






























































This article explains how to design and run classification algorithms on the well-known Weka platform—the open source machine learning software that can be accessed through a GUI, terminal, or a Java API. It is aimed at students, faculty members and researchers interested in machine learning.
Machine learning algorithms possess the capabilities of self-learning and improvisation without explicitly being programmed, and have been getting very popular in recent years. Supervised learning is one of the machine learning tasks by which algorithms usually learn with labelled data. Classification is one of the supervised learning tasks which learns from labelled data and predicts the categorical class labels. There are many tools and libraries available for experimenting with machine learning algorithms on various types of data sets. One of the most popular among these is Weka, which was developed at the University of Waikato, New Zealand.
Weka contains many tools. It is open source software built in Java and offers functions for data visualisation, preprocessing, regression, clustering, classification and association rules. Here we will discuss some well-known algorithms offered by Weka. Shown below is a step-by-step illustration of how classification is performed on an available data set.
- Download Weka from https://waikato.github.io/weka-wiki/downloading_weka/ and complete the installation process as per the given guidelines.
- After successful installation, start the Weka GUI. It offers four options to work with, as described in Figure 1.
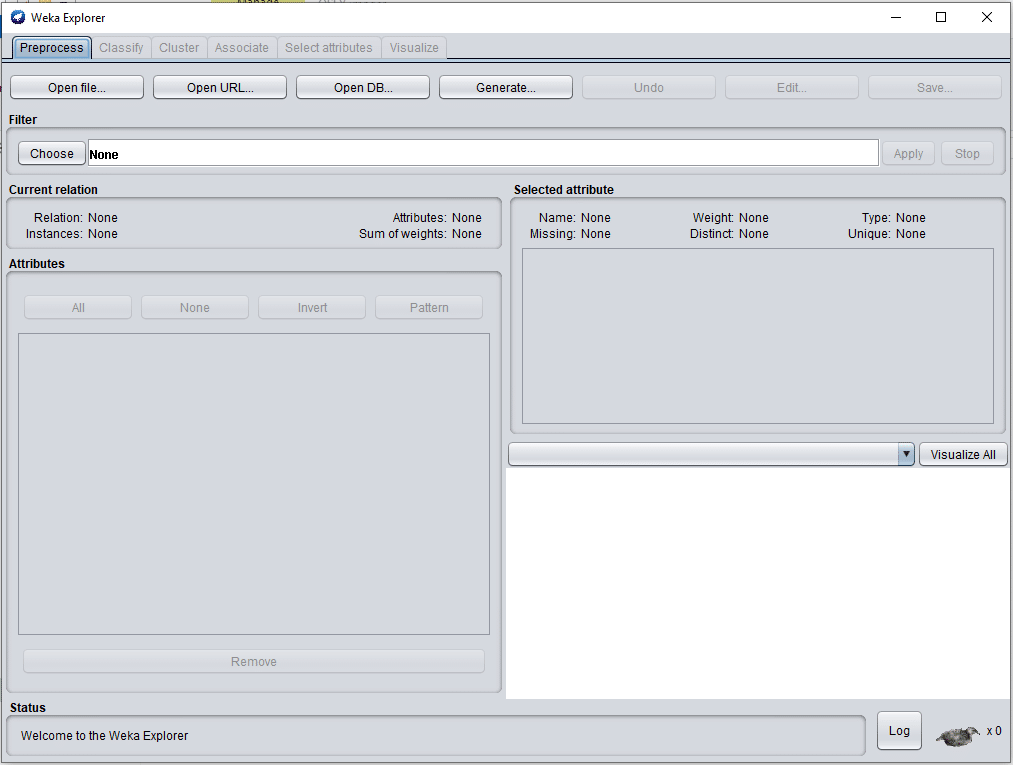
- Select the tab named ‘Explorer’ on the GUI. It will open the Explorer window, which provides many options but first asks you to choose the data set for preprocessing.
