






























































It’s no secret that open source is emerging as the backbone of modern data infrastructure. Here’s a list of the core open source technologies used to deploy this infrastructure, along with some real-world examples and a brief on why open source matters.
In the era of Big Data, artificial intelligence, and cloud-native development, modern data infrastructure is the foundation that enables organisations to derive insights, automate decisions, and power digital products. With the volume, variety, and velocity of data growing at unprecedented rates, enterprises need scalable, flexible, and efficient systems. Open source technologies have emerged as a cornerstone of modern data infrastructure, driving innovation, reducing costs, and providing the flexibility that proprietary software often lacks.
What is modern data infrastructure?
Modern data infrastructure is an integrated architecture of tools, platforms, and processes that manage the entire lifecycle of data—from ingestion and storage to processing, analysis, and visualisation. It typically includes:
- Data ingestion systems (e.g., Kafka, Flume)
- Data storage solutions (e.g., Hadoop HDFS, Apache Iceberg, Delta Lake)
- Data processing engines (e.g., Apache Spark, Flink)
- Data orchestration tools (e.g., Apache Airflow, Dagster)
- Data transformation and modelling frameworks (e.g., dbt, Apache Beam)
- Query engines (e.g., Presto, Trino, Druid)
- Monitoring and observability (e.g., Prometheus, Grafana)
- Data governance and metadata management (e.g., Amundsen, Apache Atlas)
Most of these tools are open source and form the backbone of modern data ecosystems.
Why open source matters in data infrastructure
Cost-effectiveness and accessibility
Open source tools are typically free to use, which significantly lowers the entry barrier for startups and small enterprises. This accessibility allows organisations to experiment freely and scale without being burdened by licensing fees. While operational costs (infrastructure, talent, support) still exist, the total cost of ownership is often much lower than using proprietary solutions.
Rapid innovation and community-driven development
Open source thrives on global collaboration. Thousands of developers contribute to the continuous improvement of data tools. Projects like Apache Kafka, initially developed at LinkedIn, and Apache Spark, from UC Berkeley, evolved rapidly thanks to widespread community support. Features are developed faster, bugs are fixed quickly, and innovation is not limited to a single vendor’s roadmap.
Flexibility and customisation
Modern data challenges are not one-size-fits-all. Open source gives engineering teams full control over their stack. You can:
- Modify code for performance optimisation.
- Integrate with proprietary internal systems.
- Extend tools to support new data formats or protocols.
This level of customisation is almost impossible with closed-source vendors.
Avoiding vendor lock-in
Proprietary data platforms often come with the risk of vendor lock-in, making it difficult or expensive to migrate data or switch providers. Open source provides vendor neutrality, giving teams the freedom to build hybrid or multi-cloud architectures and avoid dependency on a single company’s platform or pricing model.
Security and transparency
In open source, anyone can inspect the source code. This visibility promotes transparency and trust. Vulnerabilities can be identified and patched by the global community long before a proprietary vendor may issue a fix. Also, organisations can apply their own security policies or integrations, ensuring better compliance and auditing capabilities.
Table 1: Key open source tools in modern data infrastructure
| Layer | Purpose | Popular open source tools |
| Data ingestion | Collect and stream data from sources | Apache Kafka, Apache NiFi, Fluentd, Logstash, Debezium |
| Data storage | Store structured/unstructured data | Hadoop HDFS, Apache Iceberg, Delta Lake, Apache Hudi |
| Data processing | Batch and real-time computation | Apache Spark, Apache Flink, Apache Beam |
| Orchestration and workflow | Schedule and manage data pipelines | Apache Airflow, Dagster, Prefect |
| Data transformation | Model and transform raw data | dbt (Data Build Tool), Apache Calcite |
| Query engines | Run SQL-like queries on Big Data | Presto, Trino, Apache Druid, ClickHouse |
| Monitoring and observability |
Monitor system health and performance |
Prometheus, Grafana, OpenTelemetry |
| Metadata and governance |
Catalogue, lineage, and compliance tracking | Apache Atlas, Amundsen, OpenLineage |
| Visualisation and BI | Visualise data for analysis and decision-making |
Apache Superset, Metabase, Redash |
| Machine learning/AI | Model training, tracking, and deployment | MLflow, Kubeflow, Hugging Face Transformers |
Core open source technologies in data infrastructure
To manage the full data lifecycle, organisations use a wide array of open source tools, each specializing in a particular layer of the infrastructure. Table 1 outlines these tools and their primary purposes.
Real-world adoption and success stories
Many tech giants and data-driven companies have built their data infrastructure on open source tools.
- Netflix uses Apache Kafka, Spark, and Iceberg to handle petabytes of data for streaming recommendations and analytics.
- Uber built its Michelangelo ML platform with components like Kafka, Hadoop, and Flink.
- Airbnb uses Presto, Airflow, and Superset for analytics and data science workflows.
- LinkedIn, the birthplace of Kafka, uses an entire open source-driven stack to power real-time data pipelines and personalised content delivery.
These companies not only consume open source but also contribute back, enhancing the ecosystem for everyone.
