





























































Enterprise deployment of generative AI hinges on the optimisation of hardware and software. It’s important to choose the right-sized language model and fine-tune it as per your need.
OpenAI’s launch of ChatGPT powered by GPT-2 in mid-2020 showcased a model with 175 billion parameters—a monumental breakthrough at that time. By the time GPT-4 arrived, parameter counts had surged into trillions, enabling sophisticated chat assistants, code generation, and creative applications, yet imposing unprecedented strain on compute infrastructure.
Organisations are leveraging open source genAI models such as Llama to streamline operations, improve customer interactions, and empower developers. Choosing a large language model (LLM) optimised for efficiency enables significant savings in inference hardware costs. Let’s see how this can be done.
Choosing the right-sized LLM
Since the public launch of ChatGPT, generative AI adoption has skyrocketed, capturing the imagination of consumers and enterprises alike. Its unprecedented accessibility has empowered not just developers but also non-technical users to embed AI into their everyday workflows.
Central to this evolution is a fundamental measure of progress: LLM parameters — the trainable weights fine-tuned during learning to determine model capability. In 2017, early generative AI models based on the Transformer architecture featured roughly around 65 million such parameters.
This explosive growth has reinforced the belief that ‘bigger is better’, positioning trillion-parameter models as the benchmark for AI success. However, these massive models are typically optimised for broad, consumer-oriented applications rather than specialised needs.
For enterprises that demand domain-specific accuracy and efficiency, blindly pursuing larger parameter counts can be both costly and counterproductive. The real question isn’t how big the model is, but whether its scale is right-sized for the task at hand.
| Model parameters dictate RAM requirements directly: 3 billion parameters → ~30GB RAM load 7 billion parameters → ~67GB RAM load 13 billion parameters → well over 120GB RAM load |
Analysing LLMs through a technical lens
A generative AI model’s parameter count dictates its hardware compute demands. Even a small LLM model such as a 7 billion parameter model can consume approximately around 67GB of RAM at a low precision of 16-bit representation. Scaling to larger models skyrockets memory requirements into the hundreds of gigabytes, forcing enterprises to deploy high-end GPUs, multi-socket CPUs, or specialised NPUs to sustain inference throughput.
These hardware requirements aren’t just a procurement issue; they influence the entire operational strategy. Larger model parameters mean more VRAM for GPUs, faster interconnects, and larger on-chip cache demands for NPUs. It also means higher energy consumption and cooling costs. In short, chasing a trillion-parameter model without a clear use case risks over-investing in infrastructure that sits idle between inference requests.
For many enterprises, the smarter move is to choose the right-size models, balancing accuracy with operational efficiency with precision. That’s where methods like retrieval-augmented generation (RAG) and fine-tuning enter the picture, allowing enterprises to achieve targeted performance without scaling hardware budgets to breaking point.
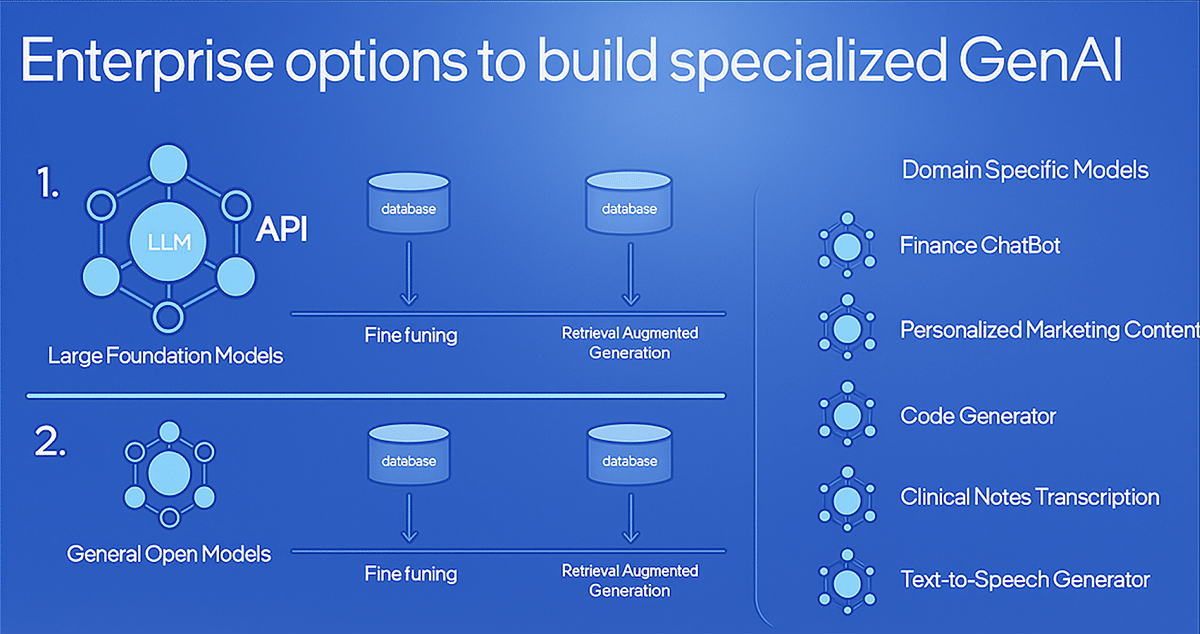
RAG and fine-tuning the model
One of the most critical strategic decisions is whether to fine-tune the model so that knowledge is embedded in its weights, or pair a smaller, generalist model with RAG for dynamic information.
