






























































Microservices architecture has emerged as a preferred pattern for building scalable and maintainable software applications. Here’s how a monolithic job portal application was re-engineered into a microservices-based system. The migration process, key design decisions, the technology stack used, and measurable improvements in performance and flexibility are all laid out for you.
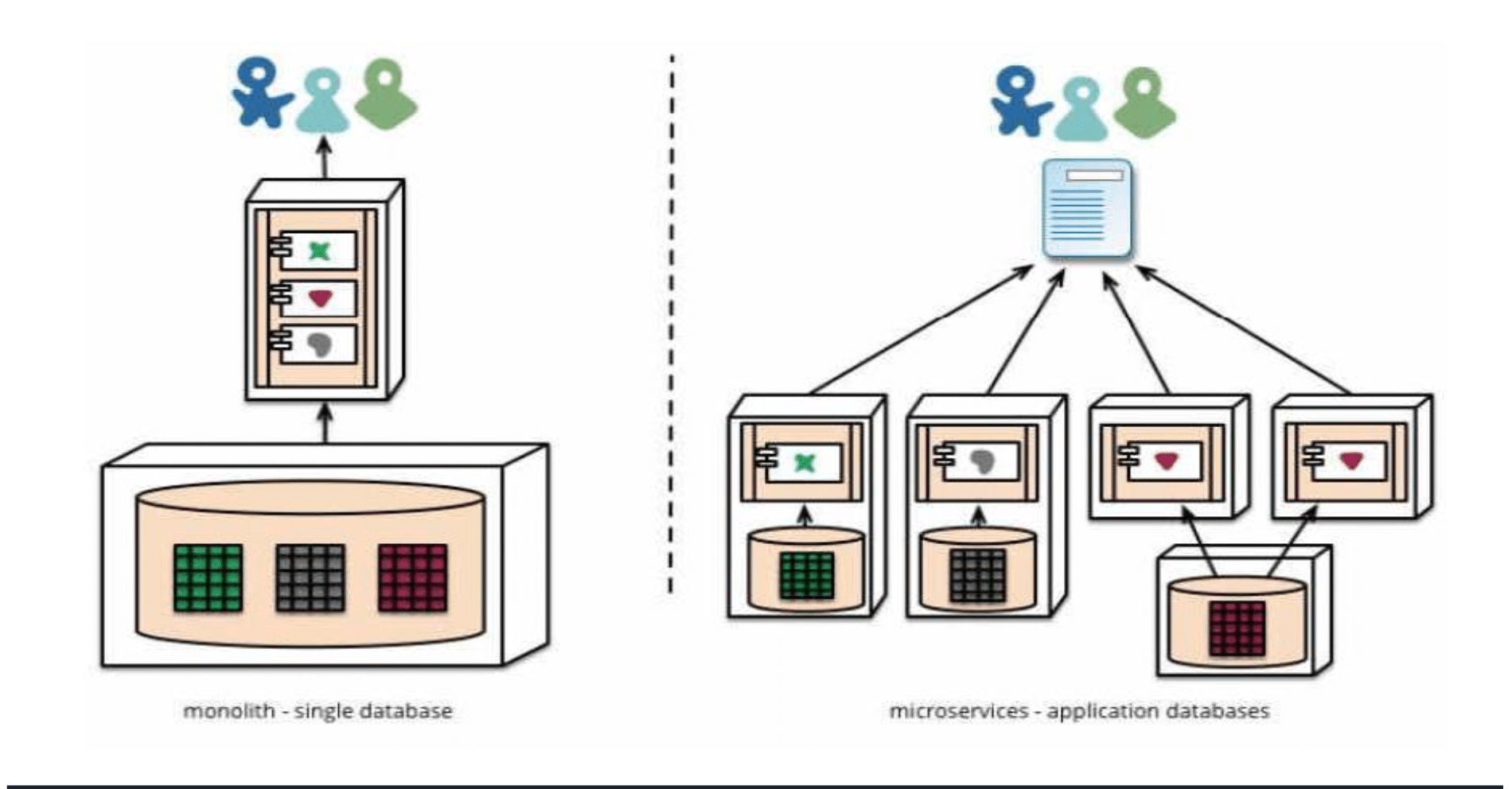
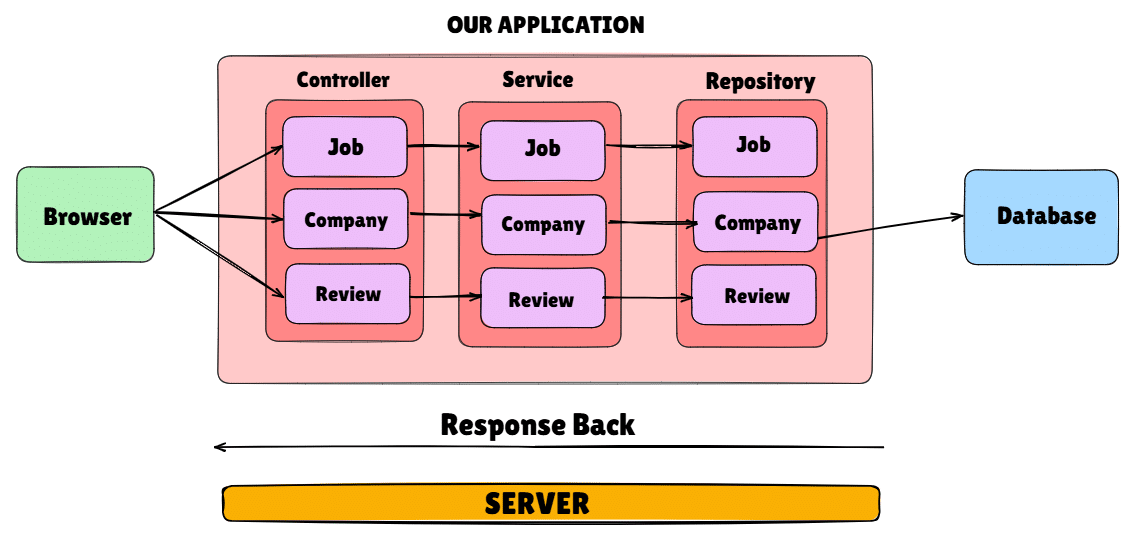
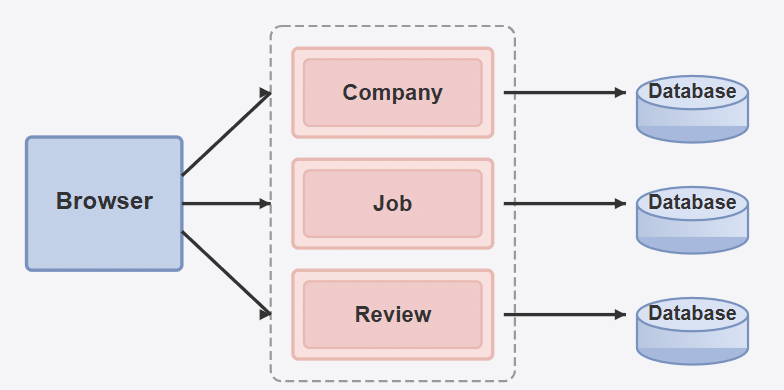
As an application scales, it must migrate from a monolithic architecture to a microservices-based one. Here, we document the migration of a job portal from a monolithic architecture to a microservices-based design. Initially, all core features—job listings, company profiles, and user reviews—were embedded in a single application. While this structure offered simplicity, it became a bottleneck as the platform grew. To improve scalability and maintainability, the system was redesigned using independent services for job, company, and review management. Each service now operates with its own database and deployment pipeline, enabling fault isolation and independent scaling.
