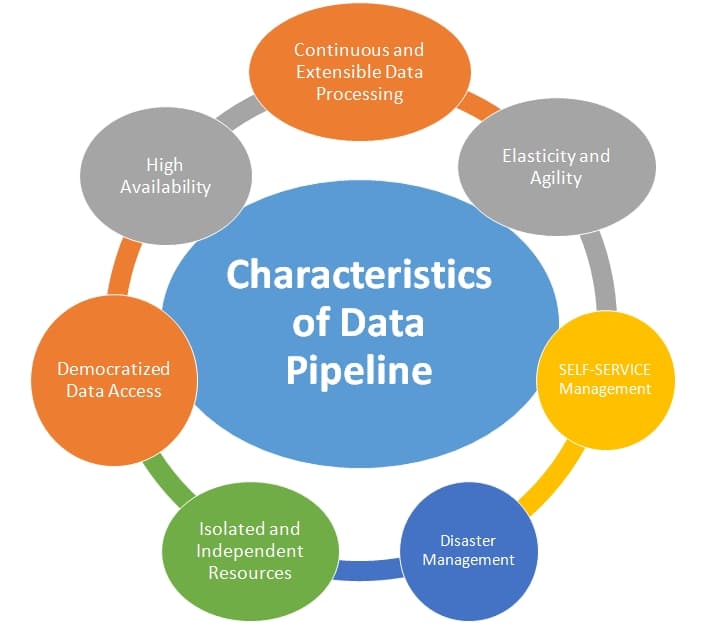
Data pipelining has many stages for real-time applications. Data is first ingested at the start of the pipeline. After that, there is a sequence of operations, each of which produces an output that serves as an input for the subsequent operation. This procedure is repeated until the pipeline is finished. It’s possible to execute separate processes simultaneously.
The transmission of data from one system to another is fraught with the potential for errors or slowdowns due to the complexity of the networks involved. The extent and effect of the issues only grow as the breadth and depth of the data’s function expands. For this reason, data pipelines are crucial. They allow seamless, automatic transfer of data from one phase to the next, reducing the need for any human intervention. They are crucial for real-time analytics, which allow you to act on information more quickly.
Assuring consistent data quality and allowing rapid analysis for business insights can be achieved by merging data from several silos into a single source of truth. Also, information from the point of sale (PoS) system can be processed in real-time using a streaming data pipeline. The stream processing engine may loop the pipeline’s outputs back to the PoS system or send them to other applications like data repositories, marketing apps, and customer relationship management (CRM) software.
Each data pipeline has three main parts: a data source, some sort of processing step(s), and a final destination. A data pipeline’s last stop may be referred to as a ‘sink’ in this context. Data pipelines facilitate the transfer of information between several systems, such as an application and a data warehouse, a data lake and an analytics database, or a data lake and a payment processing system. It is possible for a data pipeline to have a single source and a single destination, in which case the pipeline’s sole purpose would be to effect changes to the data collection. A data pipeline exists wherever information is sent from point A to point B (or B to C to D).
| Software suite | URL |
| KNIME Analytics Platform | https://www.knime.com/knime-analytics-platform |
| RapidMiner | https://rapidminer.com/ |
| Apache Spark | https://spark.apache.org/ |
| Pentaho | https://www.hitachivantara.com/en-us/products/lumada-dataops/data-integration-analytics/download-pentaho.html |
| Kafka Streams | https://kafka.apache.org/ |
| Atlas.ti | https://atlasti.com/ |
| Apache Storm | https://storm.apache.org/ |
| Apache Hadoop | https://hadoop.apache.org/releases.html |
| Apache Cassandra | http://cassandra.apache.org/download/ |
| Apache Flink | https://flink.apache.org/ |
| OpenRefine | https://openrefine.org/ |
| Data Cleaner | https://github.com/datacleaner |
| Apache Nifi | https://nifi.apache.org/ |
Table 1: Prominent software suites for data streaming and analytics
More and more data is being moved between applications, and as organisations seek to build applications with small code bases that serve a very specific purpose (called ‘microservices’), the efficiency of data pipelines has become crucial. Numerous data pipelines may be fed by information produced by a single system or application, and each data pipeline may in turn feed multiple other pipelines or applications.