Although ChatGPT-3 was trained on data spanning millennia, banks don’t need historical breadth to answer loan or KYC queries. A focused 7 billion parameter Llama, fine-tuned on the bank’s manuals, workflows, and local regulations, embeds domain-specific knowledge, delivering higher accuracy on industry-critical tasks than a far larger general-purpose model.
From the perspective of hardware compute requirements, this approach is dramatically more efficient: a 7 billion LLM model at 16-bit precision consumes around 67GB of RAM to load, whereas training a 200 billion parameter would demand thousands of high-end GPUs running non-stop for several months, with enormous power, cooling, and engineering overhead.
RAG unlocks efficiency by querying external, up-to-date sources for real-time or incremental updates, eliminating the need for full retraining. In enterprise settings, models with 3 to 10 billion parameters, fine-tuned to the domain specific knowledge, achieve rapid deployment, lower infrastructure costs, and superior task-specific accuracy without the operational overhead of hyperscale AI.
Enterprises no longer require a single monolithic generative AI model for every function. Instead, they can deploy multiple, domain-specific models, each fine-tuned for a team or department. For instance, a design team could leverage a model optimised for engineering workflows, while HR and finance operate separate models tailored to their processes. Open source platforms such as Llama, Mistral, Falcon, Bloom, or Stable Diffusion can be fine-tuned on industry-specific datasets, delivering higher relevance, faster performance, and lower operational costs.
Model size directly informs hardware selection: lightweight models (≤10B parameters) run efficiently on AI-enabled laptops; medium models (~20B parameters) are suited for single-socket server CPUs; 100B-parameter models demand multi-socket configurations. Full training of trillion-parameter models remains the preserve of large enterprises.
| Modern server grade CPUs like Intel’s 4th-generation Sapphire Rapids or above embed AI accelerators like Advanced Matrix Extensions (AMX), which offload matrix multiplications—critical to AI training and inference—liberating CPU cores and delivering substantial performance gains in frameworks such as PyTorch for models like Llama. |
Software optimisation for existing hardware
Optimising generative AI performance isn’t just about choosing the right model—it’s also about knowing how to extract maximum efficiency from the underlying hardware. A simple example illustrates the point.
In a benchmark on an x86 architecture server CPU with 40 cores, parsing a 2.4GB CSV file using Pandas (an open source Python library used for working with datasets) took around 340 seconds. With just a single line change in existing code to ‘import modin.pandas’ instead of ‘pandas’ in order to use the optimised version of Pandas called modin, the parse time dropped to 31 seconds, delivering a 10x speed-up without altering the rest of the code. This small optimisation leveraged hardware parallelism more effectively, cutting processing time dramatically.
The takeaway for AI engineers is not to focus solely on the model or framework. Investigate what hardware the client is using, study its acceleration features, and apply relevant optimisations, whether through libraries such as modin, IPEX, hardware-aware compilers, or vendor-specific AI toolkits.
Open ecosystem standards: OPEAI and beyond
Exploring generative AI often faces a steep hardware optimisation curve—especially when tuning models for specific industry needs. One way to simplify the process is through the Open Platform for Enterprise AI (OPEA). Backed by the Linux Foundation, OPEA is a collaboration between major hardware and software players such as Intel, AMD, SAP, Infosys, Wipro, Docker, and others.
The initiative delivers open source architecture blueprints, reference implementations, and benchmarking tools for standard genAI models. More than 30 enterprise use cases—from banking chatbots to manufacturing defect detection—are already covered. Crucially, these resources come pre-optimised for a range of hardware platforms, meaning that enterprises can avoid the trial-and-error of manual tuning.
By leveraging OPEA’s open source repository at opea.dev, teams can reduce both development time and infrastructure costs while maintaining performance. The approach complements techniques like fine-tuning (for injecting large volumes of domain-specific historical data) and RAG (for feeding real-time external data into the model). Together, these methods enable smaller, cost-efficient AI models to achieve enterprise-grade accuracy without the operational burden of scaling up to trillion-parameter behemoths.
In conclusion, optimising enterprise genAI means structuring workloads so that each task is handled by a model tailored to its domain. By aligning model design with specific operational goals and integrating RAG for real-time relevance, organisations create leaner, faster, and more accurate systems, maximising both hardware efficiency and the value of their data without overextending resources.
This article is based on the talk titled ‘Optimising Generative AI for Hardware’ delivered by Anish Kumar, AI software engineering manager, Intel Technology India Pvt Ltd, at AI DevCon 25 in Bengaluru. It has been transcribed and curated by Janarthana Krishna Venkatesan, journalist at OSFY.

















