




























































Treating data as a product (DaaP) requires the development of reliable systems that can be shared, reused and deliver value. Let’s understand this concept and the important role open source is playing in its implementation.
Data is often nicknamed ‘the new oil’ as it requires processing similar to oil extraction before it reaches its useful state. It then becomes the power source for business decisions and product development. The technology behind artificial intelligence, automation, recommendation systems and digital ads relies fundamentally on data.
Data has evolved from being an operational byproduct to a product that companies now actively manage. The Data as a Product (DaaP) approach transforms business data management through open source tools such as Apache Kafka for real-time data streams and Airbyte for data integration.
What does ‘Data as a Product’ mean?
Data as a Product (DaaP) means treating data like a hardware or a software product. The data is actively managed, maintained and improved to serve end users, just like is done with any product. Data was previously locked away in centralised databases that were only accessible by IT teams, which limited users’ ability to locate it. DaaP now puts the user, typically a data analyst, data scientist or developer, at the centre. This makes data more accessible, well-documented and reliable.
Today organisations use service level agreements (SLAs) for data management in the same way as they apply them to digital services. The agreements guarantee that data remains up to date, accurate and readily available. This transformation from static storage to delivering usable assets happens because data now serves multiple teams. Organisations across the board now view data as a product that requires reliability, maintenance and user-centred design.
Open source tools help businesses simplify their data management process. For example, Apache Airflow serves as a workflow automation tool which enables teams to construct and oversee data pipelines. It’s like a scheduler for data tasks. The data build tool transforms unprocessed data into structured datasets ready for analysis. It functions as a data transformation system, which transforms raw data into meaningful reports and dashboard content. OpenMetadata enables teams in discovering data, performing quality checks and tracking data lineage. This builds trust and transparency because multiple users or teams access the same data.
From a product management point of view, DaaP involves thinking about who the users are, what problems they face and how data can solve those problems. However, from a data engineering perspective, it’s about building systems and pipelines that deliver clean, consistent data at scale, often using open source stacks.
A wide range of sectors are embracing DaaP principles. Netflix relies on labelled behavioural data — what was watched, skipped or rewatched. This behavioral dataset is a data product. In open source ecosystems, platforms like MovieLens provide public datasets for similar purposes. These datasets power models and experiments in academic and community projects. Colleges use placement dashboards to track student information, which includes GPA scores, internship experience and test results. The cleaned and visualised data becomes an interactive product through open source tools such as Superset or Metabase, which benefits both recruiters and students. The coding platforms HackerRank and LeetCode track student performance by collecting problem-solving data. The open source edtech platform Moodle generates learning analytics data products, which deliver personalised feedback to students. Student projects that use Arduino or Raspberry Pi to develop an IoT based health tracker produce valuable time series data. The combination of structured data with visualisation tools like Grafana or Plotly transforms information into a usable product for patients and doctors to monitor their health progression.
According to Valtech, a global digital consultancy headquartered in Paris, applying DaaP principles led to a 12% improvement in forecasting and an error reduction worth $2.7 billion. This is because reliable, discoverable data allows teams to move faster.
|
Aspect |
Traditional data |
Data as a Product |
|
Accessibility |
Limited to IT |
Open to analysts, engineers, teams |
|
Maintenance |
Ad hoc updates |
Continuously maintained |
|
Documentation |
Often missing |
Standardised and user focused |
|
User experience |
Backend focused |
Designed for discovery |
|
Purpose |
Storage and |
Decision making, automation, ML training |
DaaP versus traditional data
Data monetisation: Direct and indirect strategies
Modern companies elicit value from data using two primary methods — direct and indirect monetisation. Direct monetisation involves selling or granting licences to use data with other organisations. Businesses can provide data in its original state or can offer processed data, which combines multiple datasets after cleaning and enrichment. The data becomes more valuable to potential buyers when it is processed. Data products are available for purchase through various pricing models.
The subscription model requires customers to pay a continuous fee to access the data. The data licensing model provides permanent or time-limited access to data at a fixed price. The customer must pay for data usage under the usage or consumption-based pricing model.
Open source platforms simplify the process of data preparation and distribution for direct monetisation. For example, CKAN (Comprehensive Knowledge Archive Network) operates as an open source data management system that helps governments and companies share their datasets. Platforms like data.world and Open Data Hub offer structured, searchable datasets, which become monetisable through API integration and visualisation tools. The open datasets found on GitHub and Kaggle often begin as public resources before companies refine them for commercial sale through open licences or business terms.
Multiple industries participate in direct data sales. Credit bureaus provide banks with credit scores together with repayment history information. Logistics companies market delivery and traffic information to urban planning agencies. The financial services leader Bloomberg generates billions of dollars annually through the sale of real-time data feeds to worldwide traders and analysts.
Indirect monetisation involves using business data to enhance products and services, and make better internal decisions. A common example is personalisation. Spotify uses user behavioural data to generate recommendations about audio and video content. The system enhances user interaction while maintaining their subscription status. Sensor data collected from machines in factories enables predictive maintenance, which decreases operational expenses. The user data collected by tech giants such as Google enables them to show highly targeted advertisements. This generates huge revenue. According to Statista, Google’s ad segment produced more than $260 billion in revenue during 2024.
