






























































Discover how microservices and Docker, the two pillars of modern software development, work together to build strong and scalable software architectures.
Microservices have emerged as a powerful method to design flexible, scalable, and independently deployable systems. In a monolithic application everything is somewhat interdependent, but in microservices architecture functionalities are divided into smaller services, each of which can be developed, deployed, and scaled independently. This architecture style helps build resilient applications that can respond quickly to any changes, while modern DevOps practices can be adopted simultaneously.
Docker is a containerisation platform that makes it easy to containerise microservices. It allows a developer to put an application together with all its dependencies into one lightweight container, which can then be run in almost any environment, be it a developer’s machine, a test server, or the cloud. This makes Docker an essential ingredient of current microservices architecture.
These two pillars create a base upon which one can lay cloud-native applications that are modular, scalable, and easy to maintain.
Table 1: The benefits of using Docker for microservices
|
Benefit |
Description |
|
Portability |
Docker containers run consistently across environments—development, testing, staging, and production. |
|
Isolation |
Each microservice runs in its own container, reducing conflicts and improving security. |
|
Lightweight and fast |
Containers are faster to start and use fewer resources compared to virtual machines. |
|
Simplified dependency management |
Docker bundles an app with all its dependencies, ensuring consistent behaviour across systems. |
|
Scalability |
Services can be scaled independently using orchestration tools like Kubernetes or Docker Swarm. |
|
Improved DevOps workflow |
Seamless integration with CI/CD pipelines enables automated testing, building, and deployment. |
|
Version control and rollbacks |
Docker images can be versioned, allowing easy rollbacks to previous versions of a microservice. |
|
Ecosystem and community support |
A vast repository of prebuilt images (Docker Hub) and an active community accelerate development. |
Designing microservices for scalability
One of the main reasons businesses use microservices architecture is scalability. But attaining true scalability requires more than simply disassembling a monolith; it also entails building each service to expand, change, and function reliably in the face of rising demand (Table 2).
Table 2: Key design principles for scalable microservices
|
Principle |
Description |
|
Single responsibility |
Each service should own one specific business function (e.g., payment, authentication). This ensures clear ownership, simplified logic, and easier scaling. |
|
Loose coupling |
Services should interact via well-defined APIs without tightly binding to each other’s internal logic or data models. This allows teams to update, scale, or redeploy services independently. |
|
High cohesion |
Internally, each service should handle related tasks. This ensures that services are logically grouped and easier to manage. |
|
Stateless design |
Stateless services don’t retain user or session information between requests. This makes it easier to scale horizontally by adding more service instances behind a load balancer. |
|
Service autonomy |
Services should manage their own database and configurations to avoid hidden dependencies and bottlenecks. |
|
Asynchronous communication |
Use message brokers (e.g., Kafka, RabbitMQ) for event-driven architecture. This helps decouple services, handle high volumes gracefully, and reduce the risk of cascading failures. |
Tools and patterns that encourage scalability are:
Gateway API: Controls routing, authentication, rate limiting, and centralises requests to backend services. Helps offload common issues and decrease direct dependencies.
Database for each service: Every microservice ought to have its own database schema. This permits independent scaling and schema evolution while avoiding tight coupling.
Caching techniques: To lessen load and boost performance, use Redis or Memcached to implement caching at the service and API gateway levels.
Load balancing: Distribute traffic among several instances of a service using load balancers or orchestrators (such as Kubernetes).
Retry logic and circuit breakers: To stop failures in one service from impacting others, use tools such as Hystrix or Resilience4j to apply resilience patterns.
Scalable services manage spikes in traffic by:
- Using Kubernetes or Docker Swarm to automatically scale containers.
- Monitoring response times, throughput, and bottlenecks with metrics and alerts.
- Ensuring that requests are idempotent, particularly for operations that can be automatically retried.
To prevent service interruptions, new service versions should be deployed while maintaining backward compatibility.
