




























































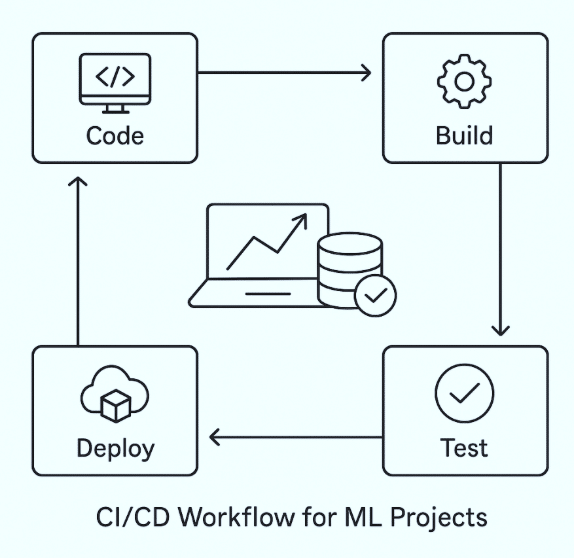
By embracing continuous integration and continuous deployment, machine learning systems can keep pace with the environments they operate in. GitHub Actions helps build automation into the workflow, leading not only to a well-performing model but a complete pipeline that continuously delivers value to users.
Machine learning is now a core part of everyday applications. Whether it is personalising what we watch, detecting banking frauds, or improving health diagnostics, ML systems are constantly learning and improving. But behind every successful model that reaches users lies a demanding process. Training a model in a notebook is only the beginning. To work in the real world, the model must be tested carefully and deployed in a way that is repeatable, reliable, and fast.
This is where CI/CD, short for continuous integration and continuous deployment, becomes important. These practices transformed the software development world by automating testing and deployment every time the code changed. For machine learning, they do even more. Along with code, ML projects must manage data, experiments, and trained model files, all of which change over time. A model that performs wonderfully one week may suddenly fail if the data it sees begins to shift. Without automation, it becomes difficult to trust that each new update is actually improving the model.
GitHub Actions has made CI/CD more accessible than ever for ML teams. Because it is built into GitHub, automation can attach directly to the same place where code and models are versioned. With a simple workflow file, tasks like installing dependencies, verifying data pipelines, checking metrics, running lightweight training, and deploying updated models can all happen automatically. This removes the repeated manual steps that often lead to mistakes or inconsistent environments.
By using CI/CD, machine learning development becomes more confident and organised. Each change is tested before it reaches production. Every model has a clear history of how it was built and which data it used. Deployments become routine rather than risky. Most importantly, teams can deliver improvements faster, ensuring the model stays accurate as the world around it changes. Instead of a one-off experiment, machine learning grows into a continuous, sustainable solution.
Understanding the ML project lifecycle
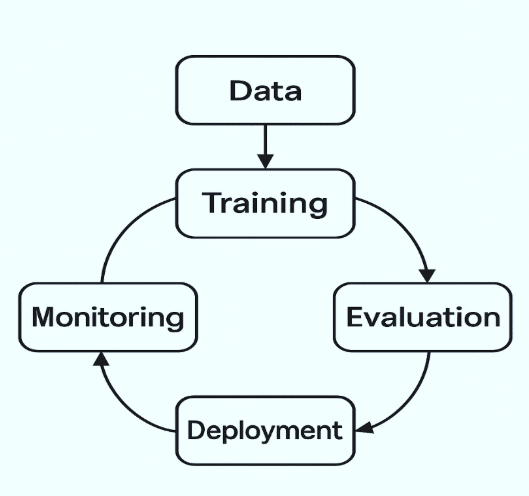
Every machine learning project follows a journey long before a model ever reaches users. It begins with gathering data, often from multiple messy sources that require cleaning and organisation. That data then goes through careful preparation, where missing values are handled and meaningful features are created. Only after this groundwork is done can model training truly begin.
