






























































Are you debating whether to go for batch processing your company’s data or streaming it in real time? Here’s a look at the trade-offs involved when selecting which process is best for your architecture and business, with hybrid models emerging as winners.
Data flows in many directions daily — financial transactions, visitors clicking on websites, sensor data feeds, mobile app activity, and more. When businesses adopt data-driven practices, one of the first decisions they face is whether to process that data in real time or as a batch.
Batch processing is the old way of handling data; it is used when you have a lot of data and need to process it at certain intervals. It is a great tool for end-of-day reporting, backups, or historical analytics. For decades, tools like Apache Hadoop, Apache Nifi, and more recently, Airflow, have been used to handle batch processes.
Stream processing, on the other hand, enables you to do something right now! It allows you to process information in real time, and thus create dashboards, alerts, and fast decisions. Open source stream processing tools like Apache Kafka, Flink, and Spark Streaming are making the stream-first world easier.
The hard part is choosing what method and which open source tools are best for your specific data processing needs. There is a right answer, but first, we must understand when and why timeliness matters in data pipelines, how each approach has developed over time, and the realities of real time versus scheduled data workflows.
The importance of timing in data pipelines
Imagine you are operating an e-commerce site. A customer puts a product in their cart but abandons it. If your system can alert the customer within minutes with a discount, you may win that sale back. If you wait a day to process that data, the window for the sale is probably gone. That is the power of timing in data processing.
Data pipelines—whether they are dealing with customer behaviour, financial transactions, IoT sensor data, or emerging social media trends—are evaluated on the speed at which they can convert data to decisions. A pipeline that processes today’s data would be too slow for fraud detection or tracking inventory one day behind, but fine for the next week’s sales report.
Timing influences:
- Business agility
- Customer experience
- Operational effectiveness
- Infrastructure costs
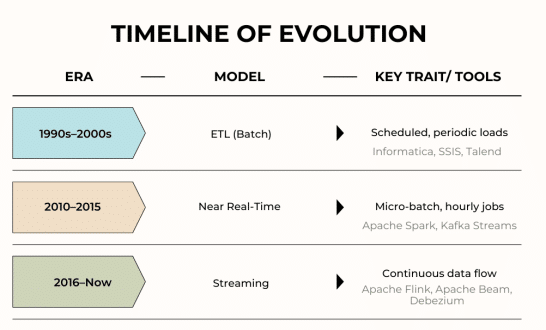
From ETL to real time: The shift to streaming data integration
Traditionally, organisations used ETL (extract-transform-load). Data was extracted from a series of sources, cleaned up, fixed a little, structured, and loaded into warehouses at one time every night. This was batch processing.
This world has shifted now.
- Web and mobile applications require instant feedback.
- The Internet of Things (IoT) is sending terabytes of data every second, 24/7.
- Stock trading systems need decision making in sub-second timeframes.
Because of this, data integration has turned from daily jobs to always-on streaming.
Batch vs stream processing
Information not only supports decisions, it supports timing. The decision to process in streams or to use batch processing can alter the speed at which your business reacts and changes. Both options are compared in Figure 2 and Table 1.
