





























































Organisations must leverage Python’s growing capabilities, alongside open source technologies, to design data and AI platforms for 2026 and beyond. Innovations on the horizon will reshape this landscape in the coming years.
Enterprise data engineering is at a pivotal moment, with artificial intelligence moving from experimental workloads to core business infrastructure. Organisations are grappling with unprecedented data volumes, real-time processing demands, and the operational complexity of running AI systems at scale. Python has emerged as the foundational layer for this transformation, evolving from a scripting language into the backbone of mission-critical data platforms. The maturity of Python’s open source ecosystem enables enterprises to build sophisticated platforms without vendor lock-in, creating composable architectures that can evolve with technological innovation.
The composable data platform architecture
Enterprise data architecture in 2026 demands a fundamental shift from monolithic vendor platforms to composable systems built on interoperable open source components. The architectural pattern that has proven most resilient combines best-of-breed tools orchestrated through Python-based integration layers, creating systems that can evolve independently without cascading changes across the platform. Frameworks like FastAPI have revolutionised API development, offering automatic OpenAPI documentation, native async support, and type technologies without wholesale platform replacements. Python’s type hints, significantly enhanced in Python 3.13 and 3.14, provide the foundation for contract-based architectures in which components can be verified for interface compliance using static analysis tools such as mypy. The architectural implications are profound: systems become collections of loosely coupled services with well-defined contracts, enabling teams to innovate independently while maintaining platform coherence. In 2026, the trend towards composability will accelerate with the emergence of standardised protocols for feature stores, model registries, and data catalogues, creating true plug-and-play ecosystems for data infrastructure.
Essential open source technologies for enterprise data platforms
The Python ecosystem’s strength lies in its comprehensive suite of open source technologies that address every layer of enterprise data architecture. These tools have reached production-grade quality, offering capabilities that rival or exceed proprietary alternatives while providing the transparency and customisability modern enterprises require. The following table highlights critical open source technologies that form the backbone of Python-centric data platforms.
| Technology | Description | Enterprise relevance |
| FastAPI | Modern web framework for building APIs with automatic documentation and type validation | Enables rapid development of microservices with production-grade performance, native async support, and automatic OpenAPI specs for API governance |
| Apache Airflow | Workflow orchestration platform for authoring, scheduling, and monitoring data pipelines | Provides enterprise-grade orchestration for complex DAGs with extensive monitoring, retry logic, and integration with virtually any data source |
| Apache Kafka | Distributed event streaming platform for high-throughput data pipelines | Serves as the backbone for real-time data architectures, enabling event-driven systems with exactly once processing semantics |
| DuckDB | Embedded analytical database with columnar storage | Delivers warehouse-class analytics performance within application processes, eliminating network overhead for analytical workloads |
| Polars | Lightning-fast DataFrame library written in Rust | Provides pandas-like API with superior performance for large dataset operations, leveraging parallel execution and efficient memory usage |
| MLflow | Platform for managing ML lifecycle, including experimentation, reproducibility, and deployment | Brings software engineering discipline to ML with experiment tracking, model versioning, and deployment orchestration |
| Feast | Feature store for managing and serving ML features | Ensures consistency between training and inference by providing a centralised repository for feature definitions and serving |
| dbt | A transformation framework that enables analysts to write modular SQL | Brings software engineering best practices to analytics with version control, testing, and documentation for data transformations |
| Prometheus | Monitoring system and time series database | Provides comprehensive metrics collection and alerting for distributed systems with a flexible query language |
| Ray | Distributed computing framework for scaling Python applications | Enables distributed training, hyperparameter tuning, and reinforcement learning with minimal code changes |
These technologies represent the convergence of performance, usability, and production-readiness that defines modern data engineering. Their adoption patterns reveal a shift from all-in-one platforms to specialised tools that excel at specific problems, composed into coherent systems through Python’s integration capabilities. The architectural advantage lies not in any single technology but in their interoperability—FastAPI services can trigger Airflow DAGs that process Kafka streams, store results in DuckDB, and serve predictions via MLflow models, all while Prometheus monitors system health. This composability enables enterprises to replace individual components as better alternatives emerge without rewriting entire platforms, providing the architectural flexibility that proprietary platforms cannot match.