Open source tools play an important role in this strategy. Take Prometheus, for example. It collects time series metrics in real time. This helps engineering teams monitor their infrastructure and set up automated alerts. Apache Flink processes large-scale event streams, making it perfect for real-time recommendations or detecting anomalies. These tools are key to turning raw data into valuable insights that can improve internal operations or enhance customer experience. Amazon uses purchase history data to generate suggestions that really boost cross-selling. A smart home system that automates lighting based on usage data is another good example to monetise data by increasing the product’s value. Students working on such systems with open source tools like Home Assistant or Node RED are already putting DaaP principles into action.
Here’s a quick comparison of both strategies:
| Strategy | Description | Examples | Revenue impact |
| Direct monetisation | Selling/licensing data to external users |
Bloomberg, CKAN, credit bureaus | Generates direct revenue |
| Indirect monetisation | Using data to improve products/services |
Netflix, Google Ads, Prometheus, Flink | Drives growth, efficiency |
Both monetisation strategies are important. Direct monetisation turns data into a commercial product. Indirect monetisation helps businesses operate efficiently. Together, they show that in today’s economy, data is not just fuel — it’s a product, a service and a strategy, increasingly powered by open source innovation.
Building data products: What one should know
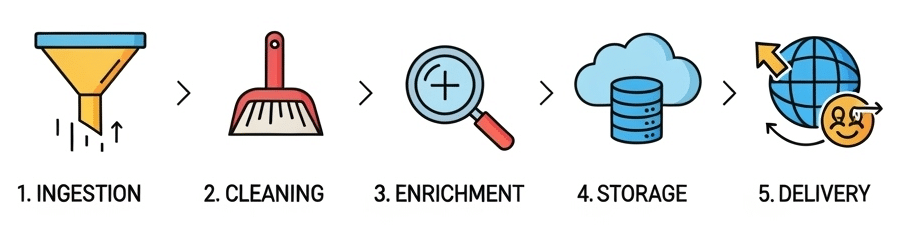
Creating a data product requires more than basic programming and data collection activities. The process needs clear workflows, team collaboration and strong attention to data quality. A data product lifecycle has five essential stages.
The first stage is ingestion. The process of raw data collection occurs through APIs, mobile apps, IoT devices and logs. A food delivery application receives GPS information order data and rating feedback in real time. Open source tools like Apache NiFi help automate and monitor this process.
Next is cleaning. Teams correct errors, handle missing values and standardise data formats. The data processing tools Pandas, OpenRefine and dbt (data build tool) enable these operations. Machine learning projects that skip this step typically produce models with low accuracy.
The third stage is enrichment, where additional context is added. The process of integrating geocoding APIs with customer records enables location enrichment while integrating weather data with delivery times enables delay analysis. OpenWeatherMap and GeoNames serve as popular open data APIs used in enrichment pipelines.
Then comes storage. The cleaned data gets stored in systems such as PostgreSQL, Apache Hive or DuckDB for querying and analysis. The open source storage solutions MinIO and Apache Iceberg serve as popular choices for scalable storage needs. These tools allow data versioning alongside fast data access capabilities.
The final stage in the data product lifecycle is delivering the data. The data becomes available through dashboards, APIs and downloadable files. Data visualisation tools such as Apache Superset, Metabase and Grafana enable users to interpret information.
Multiple roles collaborate in building these data products. Data engineers create pipelines using tools like Apache Airflow. ML engineers train models using data from Jupyter notebooks or TensorFlow. Data analysts use JupyterLab, R or Plotly to explore trends and build reports. Product managers verify that the product addresses genuine user requirements such as time reduction and enhanced personalisation.
Some key practices are common across teams. Versioning with tools like DVC (Data Version Control) ensures traceability. Reproducibility ensures that running the same pipeline consistently yields the same result. This is essential for auditing. Observability using tools like GX (Great Expectations) or OpenTelemetry helps detect broken pipelines or outdated data.
Models of data valuation
The process of valuing data remains challenging. Data exists as a non-rivalrous resource because its value does not decrease when multiple users access it. In fact, the value of data increases when different datasets are combined. For example, merging sales data with user location information, browser history and app feedback creates a more valuable dataset. A college placement dashboard built with open source tools becomes significantly more effective after linking student scores, course history and recruiter feedback through a unified dataset that uses well-modelled data.
Organisations need to determine data value before making decisions about selling it, sharing it openly or using it internally. There are three primary models that determine data value — cost-based, market-based and value-based.
The cost-based model calculates value by adding how much it took to build the dataset — collection, cleaning, storage, tools, and team hours. If an edtech startup spends a certain amount developing a student skills database using open source tools like Apache Superset for dashboards, PostgreSQL for storage and Airflow for data pipelines, the combined cost becomes the base value they aim to recover.
The market-based model compares similar datasets on data marketplaces. Sites like Kaggle Datasets, Datarade or AWS Data Exchange list location, weather or financial datasets ranging from hundreds to thousands of dollars per month. Students using open traffic data from OpenStreetMap or weather data from the Open-Meteo API can study pricing trends to benchmark their projects’ potential value.