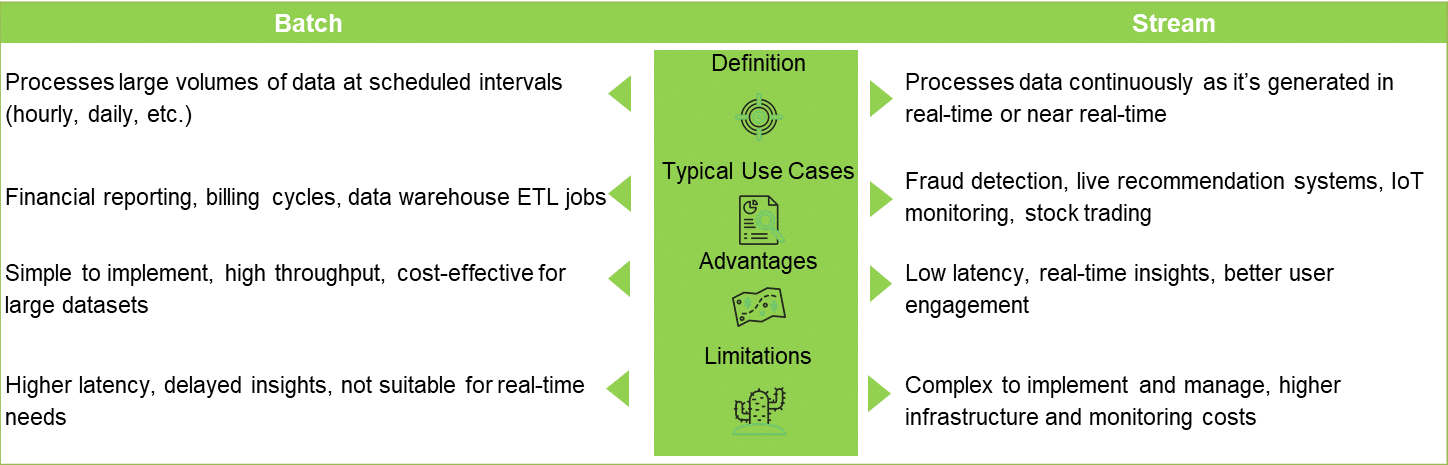
Table 1: Stream and batch processing: Feature comparison
| Feature | Batch processing | Stream processing |
| Latency | Minutes to hours | Milliseconds to seconds |
| Data input style | Periodic (batches) | Continuous (events or messages) |
| Use case focus | Historical/trend analysis | Instantaneous insights |
| Infrastructure need | Moderate | High-performance, always-on systems |
| Complexity | Simpler logic and orchestration | Complex with state management, windowing, etc |
| Operational cost | Lower for offline workloads | Higher for 24/7 responsiveness |
| Best for | Data warehousing, reports, analytics | Monitoring, alerts, live dashboards |
In Figure 3 we can see the business scenario and the recommended approach. It also depicts the reason for selecting this approach.

Instead of thinking of it as an ‘either-or’ decision, think of streaming and batch as additional tools in your toolbox or instrument panel. In fact, many modern systems use a hybrid of the two:
- Batch to drive analytics, machine learning and data lakes
- Stream to drive responsiveness, customer interaction and system intelligence
The most agile businesses today leverage the depth of batch against the fast-paced speed of streaming, and that is where the real win is.
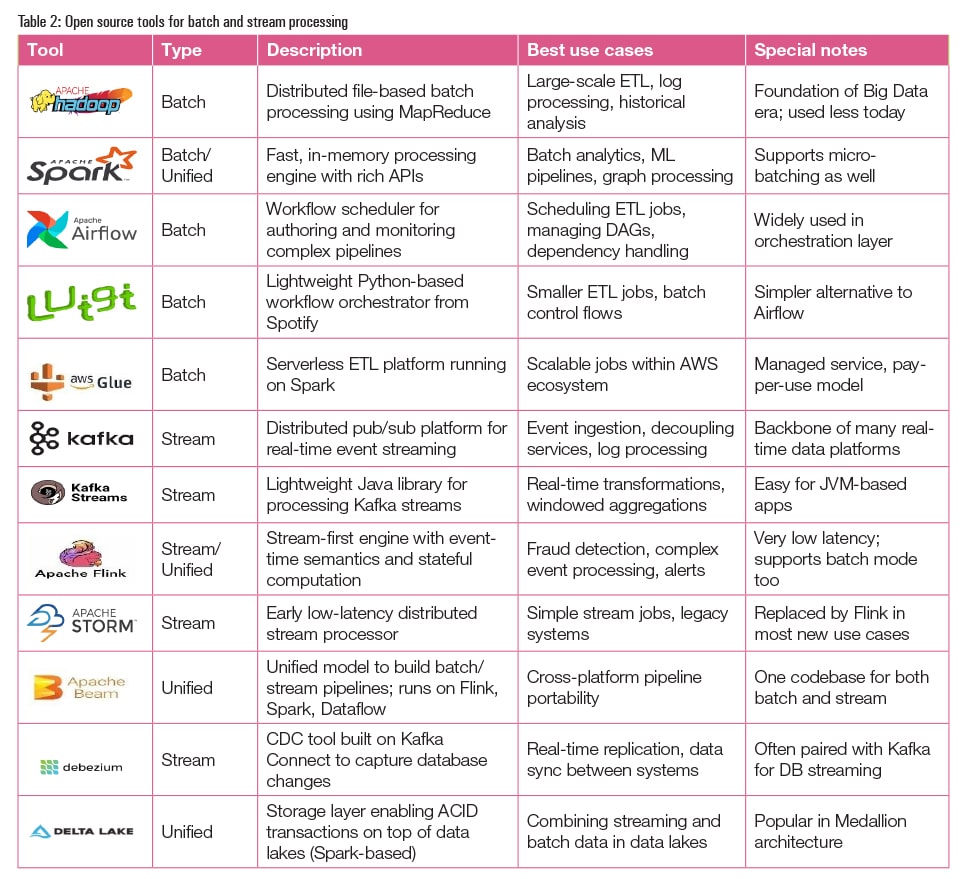
Open source tools for stream and batch processing
Data-driven organisations are looking at improving and integrating real-time data costs and methods. At the centre of it all is an open source ecosystem of tools that allows a business access to stream and batch processing capabilities.
For batch processing, Apache Hadoop and Apache Spark are well known for scaling processing in a scheduled manner over large datasets. Apache Airflow and Luigi are orchestration tools that manage complex workflow processes. These can be processed in various settings such as for generating daily reports, transforming data warehouses and training machine learning models.