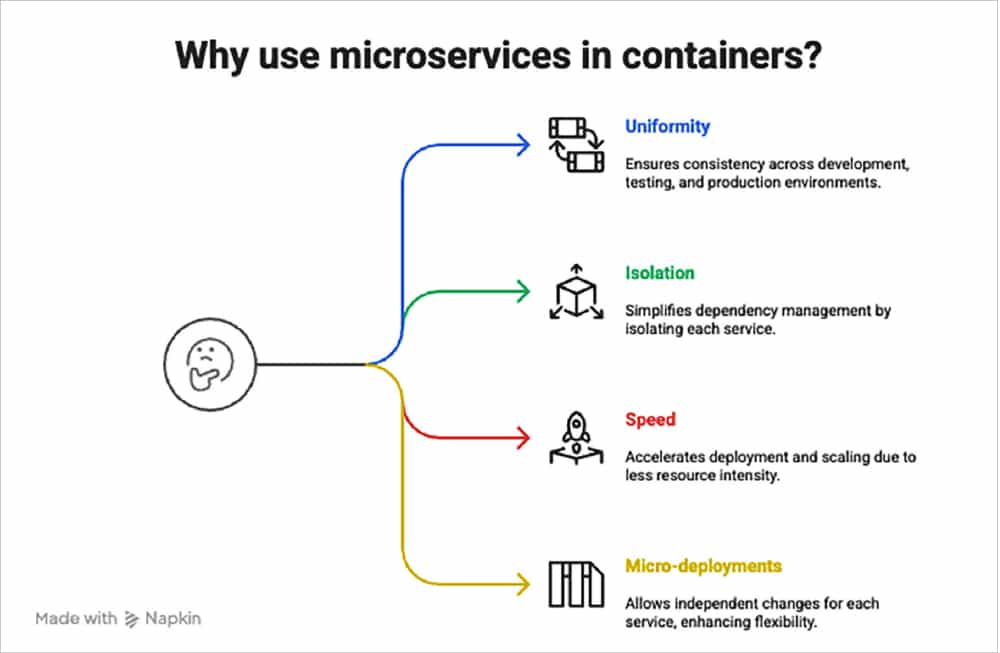
Containerising microservices with Docker
The next stage after designing and implementing microservices is to package and run them consistently across environments. Docker becomes crucial at this point. By combining the application code, runtime, libraries, and dependencies into a small, portable container, Docker allows developers to containerise every microservice.
Microservices are used in containers to:
- Maintain uniformity throughout the environments of development, testing, and production.
- Isolate the environment of each service, making dependency management easier.
- Speed up deployment and scaling because containers are less resource-intensive than virtual machines and start up faster.
- Permit changes to be pushed separately for every service by enabling micro-deployments.
Dockerizing multiple microservices: Complete setup with Dockerfiles and Docker Compose
The directory structure assumed is:
├── docker-compose.yml ├── user-service/ │ ├── app.py │ └── Dockerfile │ └── requirements.txt └── order-service/ ├── app.py └── Dockerfile └── requirements.txt ##################################### user-service/app.py ##################################### from flask import Flask app = Flask(name) @app.route(“/”) def home(): return “Hello from User Service!” if name == “main”: app.run(host=”0.0.0.0”, port=5000) ##################################### user-service/requirements.txt ##################################### flask==2.3.2 ##################################### user-service/Dockerfile ##################################### FROM python:3.10-slim WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . CMD [“python”, “app.py”] ##################################### order-service/app.py ##################################### from flask import Flask app = Flask(name) @app.route(“/”) def home(): return “Hello from Order Service!” if name == “main”: app.run(host=”0.0.0.0”, port=5000) ##################################### order-service/requirements.txt ##################################### flask==2.3.2 ##################################### order-service/Dockerfile ##################################### FROM python:3.10-slim WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . CMD [“python”, “app.py”] ##################################### docker-compose.yml (root folder) ##################################### version: ‘3’ services: user-service: build: ./user-service ports: - “5000:5000” order-service: build: ./order-service ports: - “5001:5000” ##################################### To build and run both services: ##################################### docker-compose up --build
Table 3: Orchestration and scaling with Docker tools
|
Aspect |
Description |
Additional details / Examples |
|
Docker Swarm |
Native Docker clustering and orchestration tool integrated with Docker CLI. |
Easy to enable with docker swarm init; supports simple YAML Compose files. Ideal for small to medium setups. |
|
Kubernetes |
Powerful, widely adopted orchestration platform with a rich feature set for large-scale container management. |
Uses declarative YAML manifests (deployment, service, ingress) and supports complex use cases. |
|
Automated deployment |
Containers are deployed and updated automatically based on configuration files describing desired state. |
Kubernetes uses kubectl apply -f deployment.yaml for declarative deployment. |
|
Scaling |
Supports horizontal scaling by increasing container replicas; vertical scaling adjusts container resources. |
Example: kubectl scale deployment my-app –replicas=5 to scale out pods. |
|
Load balancing and discovery |
Incoming requests are distributed across multiple container instances; service discovery helps locate services dynamically. |
Kubernetes provides internal DNS for services; Swarm uses built-in load balancing via routing mesh. |
|
Self-healing |
Automatically monitors container health and restarts or replaces containers that fail or become unresponsive. |
Kubernetes probes (livenessProbe, readinessProbe) detect failures and trigger restarts. |
|
Rolling updates and rollbacks |
Allows zero-downtime deployment of new versions; if issues arise, rollbacks restore previous versions. |
Kubernetes commands: kubectl rollout status deployment/my-app and kubectl rollout undo deployment/my-app. |
|
Resource management |
Define CPU and memory requests and limits to optimise usage and prevent resource contention. |
Example YAML snippet: resources: requests: cpu: “100m” memory: “128Mi” limits resource usage per container. |
Service communication and discovery
Several independent services must communicate with one another effectively and consistently in a microservices architecture. Creating scalable and maintainable systems requires the design of efficient communication and discovery mechanisms.