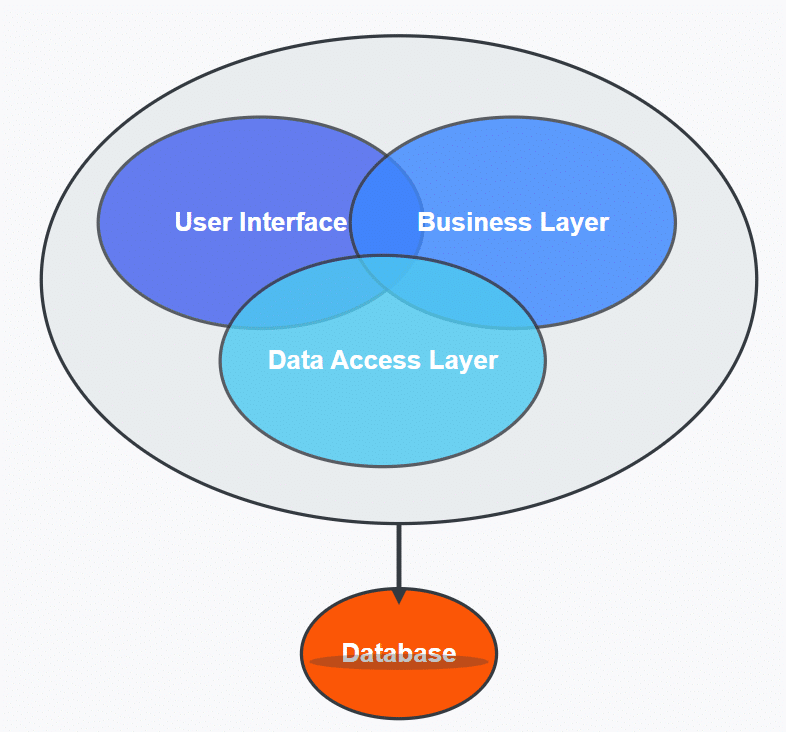
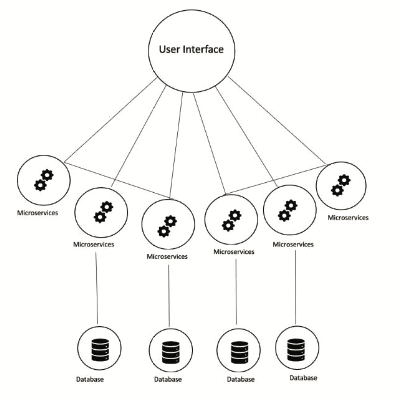
The schema of the project is designed to represent the core entities: Job, Company, and Review. In the monolithic version, these entities share a centralised database. However, in the microservices architecture, each service manages its own database, ensuring data autonomy and service independence.
The transition
The transition from a monolithic to a microservices architecture involved carefully decoupling the tightly integrated components of the original system. Initially, all business logic for job postings, company information, and user reviews resided within a single codebase and shared a common database, as illustrated in Figure 1. To enable independent development and deployment, each core feature was extracted into its own service as depicted in Figure 2, with separate repositories and databases. APIs were introduced for inter-service communication, replacing direct function calls and database joins. This shift required restructuring data flow, implementing service discovery, and addressing challenges such as data consistency, API versioning, and centralised logging. Despite the complexity, the transition significantly improved scalability, maintainability, and the ability to deploy updates without affecting unrelated parts of the system.
In the process of converting the job portal from a monolithic to a microservices architecture shown in Figure 3, several mathematical and computational models were utilised to ensure optimal system performance and efficiency. Queuing theory, analyse request handling and inter-service communication were applied to the model, helping to minimise latency and avoid bottlenecks. Load balancing algorithms, such as round-robin and least connections, were evaluated to distribute traffic evenly across services. Dependency graphs were used to identify tightly coupled components in the monolith, guiding the service decomposition strategy. Additionally, consistency models such as eventual consistency and CAP theorem principles were considered to manage data integrity across distributed databases. These models provided a structured approach to making architectural decisions, ensuring that the transition maintained high system reliability, scalability, and responsiveness.
Technology stack
Spring Boot was chosen for implementing the microservices architecture due to its robust support for building scalable, production-ready applications with minimal configuration. Prior to this transition, the system followed a monolithic architecture, where all functionalities were tightly coupled within a single application as shown in Figure 4. It provides a lightweight framework that simplifies the development of individual services, allowing each microservice—such as Job, Company, and Review—to be developed, tested, and deployed independently as presented in Figure 5. Spring Boot’s seamless integration with Spring Cloud offers powerful tools for service discovery (via Eureka), centralised configuration, load balancing (using Traefik), and fault tolerance (with Hystrix or Resilience4j). Moreover, its built-in support for RESTful APIs, embedded servers like Tomcat, and easy integration with databases makes it an ideal choice for microservices. These features significantly accelerated development while ensuring consistency, flexibility, and maintainability across the entire system.