Training is rarely a one-time process. Developers try different algorithms, tune parameters, compare results, and repeat the cycle until performance meets expectations. When the model seems ready, the work shifts from experimentation to production. The model needs to be packaged along with the code that makes predictions and deployed somewhere it can serve real users, whether through a web API, a cloud server, or even an application running on edge devices.
But deployment is not the finish line. It is more like the starting point of a real test. Once the model interacts with live data, its performance can change. Customer behaviour may shift, noise in sensors might increase, or market conditions can suddenly evolve. If no one keeps an eye on how the model is performing, its accuracy may silently drop and affect users in unexpected ways. This is why consistent monitoring plays such a crucial role in machine learning. When performance dips, the cycle returns to the beginning: collect updated data, retrain, and release an improved version.
This continuous loop of data, development, deployment, and monitoring is what defines the ML project lifecycle. Each step affects the next, and even a small error can ripple through the system if not caught early. When this lifecycle is supported only by manual work, it becomes slow and prone to mistakes. Automating parts of it with CI/CD allows teams to catch issues sooner and ship better models faster. Instead of worrying whether changes might break the system, developers build confidently, knowing that every update is validated and traceable. In a world where models must grow and adapt, CI/CD enables the ML lifecycle to keep up with the pace of change.
Setting up the ML project repository
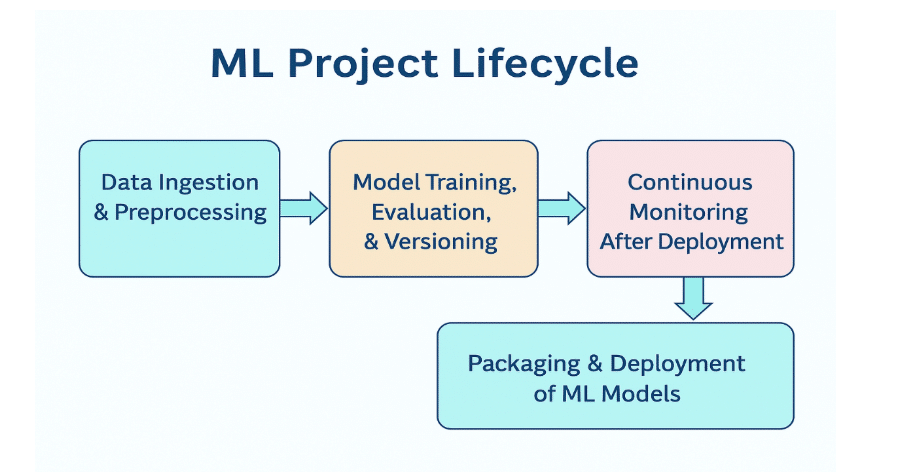
Before building automation or deploying a model, the foundation of a machine learning project must be well-organised. A properly structured repository not only makes development easier but also ensures that CI/CD pipelines can run smoothly without confusion about where data, models, or scripts are located. Many beginners start with everything inside a single notebook, but as a project progresses, that approach becomes difficult to maintain or share within a team.
A clean project structure usually separates code, data, and trained models into different folders. Scripts for preprocessing, feature engineering, and model training live inside a dedicated source directory, while configuration files and dependencies are defined so they can be reproduced on any machine. This is especially important for CI workflows, which install everything fresh each time they run. When the structure is simple and predictable, automation becomes far easier to build, test, and trust.
Machine learning projects often work with large datasets and binary model files that cannot be pushed directly to GitHub because of size limitations. Tools such as Git LFS, which stands for Large File Storage, help manage these heavy assets without slowing down the repository or cluttering version history. Storing models in a structured and traceable way ensures that every version used during training or deployment is clearly identified. This becomes especially important when issues arise in production, because teams must be able to quickly trace back to the exact model version, review how it was produced, and roll back if necessary.
Proper versioning and artifact handling maintain control as models evolve, allowing development to remain smooth, transparent, and reliable over time. Even the way work is pushed matters. Following a branch strategy, such as using separate branches for experimentation and final production changes, keeps the project clean and prevents half-complete features from accidentally going live. Review processes, pull requests, and version tags all contribute to a more controlled development environment.
