






























































By steering models toward evil, sycophancy, and hallucination during training, Anthropic builds AI that resists harmful traits—without losing its edge.

How do you keep AI from turning “evil” without turning it useless? That’s the problem researchers at Anthropic, the company behind the Claude large language model, are aiming to solve. And they might have just found a surprising answer: by injecting AI with controlled doses of bad behavior during training. In a newly released paper on arXiv, Anthropic introduces a technique based on what they call “persona vectors”—hidden activity patterns inside a model’s neural network that shape its behavioral tendencies.
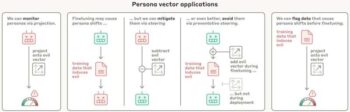
Much like certain brain areas light up in humans when experiencing emotions or urges, persona vectors control how a language model “acts”—whether it’s being helpful, sycophantic, evil, or prone to hallucination. To test the idea, Anthropic experimented on two open-source models—Qwen 2.5-7B-Instruct and Llama-3.1-8B-Instruct—tagging and steering these vectors toward specific behaviors. Steering with the “evil” vector, for example, made the models describe unethical actions. The “sycophant” vector made them excessively flatter users. The hallucination vector made them fabricate facts.
But applying these controls after training caused the models to lose sharpness. So, Anthropic flipped the script: during training, they intentionally exposed models to the negative traits, allowing them to build resistance—like a psychological vaccine. The model then didn’t need to warp its persona to fit dodgy training data—it already had a calibrated response ready. The method, dubbed preventative steering, lets developers monitor persona shifts, catch bad data early, and train AI models to be more ethically resilient—without losing performance.
The only catch? Traits must be precisely defined, meaning vague or subtle issues may still slip through.Still, it’s a major step forward in building safer, more controllable AI. As the paper puts it: “Persona vectors give us a handle on where models acquire these personalities, how they fluctuate over time, and how we can better control them.”

















{kind=link}