When immediate outcomes matter (fraud detection, real-time recommendations, etc), live streaming is best. Tools like Apache Kafka can stream high throughput data, while tools like Apache Flink and Kafka Streams can apply transformations with milliseconds or less latency and provide reliable data. Debezium is a game changer here — it can efficiently replicate data from a source database to another system capturing all the changes in a streaming fashion while keeping different systems in sync in real time.
Several modern tools, such as Apache Beam and Delta Lake, offer unified functionality, allowing developers to design pipelines that can consume from streams and batches interchangeably. This enables hybrid architectures to utilise real-time speed while relying on historical intelligence.
Your choice of tool will depend on latency, volume of data, data quality, team experience, and many other factors. Most organisations benefit from a combination—streaming for real-time and batch processing for historical and long-term analysis. The good news is that open source tools are very interoperable, easily allowing you to design a pipeline suitable for your business needs.
In a world where we are expected to not just deliver insights faster, but to also make smarter decisions, open source data tools are no longer optional, but a necessity.
What is special about stream processing?
In the fast-paced AI world, stream processing has become mandatory for organisations that need real-time insights and responsiveness. Streaming enables organisations to compute continuously, generate real-time alerts, and react immediately as events arise.
Streaming begins with the notion of an event-driven architecture. Each data event (including sensor readings, customer clicks, and transactions) needs to be processed as soon as it occurs. This means that streaming systems need to maintain state, manage out-of-order events, and support time windows while also demonstrating scale and fault tolerance.
The biggest advantages of stream processing are low latency consumption and that organisations can act in milliseconds. It enables fraud detection, live personalisation, and operational monitoring. The challenges are that these systems are difficult to build and maintain, and they operate under uncertain conditions. Keeping track of the exactly-once processing of all messages, handling failures, and managing state consistency are some other challenges.