Technology stack for the microservices-based open source job portal
| Component | Technologies |
| Frontend | React, Next.js |
| Backend | Java, Spring Boot |
| Database | PostgreSQL |
| Containerisation | Docker |
| Monitoring/Tracing | Zipkin |
| Message queue | RabbitMQ |
| Service discovery | Eureka |
| Load balancer | Traefik |
Folder and file structure
Figure 6 describes the project structure of the microservices application, which is modularized as follows:
- dto/: Contains Data Transfer Objects for efficient data communication between services.
- external/: Handles inter-service communication using REST clients.
- impl/: Contains business logic implementation.
- Job.java: Defines the Job entity mapped to the database.
- JobController.java: Manages HTTP endpoints for Job-related operations.
- JobRepository.java: Provides CRUD operations for the Job entity.
- JobService.java: Contains core job-related business logic.
DTO (Data Transfer Object)
DTO stands for Data Transfer Object. It is an object that is used to transfer data between software application subsystems or layers, typically over a network. DTOs are designed to be simple containers for data, and they do not contain any business logic. They are primarily used to reduce the number of method calls by encapsulating multiple data elements in a single object. For example, when transferring data from a database to a client application, a DTO can aggregate various pieces of information (such as a user’s name, email, and address) into a single object. This helps optimise communication, especially in distributed systems where network calls may be expensive or slow. DTOs are often used in combination with other patterns, such as the DAO (Data Access Object) pattern, and are particularly useful in web services and APIs where efficient data transfer is crucial.
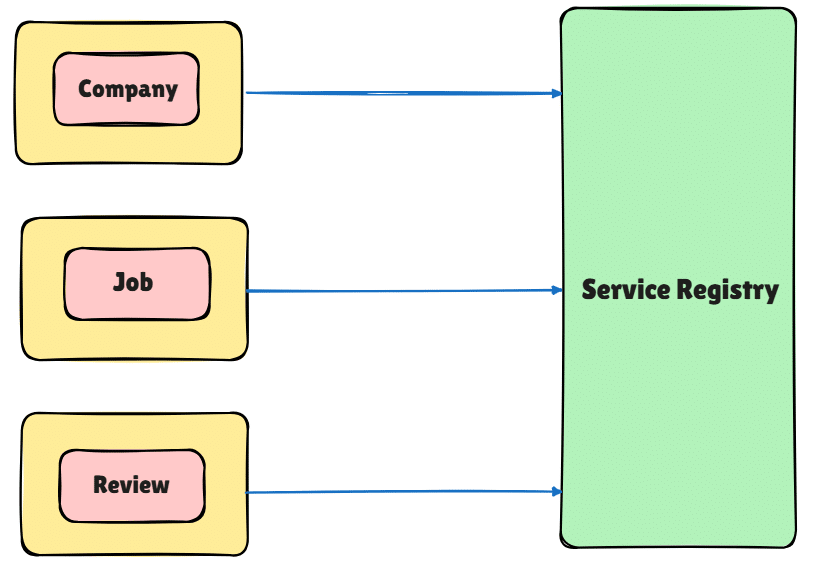
Service registry
A service registry is a centralised database or repository that maintains information about available services in a distributed system or microservices architecture. It acts as a directory where services register themselves upon startup, providing metadata such as the service name, network location, and status. The registry allows other services to discover and connect to the registered services dynamically without hardcoding their locations. This is especially useful in environments where services may scale up or down, and their network addresses change frequently. Service registries are often used in conjunction with service discovery mechanisms, which help clients find and access services by querying the registry. Tools like Eureka are commonly used to implement service registries as demonstrated in Figure 7, ensuring high availability, fault tolerance, and scalability in microservices-based architectures.
Fault tolerance
Fault tolerance refers to the ability of a system to continue functioning correctly even in the presence of failures. A fault-tolerant system is specifically designed to handle unexpected disruptions, such as hardware failures, network issues, or software bugs, without compromising the overall user experience or service reliability. To achieve fault tolerance, systems often employ redundancy, graceful degradation, and various error-handling mechanisms, such as retries, timeouts, and fallback procedures. For instance, critical components may be replicated across multiple servers or regions to ensure that if one server fails, another can take over seamlessly, minimising service interruptions.