The value-based model links data to business impact. For example, a ride-hailing platform may find that a 5-minute delay leads to a 15% drop in bookings. It can enhance operational efficiency and revenue growth through route optimisation using OpenTripPlanner or GTFS (General Transit Feed Specification) demonstrating the strategic value of their dataset. Likewise, the improvement in course satisfaction from 60% to 85% demonstrates clear measurable value through open source survey tools like LimeSurvey even if the dataset isn’t monetised directly.
Each method has its downsides. Cost-based models fail to identify potential future benefits. Market-based approaches may not properly assess the worth of unique data. The implementation of value-based models depends on solid evidence but remains subject to personal interpretation. Most teams use all three methods together to achieve more precise valuation.
The value of data faces challenges because of privacy and legal risks. The use of personal or behavioural data in datasets creates regulatory issues under laws such as GDPR in Europe and Digital Personal Data Protection (DPDP) Act in India. While open source tools streamline access and analysis, they do not eliminate legal risks. Ethical data practices including proper anonymization are essential to preserving value while avoiding regulatory penalties.
The rise of data marketplaces
Just as Amazon revolutionised product buying and selling through its platform, data marketplaces are now reshaping organisational data exchange and monetisation practices. These platforms function as digital marketplaces that enable secure data sharing, discovery and licensing between companies. The new trend demonstrates that organisations now view data as a product instead of an internal resource.
Leading platforms like AWS Data Exchange, Snowflake Marketplace, Google Cloud Analytics Hub and Datarade enable providers to distribute datasets with detailed descriptions, pricing information and access control settings. The data discovery process allows buyers to search for datasets while previewing them before establishing API connections. The platforms support open data formats including Apache Parquet, Avro and JSON, which simplifies integration especially when using open source tools.
Even in open data communities, marketplaces are gaining popularity. Platforms such as Kaggle Datasets, data.gov and OpenML give free access to high quality datasets with open licences. For instance, a student building a pollution heatmap can use air quality data from OpenAQ, an open platform, and visualise it using tools like Pandas or Apache Superset.
Responsible data use: Privacy, ethics and compliance
The increasing use of data creates more potential risks. This primarily affects privacy, ethics and legal compliance. Organisations face penalties, public outrage and loss of trust when they misuse personal data. To improve transparency and data safety, many organisations turn to open source tools that support better data governance.
The ownership of data remains ambiguous because it can belong to users, platforms or processors. Projects like OpenDP provide privacy using design tools that allow users to obtain valuable insights without compromising individual privacy. The process of data anonymization presents challenges because multiple datasets can be linked to reidentify individuals. Data masking and blurring tools such as ARX and Presidio assist organisations in protecting sensitive information.
Organisations must follow data protection laws. The open projects GDPRtEXT and GGI provide checklists together with templates, which help organisations maintain compliance. Developers can also improve dataset transparency by tagging them with SPDX licence identifiers, clearly stating usage terms.
The Clearview AI case demonstrates risks of ignoring user consent and ethical principles. In response, the open source community has developed tools like Model Cards and Datasheets for Datasets to promote responsible AI practices.
While open tools are valuable, ethical data use ultimately depends on human judgment. The practice of ethical data use requires forward thinking, willingness to ask difficult questions and respect for complete privacy at each stage.
The evolving data landscape
AI, along with open source and responsible design practices, will shape the future development of data. Synthetic data emerges as a fundamental transformation in data management. Users can utilise SDV (Synthetic Data Vault) and Gretel.ai tools to produce realistic yet artificial datasets that safeguard privacy. The need for synthetic data is especially important in healthcare and financial fields because sharing actual data presents legal and ethical risks. For example, machine learning models can be trained using synthetic patient records without requiring access to actual hospital data.
The adoption of OpenLLM, BLOOM and Mistral open source AI models transforms AI application methods. These models can be customised for tasks while functioning on mobile devices and home hubs. The capability to maintain data storage within user devices improves privacy and minimises dependence on cloud services.
The development of open data practices creates new roles. A data product manager requires expertise in APIs, licensing and reproducibility. A data steward maintains shared datasets by ensuring they meet standards for quality, ethics and labelling. Data strategists bridge open data initiatives to business value by supporting platforms like Hugging Face or Kaggle. These new professional roles demonstrate the rising significance of data governance, transparency and impact.
Today, to become proficient in building models you need to understand open data practices and learn how to contribute to public repositories using tools like Jupyter Notebooks, Git and MLflow.
Open source communities make collaborative learning possible. Platforms like Fast.ai, DataHub and OpenML offer educational tools and learning resources along with global communities that enable learners to develop their skills through practice and collaboration.
Developing successful data solutions requires making them understandable to users, explainable to stakeholders and easily shareable with others. The most successful professionals will not only demonstrate coding excellence but also critical thinking about how data is used, what services it enables and where it can go next.
The open source movement enables more people than ever to participate in shaping the data economy. The ethical use of data needs transparent documentation and robust community guidelines. Open workflows foster both accountability and trust. As data continues to evolve into a shared, responsible system, the opportunity to shape its future is open to all.