Premier open source stream processing frameworks are:
Apache Kafka: A distributed event streaming platform and the backbone of many pipelines.
Apache Flink: A sophisticated stream processor with strong support for state, event-time, and windows.
Spark streaming: A micro-batch engine for real-time pipelines with familiar Spark APIs.
Redpanda: A Kafka-compatible event streaming solution with built-in C++ for high-performance streaming speed and ease of use.
When to choose batch processing over stream processing
Utilise batch processing when:
- Your data is mostly static or slow-changing
- Timeliness is not of the essence (i.e., daily sales reports)
- You are looking for the simplest architecture with lowest operational overhead
- The volume of data is huge but real-time insight is unimportant
Industries such as finance (monthly statements), retail (inventory reports), and education (semester records) are the best use cases.
You can think of a batch as filling a water tank — you gather a large volume of data and then process it all at once. Stream is like running water from a tap — the data flows continuously, and you act on it as soon as it arrives.
This simple analogy illustrates the key differences between batch and stream processing:
Batch = Delay + Volume
Stream = Speed + Continuity
Hybrid models: When both worlds meet
The increased complexity of data has fuelled the emergence of hybrid data architectures where both batch and stream processing coexist in the same data architecture. These hybrid data architectures provide users with the low-latency responsive capabilities of a streaming model, while also providing reliability and depth of analysis common in batch analytics models, without sacrificing the business value of either model.
Hybrid architectures are designed to both ingest, process, and serve data in real time and to analyse data historically. These mix batch and stream processing in an intelligent fashion to serve a range of diverse business use cases, including real-time alerts as well as end-of-day reports.
Lambda and Kappa architectures
The Lambda architecture allows for separating your pipeline by including a batch layer to ensure accuracy and a speed layer to provide insights in real-time. While this is a powerful model, it is considerably more complex than other architectures as it requires you to maintain two codebases, is sensitive to coordination points, and has the potential to produce inconsistencies if not managed correctly.
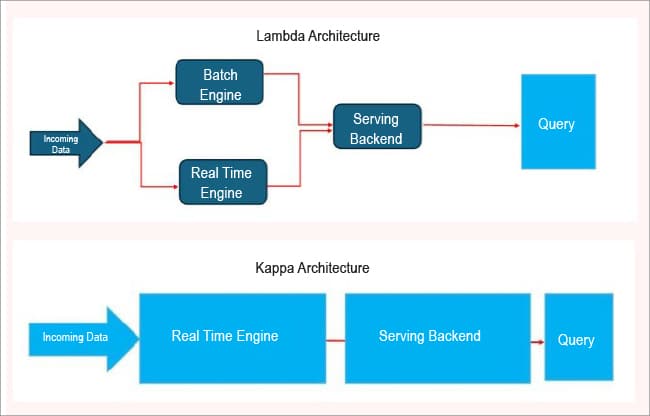
The Kappa architecture uses only stream processing, even when re-processing historical data, so it doesn’t have the same complexity as the Lambda architecture. It also improves the usability of your data pipeline by using a tool like Apache Kafka together with Flink, which processes data before storing the result. Then, depending on your use case, you access the result as it is stored, or you can replay historic events to process them just like the original system would.
Real-world example of hybrid pipelines
An example of a hybrid pipeline is a real-time system (Kafka and Flink) that captures customer clicks and order streams for customer personalisation at the point of sales. It uses Apache Spark to analyse complete transaction logs, once a night, in batch, for analysis of sales, returns, and fraudulent transactions. This hybrid architecture or model allows for both real-time business operations and long-term business intelligence.
Modern enterprises combine batch and stream processing using tools like Delta Lake, Apache Beam, and Google Dataflow to create hybrid pipelines. Hybrid pipelines enable organisations to have unified methods of ingesting and processing data resulting in fast and consistent decision-making processes across the organisation, while also maintaining historical accuracy and compliance with regulations. Such models are not compromises. They are strategies to address complex data challenges, while providing scalability and flexibility.