With a well-designed repository in place, the next steps in the CI/CD pipeline become more reliable. The project is prepared for automation, collaboration, and long-term maintenance. Good organisation may feel like a simple step, but it sets the stage for everything else that follows.
Getting started with GitHub Actions
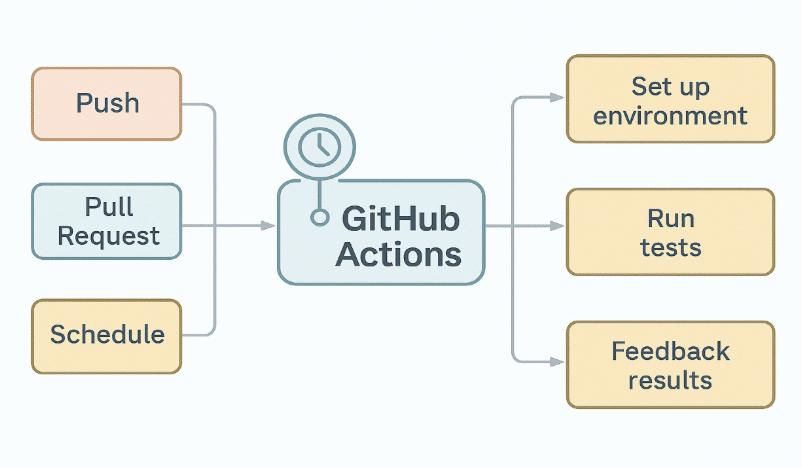
With the repository structure in a good place, the next step is to bring automation into the workflow, and GitHub Actions makes that remarkably accessible. Since it is built right into GitHub, there is no need to set up additional servers or external tools. The automation lives alongside the code, watching for changes and reacting immediately whenever someone pushes updates or opens a pull request.
GitHub Actions uses simple configuration files to define what should happen automatically. These files sit inside a hidden folder in the repository and describe instructions such as installing dependencies, running tests, or deploying a new version of the model. The best part is that developers do not need to worry about managing machines. GitHub provides runners that execute all the steps from a clean environment each time, ensuring that the application does not depend on what happened during a previous run.
The idea may feel unfamiliar at first, but the essence is simple. A workflow is a set of tasks that run on events. If new code is pushed, a workflow might trigger to check that data preprocessing still works. If a pull request is opened, another workflow might train the model on a smaller dataset to make sure the accuracy has not dropped. In many ways, GitHub Actions acts like a smart assistant, constantly inspecting the project and helping the team maintain quality without extra effort.
One of the strengths of GitHub Actions is how flexible it can be. It supports complicated pipelines, scheduled model retraining, and deployment to different platforms without leaving the GitHub environment. Visual logs and status checks make it easy for contributors to understand exactly what passed and what failed. Over time, this automation becomes an essential part of the workflow, reducing manual work and building trust in every change that reaches users.
By integrating GitHub Actions early in a machine learning project, teams lay the foundation for reliable automation. It brings discipline into development while still allowing rapid experimentation. For beginners, starting small with a basic workflow is often enough to experience the value — a project that checks itself and keeps improving with every update.
Building continuous integration (CI)
Continuous integration is the point where automation begins to make a visible difference in machine learning projects. Every time a developer pushes a change, CI steps in to verify that the update has not broken anything. Instead of relying on manual checks or assumptions, the pipeline runs tests automatically and confirms that the project is still healthy. In a field like machine learning, where even a small change in data or preprocessing can alter model performance, this consistency is essential.
A CI pipeline for ML usually starts by setting up the environment. Dependencies are installed fresh each time, so no hidden configurations interfere with results. Data loading scripts are then tested to ensure they can still handle the latest datasets without errors. This helps catch common problems early, such as missing values in new data or changes in feature names that may otherwise go unnoticed.
The model itself can also be included in CI. A light version of training, using a small sample of the original data, gives instant feedback on whether performance remains acceptable. It may not reproduce the full model, but it does alert the team if accuracy suddenly drops because of a faulty change. Along with this, the pipeline can check code quality and formatting so that the project remains clean and readable as it grows.