One key strategy for maintaining fault tolerance, particularly in microservices architectures, is the implementation of circuit breakers. A circuit breaker, such as the companyBreaker instance used in this system, monitors service interactions, specifically tracking failure rates and slow call rates. The circuit breaker ensures that if the failure or slow call rate exceeds predefined thresholds (for example, a failure rate threshold of 50), appropriate protective actions are triggered.
Under normal operation, when no failures or slow calls are detected, the circuit breaker remains in the CLOSED state, allowing uninterrupted service. By carefully monitoring metrics such as failure rates, buffered calls, and slow calls, the circuit breaker helps maintain system resilience while minimising performance degradation. This approach contributes significantly to fault tolerance by preventing systemwide failures and ensuring high availability and reliability, even during adverse conditions.
The goal of fault tolerance, supported by mechanisms like circuit breaking, is to minimise the impact of failures, ensuring continuous, reliable service for mission-critical applications.
Circuit breaker pattern
The circuit breaker pattern is a design pattern, represented in Figure 8, used to detect failures in a system and prevent them from cascading. In a microservices architecture or distributed system, services often depend on other services to function properly. When one service becomes unavailable or experiences issues, it can cause a chain reaction of failures across the system. The circuit breaker pattern helps mitigate this by monitoring service calls and breaking the circuit (that is, preventing further calls) when a threshold of failures is reached. Listing 1 illustrates the implementation of a circuit breaker using RestTemplate.
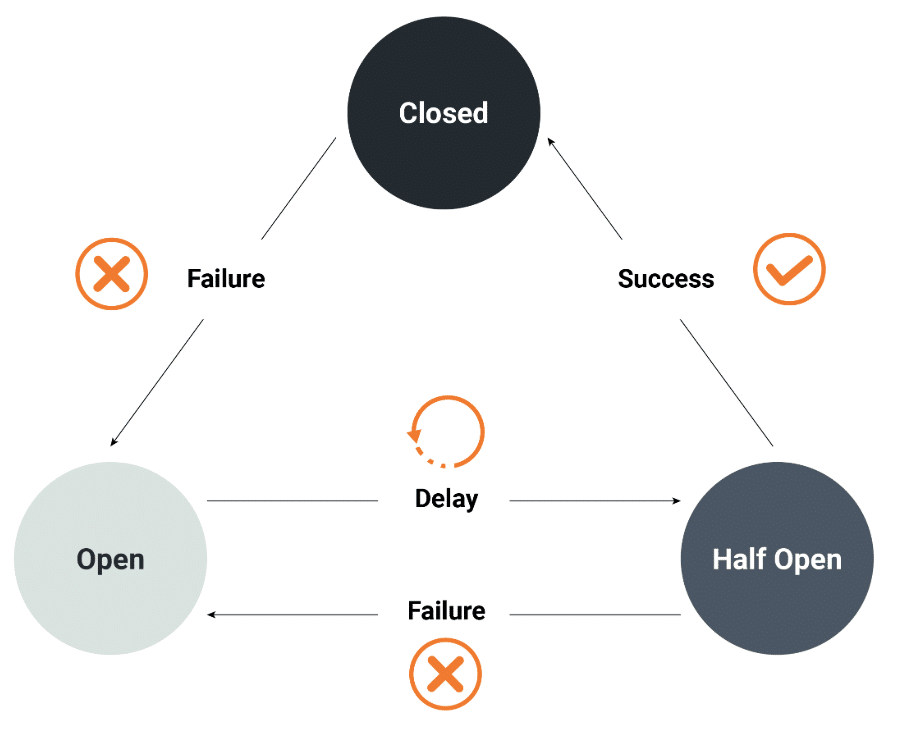
After a certain time or recovery period, the circuit breaker allows a limited number of test requests to check if the service has recovered. If the service is healthy again, the circuit breaker closes, and normal operation resumes. This approach helps improve system resilience, reduce downtime, and ensure that failures in one service do not impact the entire system.