Communication of services: The most popular methods for implementing synchronous communication are gRPC and RESTful APIs. Services call one another directly and watch for answers. Implementation is straightforward, but it may result in tight coupling and possible latency problems.
Asynchronous communication: Sends messages without waiting for instant answers by using message brokers such as Kafka, RabbitMQ, or AWS SQS. Enhances scalability and resilience through service decoupling and gracefully managing traffic spikes.
Selecting the correct protocol: gRPC provides better performance and supports bi-directional streaming, but it requires more setup than REST, which is widely used and language-neutral.
Table 4: Monitoring and logging in microservices architecture
|
Component |
Description |
Common tools |
Best practices |
|
Centralised logging |
Aggregates logs from all microservices into a single platform for easier search and analysis. |
ELK Stack (Elasticsearch, Logstash, Kibana), Fluentd, Graylog |
Use structured logging and consistent log formats across services. |
|
Metrics collection |
Collects quantitative data on system performance (CPU, memory, latency, error rates). |
Prometheus, Grafana |
Expose metrics endpoints and monitor critical service KPIs regularly. |
|
Distributed tracing |
Tracks requests as they flow through multiple microservices, identifying bottlenecks and failures. |
Jaeger, Zipkin |
Use correlation IDs to link traces across services for full visibility. |
|
Alerting |
Sends notifications based on metric thresholds or anomaly detection to alert teams proactively. |
Prometheus Alertmanager, PagerDuty, Opsgenie |
Define clear, actionable alerts to avoid alert fatigue and ensure timely incident response. |
|
Health checks |
Regular checks on service status to ensure availability and readiness for handling requests. |
Kubernetes readiness/liveness probes, custom scripts |
Automate health checks to trigger restarts or traffic routing decisions based on service health. |
|
Secure data handling |
Ensure logs and metrics are stored securely with appropriate access controls and retention policies. |
Encryption, role-based |
Implement data privacy compliance, secure storage, and limit access to sensitive information. |
Service discovery
Static service endpoints are impractical in dynamic environments where services scale up or down or where IP addresses change frequently. This is resolved by service discovery, which makes it possible for services to dynamically find one another.
Client-side discovery: To find the location of the service instance, the client sends a query to a service registry (such as Consul or Eureka).
Server-side discovery: By querying the registry and rerouting requests appropriately, a load balancer or API gateway abstracts client discovery.
In containerised environments, this process is made simpler by Kubernetes’ integrated DNS-based service discovery feature.
Here are some additional considerations:
- To maximise resource utilisation and avoid overload, load balancing divides incoming requests equally among service instances.
- Health checks: Make sure traffic is only directed to healthy instances by routinely checking service responsiveness and availability.
- Timeouts and retries: Putting timeouts and retry policies in place increases system robustness overall and stops cascading failures.
Building a scalable microservices architecture with Docker is a tactical solution to the diversified needs of modern app development. The containerisation offered by Docker provides a uniform, lightweight, and portable environment that makes deploying easy and sure to operate as expected, no matter the stage of deployment considered — be it development or production.
Moreover, an integrated monitoring and logging setup keeps an eye on the health and performance of distributed services, allowing early detection of issues and quicker remediation. These practices, in view of automated scaling and self-healing, are crucial factors enforcing resilient techniques and competing uptimes.
This architecture, if followed, promotes an independent development and deployment cycle that lets teams test new ideas fast without jeopardising the stability of the whole system. The complexity it entails can be harnessed by using Docker’s ecosystem to employ some best practices in the areas of orchestration, communication, and observability.
