Let’s take an example of the impact of a single social media post. A real-time report that tracks social media mentions; a sentiment analysis tool that gives a good, negative, or neutral conclusion; or an app charting each mention on a globe map might all be fed with data from this event. Despite sharing a common data source, these apps all rely on different data pipelines that must run without a hitch to produce the desired output for the end user.
Data transformation, enhancement, filtering, grouping, aggregation, and the application of algorithms to data are all typical components of data pipelines.
Pipelines in Big Data scenarios
The term Big Data indicates that there is a large amount of data to process, and this is true because the volume, variety, and velocity of data have all increased considerably in recent years. Having access to all this information can be useful for a wide variety of purposes.
Data pipelines have progressed with other parts of data architecture to accommodate huge data. A compelling reason to construct streaming data pipelines for Big Data is the volume and speed of this data. These pipelines help to gather information in real-time and act upon it.
The Big Data pipeline needs to be scalable in order to process massive amounts of data concurrently, as there are likely to be numerous data events that occur at the same time or very near together. The pipeline must also be able to detect and process heterogeneous data, including structured, unstructured, and semi-structured data.

Working with Apache Beam
Apache Beam (https://beam.apache.org/) is a free and open source unified programming model for describing and working with effective data processing pipelines. This data processing methodology is used to work with the pipelining and real-time filtering of data for multiple applications. All data sets and data frames can be processed using a single API with the integration of Apache Beam. To ‘build and run in any place’ is a key concept of Apache Beam.
Apache Beam reduces the complexity of processing massive amounts of data. It is widely used by thousands of businesses across the world thanks to its innovative data processing tools, proven scalability, and robust but scalable features.
The key features of Apache Beam are:
- Powerful abstraction
- Unified batch and streaming programming model
- Cross-language capabilities
- Portability
- Extensibility
- Flexibility
- Ease of adoption
Apache Beam is also available in its cloud based variant called Apache Beam Playground (https://play.beam.apache.org/), with the help of which programs can be executed online (Figure 4) using a range of programming languages including Java, Python, Go and SCIO.
Installation of Apache Beam on a dedicated server
Apache Beam can be installed on a dedicated server or Google Colab, as follows:
! pip install apache-beam
To work with data pipelines, it uses the following segments.
- Pipeline: Reading, Processing, Storage of data
- PCollection: Data frames, Accessing data sets
- PTransform: Data transformation, Windowing, Watermarks, Time stamps
- Runner: Operation of the pipelines
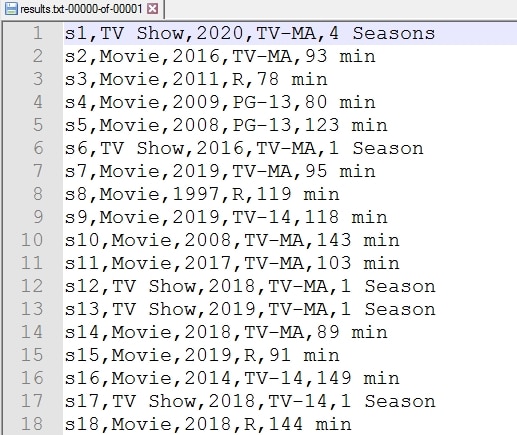
Here is a scenario where a data pipeline is executed on a CSV movies data set that has the following attributes:
- movie-id
- type-of-show (movie/web series)
- release-year
- duration-of-the-movie
The following code can be applied to filter and fetch the records matching ‘Movie’:
import apache_beam as apachebeam
datapipeline = apachebeam.Pipeline()
moviesdataset = (
datapipeline
| apachebeam.io.ReadFromText(“moviesdataset.csv”, skip_header_lines=1)
| apachebeam.Map(lambda line:line.split(“,”))
| apachebeam.Filter(lambda line:line[1] == “Movie”)
| apachebeam.io.WriteToText(“results2.txt”)
)
datapipeline.run()
Pipeline operations on a large data set can be implemented with minimum lines of code using Apache Beam.
Modern data engineering scenarios make use of Snowflake platforms that have enhanced structured formats for implementing data pipelines. Snowflake’s data pipelines are flexible, allowing for either batch or continuous processing. Data transformation and optimisation for continuous data loading are typically labour-intensive tasks; however, modern data pipelines automate many of these processes.



{kind=link}