One major advantage of CI is artifact handling. Once the quick tests pass, the pipeline can save trained model files, evaluation reports, or logs as artifacts. This allows developers to download, inspect, or even reuse these outputs later without needing to rerun everything manually. CI is not just a safety net; it improves productivity by reducing repeated effort.
When this system is in place, developers gain confidence with every update. Mistakes that would normally surface late in the process are caught immediately. The result is faster iteration, better collaboration, and models that remain reliable over time. Continuous integration becomes the heartbeat of the project, ensuring every change contributes positively to progress.
Model versioning and artifact management
Once a model has passed testing in the CI pipeline, the next challenge is making sure its outputs are tracked properly. In traditional software development, versioning applies mostly to code. But in machine learning, the trained model itself becomes an important artifact that must be managed carefully. The exact version of the model running in production should always be known, traceable, and recoverable, especially when updates are frequent.
Versioning models ensures that teams can move forward confidently without losing track of what worked before. When a new experiment performs better, it can be saved as a new version. If performance goes down or unexpected behaviour appears after deployment, a stable version can be rolled back immediately. This level of control helps prevent errors from affecting users and keeps the development cycle smooth.
Storing these model artifacts is equally important. GitHub offers built-in storage through Actions, allowing files such as trained models, evaluation metrics, or logs to be saved after each automated run. Instead of rerunning training repeatedly, developers can simply download the stored artifact and continue working. For larger models and datasets that cannot be pushed directly to GitHub, tools like Git LFS or cloud storage services become valuable companions. They handle heavy files while still maintaining links to the correct code version.
A well-organised artifact management system also plays a vital role in reproducibility. Anyone joining the team later can see exactly which version of code and data produced a particular model. This transparency helps avoid hidden bugs and confusion about how results were achieved. More importantly, it supports responsible deployment, where every model in production is backed by evidence and testing history.
By building versioning into the CI pipeline, machine learning development becomes more predictable and controlled. Progress is no longer a guessing game, and the team gains a clear record of how the system evolves. With proper artifact management, models remain trustworthy throughout their lifecycle, even as they are updated repeatedly.
Building continuous deployment (CD)
Once a model is trained, tested, and versioned, the final step is to make it available where it can serve predictions in real time. Continuous deployment focuses on automating this release process so that updated models reach users smoothly and quickly. Instead of depending on manual uploads or server-side tweaks, the pipeline performs all the steps required to roll out improvements whenever the latest version is ready.
Deployment in machine learning often involves packaging the model together with an inference script, then placing it behind an API or container that applications can call. GitHub Actions connects directly with popular deployment platforms, which means a workflow can build a Docker image, push it to a registry, and update a cloud service automatically. This removes human delays between development and delivery, ensuring the best-performing model is always the one users interact with.
The true value of a CD becomes clear when updates are frequent. Instead of treating deployment as a risky event, it becomes a regular and trusted part of development. If a new version performs better, it rolls out. If monitoring later shows any drop in accuracy, the pipeline can revert to the previous version just as easily. This gives teams the freedom to innovate without fear of breaking production systems.
Infrastructure automation also plays a role here. Tools like Terraform or serverless deployment frameworks make it possible for the environment to be defined as code, so any infrastructure changes required for the model rollout are handled automatically too. The pipeline takes care of scaling, configuration, and setup, creating a seamless path from experimentation to real-world impact.
Continuous deployment turns machine learning from a static solution into a living product. Every improvement made during development has a clear path to users, and every version of the model can be verified and controlled. This automation ensures that the intelligence powering an application stays up-to-date with evolving data, without placing any extra burden on developers or operations teams. In essence, CD allows machine learning systems to grow and adapt just as quickly as the world they serve.
Turning a machine learning model into a reliable product demands a process that keeps the model healthy as data evolves and new ideas are introduced. CI/CD offers that process by bringing automation, quality checks, and deployment discipline into the world of machine learning development.
With continuous integration, every update to code or data is tested early, catching issues before they grow into bigger failures. With continuous deployment, new model versions reach users quickly and safely, while still allowing rollbacks when necessary. GitHub Actions ties everything together by making automation accessible directly within the development workflow, without extra tools or complicated infrastructure.