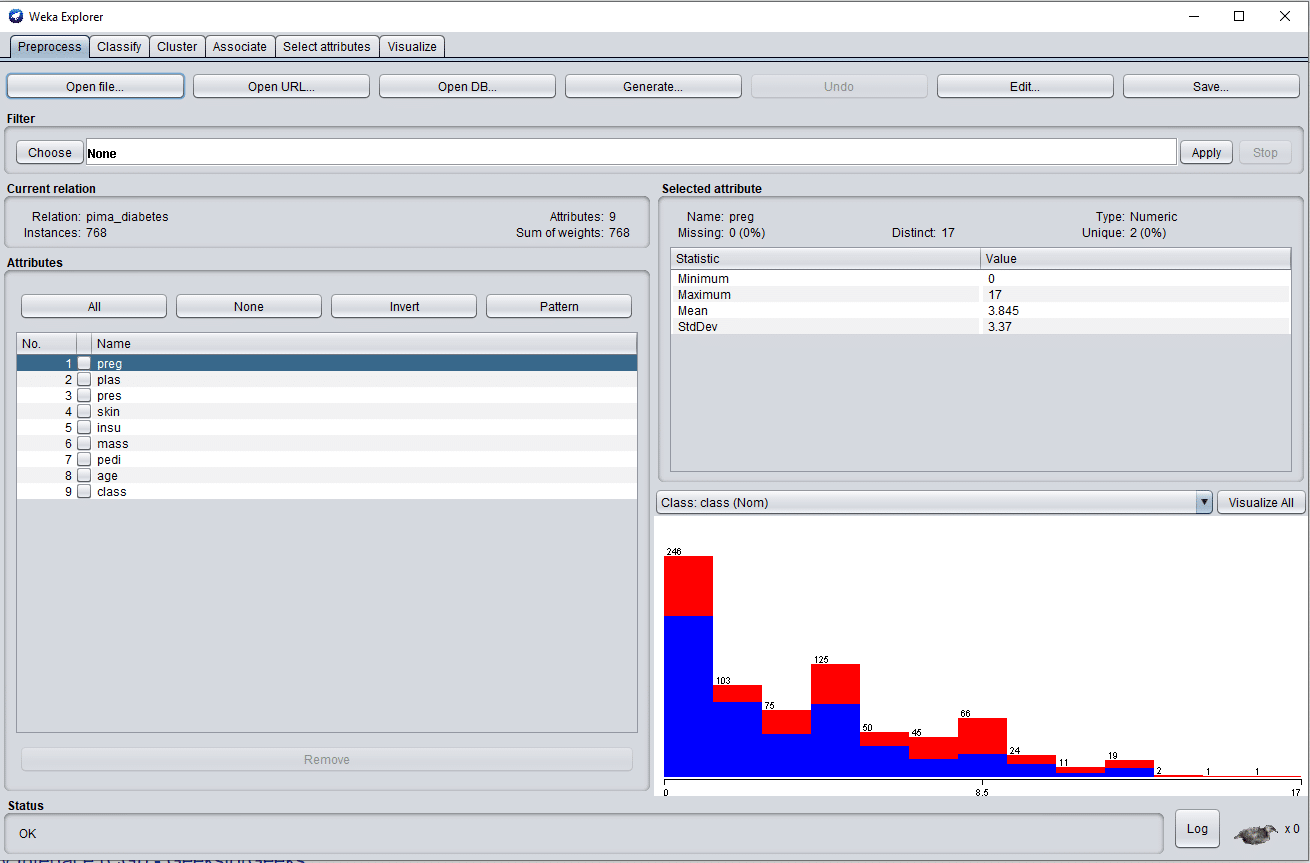
- Click on the ‘Open file’ tab to select the data set. Weka provides frequently used data sets for experimental purposes. What has been selected here is the very commonly used Pima Indians Diabetes data set that contains 768 instances and nine attributes, where one of the attributes is a class label. These attributes predict whether the patient has diabetes or not.