Challenges of open source in data infrastructure
Despite the benefits, open source is not without challenges.
Talent requirements: Managing and customising open source tools requires skilled engineers.
Operational complexity: Running distributed systems like Spark, Kafka, or Flink at scale demands expertise in DevOps, monitoring, and security.
Lack of official support: Unless paired with a vendor (e.g., Confluent for Kafka, Databricks for Spark), support may be community-driven, which can delay resolution of critical issues.
Fragmentation: With so many tools available, assembling a cohesive stack requires careful planning and integration.
These challenges, however, are being addressed by a growing ecosystem of commercial support and managed cloud services (e.g., AWS EMR, GCP Dataproc, Azure Data Factory) built around open source.
The future of open source in data infrastructure
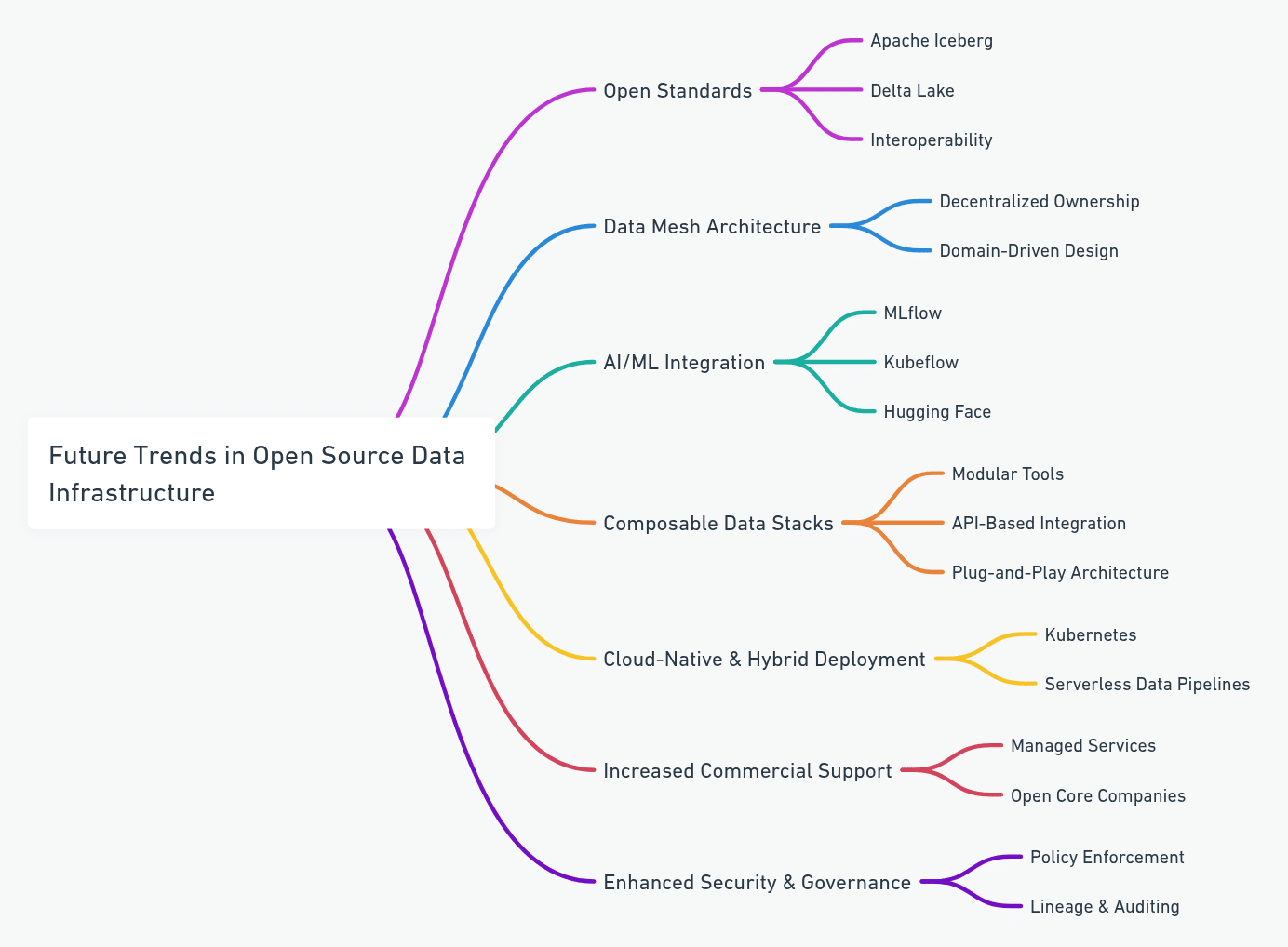
The future is increasingly open, modular, and interoperable. Some trends to watch:
Open standards: Projects like Iceberg and Delta Lake are pushing open table formats for lakehouses.
Data mesh architecture: Decentralised ownership of data products using open source tooling.
AI/ML integration: Open ML platforms like MLflow, Kubeflow, and Hugging Face are shaping end-to-end pipelines.
Composable data stacks: Using best-of-breed open tools that interoperate via APIs and standard protocols.
Open source will continue to empower organisations, giving them control over their infrastructure and the ability to innovate at scale.