Real-time data processing and AI-powered streaming
Real-time data processing has transitioned from an edge case to a baseline requirement, and modern architectures must seamlessly blend streaming and batch processing paradigms. Apache Kafka has become the standard for event streaming, and Python’s integration through libraries such as confluent-kafka-python enables sophisticated stream processing without requiring a JVM. The architectural breakthrough of 2025-2026 combines Kafka for transport, Python-based processors for transformation, and DuckDB for high-performance analytics—an embedded analytical database that processes millions of rows per second within application processes.
DuckDB’s columnar storage and vectorized execution challenge conventional wisdom about database deployment, eliminating network overhead while providing SQL capabilities that rival dedicated warehouses. When integrated with Python’s async/await patterns, these components create streaming architectures that handle high throughput while maintaining code readability and operational simplicity.
The next frontier emerging in 2026 involves embedding AI inference directly into streaming pipelines for real-time anomaly detection, predictive routing, and dynamic personalisation—use cases where latency measured in milliseconds determines business value. The architectural challenge lies in managing stateful stream processing, ensuring exactly once semantics, and mitigating resource contention between data processing and model inference — all this requires careful orchestration of compute resources and sophisticated backpressure mechanisms.
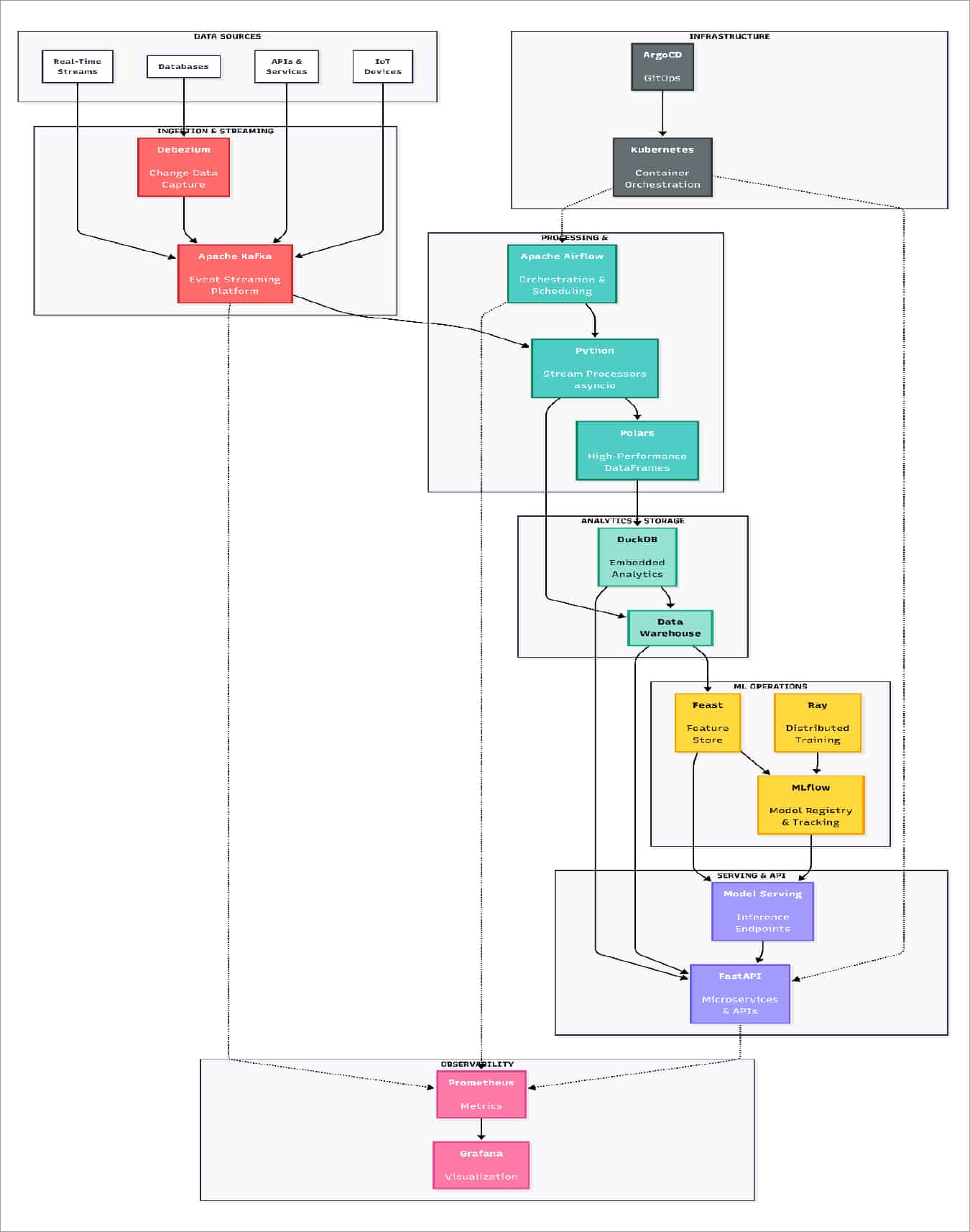
Integration of modern ETL and ML operations
The evolution of ETL into comprehensive data platform architectures represents one of the most significant transformations in enterprise data engineering. Apache Airflow has matured into the orchestration backbone for data platforms, managing dependencies across thousands of DAGs while providing the observability and reliability that production systems demand. Modern data architectures separate concerns into distinct layers: ingestion via change data capture tools such as Debezium, transformation with SQL-first frameworks such as dbt, orchestration with Airflow, and serving via specialised databases and APIs. Python serves as the integration substrate across these layers, implementing custom operators, validation frameworks, and business logic that adapts generic tools to specific requirements. The integration of AI into these pipelines creates new architectural dimensions around feature engineering, model training schedules, and automated quality monitoring. MLflow has become essential for managing the ML lifecycle—tracking experiments, versioning models, and orchestrating deployments—bringing software engineering discipline to machine learning operations. The Feast feature stores ensure consistency between training and inference environments, solving one of the most persistent challenges in production ML systems.