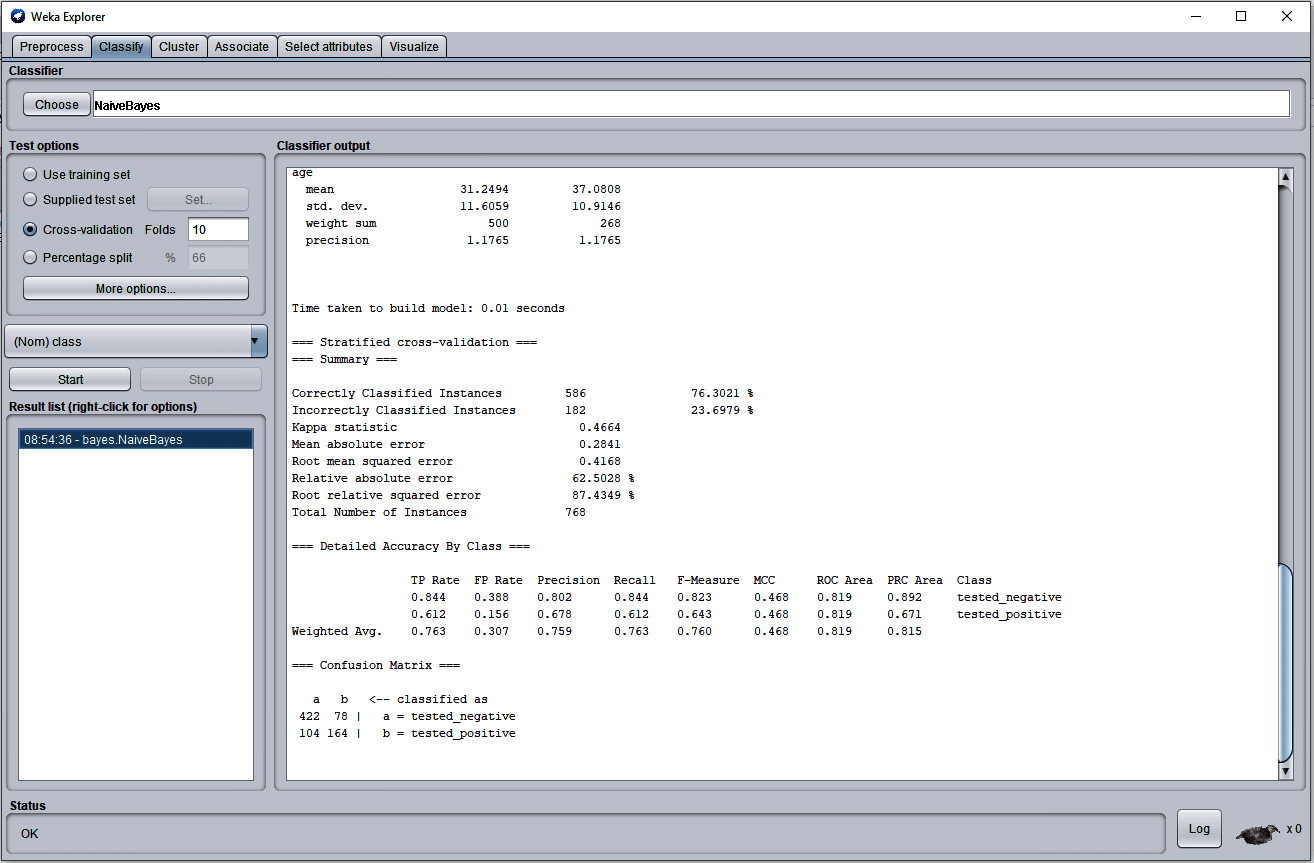
- To start an experiment, click on the ‘Classify’ tab to open the available classifiers in Weka. Among the several different classifiers available, we have applied the ‘NaiveBayes’ classifier with the value of cross-validation folds set to 10.
- Click on ‘Start’ and it shows the results of the experiment in the right side window, with the time taken to build the model and other performance measures.
As shown in Figure 4, the experiment provides a confusion matrix along with the accuracy of the prediction model. Here, the algorithm gives 76.3 per cent correctly classified ‘instances, while 23.69 per cent instances are incorrectly classified. Moreover, it gives the values of the TP (true positives) rate, FP (false positives) rate, precision, recall, F-measure and other parameters.
The environment offered by Weka enables users to design, run and analyse different experiments based on machine learning algorithms. It offers both the GUI and command line interface to run the experiments. We can also specify our own data set on which to perform different algorithms, in order to compare their performance.

















{kind=link}