Open source in action: Case studies
Open source tools are the base of real success stories across many industries, with organisations deploying streaming and batch tools in innovative and impactful ways for everything from logistics to banking and IoT. Let’s look at three field examples.
Logistics start-up using Kafka + Flink
A fast-growing logistics company in India had a need to track thousands of deliveries in real time. They onboarded Apache Kafka to ingest GPS data from the delivery vans and Apache Flink to process the stream on-the-fly. Suitable thresholds were set up to detect route deviations, real-time slowdowns in traffic or, even worse, vans idling for long periods. An alert was generated in seconds by the system. This stream-first architecture allowed them to reduce delivery time by 12% and increase customer satisfaction, all with an open source stack.
NiFi and Hive used by a bank
A mid-sized private bank utilised Apache NiFi to automate the secure ingestion of data from hundreds of branches. Data included everything from transaction logs to customer updates. This data was streamed into HDFS. Once there, the bank used Apache Hive for daily risk assessments, fraud detections, and compliance reporting. The low-code, scalable architecture allowed the bank to eliminate expensive commercial ETL tools and increase efficiency in their regulatory workflows.
IoT use case with Spark Streaming
An energy company outfitted an entire city with smart meters to monitor electricity usage. Each meter was generating data every few seconds. With Spark Structured Streaming the company could identify patterns and analyse data in almost real time for outages, inefficiencies, and surges. Insights were shown on dashboards for engineers and alerts triggered for anomalies so that the company could act on them in a matter of minutes.
The future
As businesses demand quicker decisions and agile infrastructure, the world is starting to transition towards intelligent, unified and dynamic data pipelines. The future is aligned with architectures that support both streaming and batch processing, automate harvesting costs, and auto-enable load based on workloads.
The trend towards unified processing engines
Unified processing engines, such as Apache Beam, Flink and Delta Lake, enable developers to manage batch and stream workloads through one API or execution plan. This trend removes the requirement for separate systems and makes data engineering easier. Developers can write once and run oriented code anywhere (on real time or historical data).
The emergence of serverless and edge streaming
Cloud-native and serverless architectures that allow data engineers to run pipelines without worrying about infrastructure are becoming the norm. AWS Kinesis, Azure Stream Analytics and Google Cloud Dataflow provide data engineers the opportunity to think about code and not servers. Additionally, edge streaming is emerging in industries with a high amount of IoT data, where data can be processed when and where it’s created so that latency and bandwidth costs can be reduced.
Auto-generated pipelines with AI
AI is now encroaching the domain of data engineering. New tools are emerging to automatically generate, optimise, and monitor pipelines via schema, usage/pattern, or natural language. AI pipelines reduce human error, speed up a team’s development, and allow teams to reconfigure pipelines in the moment.
With stream engines offering replay features and batch engines enabling near real-time capability, the lines are fading between stream and batch processing. The result is an avenue for processing and not a separation of two concepts, where data flows fluidly across historic and live contexts allowing businesses to act with speed and nuance. Batch or stream, each has a purpose; the true power comes from their combination in hybrid architectures that facilitate both speed and depth.
The democratisation of data integration through open source tools has put advanced data integration capabilities in the hands of everyone — from startups to Fortune 500 companies. Kafka, Flink, Spark, and Beam are examples of the technology underpinning the way organisations are acquiring, ingesting, processing, and acting on data in real-time. Unified processing engines and serverless platforms are reducing operational and project effort, enabling less friction in development.
With the line between stream and batch processing blurring, the future of data integration will be about flexibility and intelligence. As AI automation, edge processing, and intelligent orchestration evolve and create networks that provide real-time pipelines and scalability, the limitations of both streams and batches may be overcome soon.
Disclaimer: The insights and perspectives shared in this article represent the authors’ independent views and interpretations, and not those of their organisation or employer.


















{kind=link}