Looking ahead, we’re witnessing the emergence of autonomous data pipelines that use AI to optimise their own execution: predicting optimal scheduling windows, automatically tuning resource allocation, detecting data quality issues before they propagate, and even suggesting pipeline refactoring based on usage patterns.
Performance engineering and operational excellence
The narrative that Python is inadequate for enterprise performance requirements has been systematically disproven through runtime optimisations and architectural patterns that leverage Python’s strengths. Python 3.13 introduces significant performance improvements, including a more efficient garbage collector, while Python 3.14’s experimental free-threading mode promises to unlock true parallelism for CPU-bound workloads. The architectural principle involves layered optimisation: start with readable Python, identify performance bottlenecks through profiling, and apply specialised tools such as Cython or Numba only where justified by data. Polars demonstrates how Python interfaces can provide ergonomic access to Rust-powered performance that exceeds traditional alternatives.
Running Python-based platforms at enterprise scale demands operational maturity that extends far beyond conventional DevOps practices. The observability stack has consolidated around Prometheus for metrics, Grafana for visualisation, and OpenTelemetry for distributed tracing, providing comprehensive visibility without vendor lock-in. GitOps has emerged as the deployment paradigm for data platforms, where declarative configurations in version control drive automated pipelines via tools such as ArgoCD and Flux. This approach, combined with infrastructure-as-code using Python-based tools like Pulumi, transforms deployments from risky manual processes into routine automated workflows.
In 2026, the frontier involves autonomous operations—systems that use AI to predict failures before they occur, automatically scale resources based on workload forecasting, and optimise cost allocation across cloud services.
Enterprise data engineering in 2026 represents a remarkable maturation of Python-centric architectures, open source ecosystems, and AI-native design patterns, collectively enabling unprecedented capabilities at enterprise scale. Innovations on the horizon—free-threaded Python, WebAssembly integration, AI-powered autonomous platforms, and specialised accelerators for ML workloads—promise to expand what’s possible while maintaining the developer productivity and architectural flexibility that made Python successful. The enterprises that thrive will be those whose architects embrace this evolution, investing in building internal capabilities around these open source technologies and the architectural patterns that connect them into coherent, scalable platforms that can evolve with the rapid pace of innovation in data and AI.
Disclaimer: The opinions expressed in this article are the author’s and do not reflect the views of the organisation he works in.

