Listing 1: Circuit breaker with RestTemplate
@Service
public class CompanyServiceClient {
@Autowired
private RestTemplate restTemplate;
private static final String BASE_URL = “http:// COMPANY-SERVICE/companies”;
@CircuitBreaker(name = “companyService”, fallbackMethod = “fallbackGetCompanyById”)
public CompanyDTO getCompanyById(Long companyId)
{
return restTemplate.getForObject(BASE_URL + “/” + companyId, CompanyDTO.class);
}
// Fallback method called when the circuit is open
public CompanyDTO fallbackGetCompanyById(Long companyId, Throwable throwable) {
CompanyDTO fallbackCompany = new CompanyDTO ();
fallbackCompany.setId(companyId); fallbackCompany.setName(“Company information
not available at the moment”);
return fallbackCompany;
}
}
RabbitMQ integration
RabbitMQ is an open source message broker that facilitates communication between distributed applications or services by enabling them to exchange messages asynchronously. It implements the Advanced Message Queuing Protocol (AMQP) and is designed to ensure reliable, scalable, and fault-tolerant messaging. RabbitMQ, as outlined in Figure 9, allows producers to send messages to a queue, from which consumers can retrieve and process them. This decouples the components of an application, enabling them to communicate without direct dependencies.
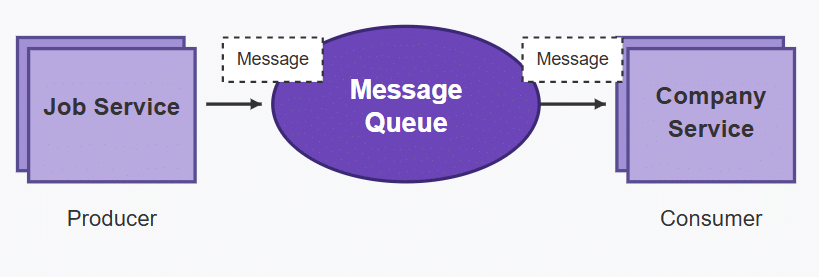
RabbitMQ supports features such as message persistence (ensuring messages are not lost), message routing, load balancing, and delivery guarantees, which make it ideal for systems that require high throughput and fault tolerance. It is widely used in microservices architectures, event-driven systems, and for integrating disparate systems with different communication patterns.
Use of OpenFeign
In this project, OpenFeign has been integrated as a declarative REST client to simplify inter-service communication between the microservices within the Micro Job App architecture. Instead of manually using RestTemplate or WebClient, Feign clients have been defined via interfaces annotated with @FeignClient. This allows different microservices (such as the Job Service, User Service, or Notification Service) to easily call each other over HTTP without writing boilerplate code for request handling.
For example, when the Job Service needs to fetch user profile data from the User Service, it simply calls a method on the corresponding Feign interface, and OpenFeign automatically handles the request, response mapping, and error handling under the hood. This greatly enhances readability, maintainability, and modularity of the code.
Listing 2: Feign client example
@FeignClient(name = “user-service”)
public interface UserClient { @GetMapping(“/users/{id}”)
UserDTO getUserById(@PathVariable(“id”) Long id);
}
Use of Zipkin
Zipkin has been incorporated into this project for distributed tracing across the microservices, helping developers track and visualise the flow of requests through the system. Each microservice is configured to send tracing data to the Zipkin server, which collects and aggregates these traces. When a client initiates a request (for example, posting a new job), the system records detailed timing information as the request travels through multiple services (such as Job Service → Notification Service → Email Service). This helps in identifying performance bottlenecks, understanding request latency, and diagnosing failures across service boundaries. The integration with Spring Cloud Sleuth further enriches the tracing data by automatically tagging logs with trace IDs and span IDs, making it easier to correlate logs and traces.
Listing 3: Zipkin configuration spring.zipkin.base-url=http://localhost:9411/ spring.sleuth.sampler.probability=1.0
The results
The transition from a monolithic architecture to a microservices-based architecture for the job portal resulted in significant improvements across multiple dimensions of system performance, development agility, and operational efficiency. Here are the key benefits we observed.
Before migration, the monolithic application could reliably handle up to 500 concurrent users before response times degraded significantly (average latency increased to over 1200ms). After migration, the microservices-based system handled 2000 concurrent users with acceptable performance (average latency stayed below 400ms). This represents a 4X increase in user capacity with a 66% reduction in average response time. The experimental setup and results are demonstrated in Figures 10 and 11.
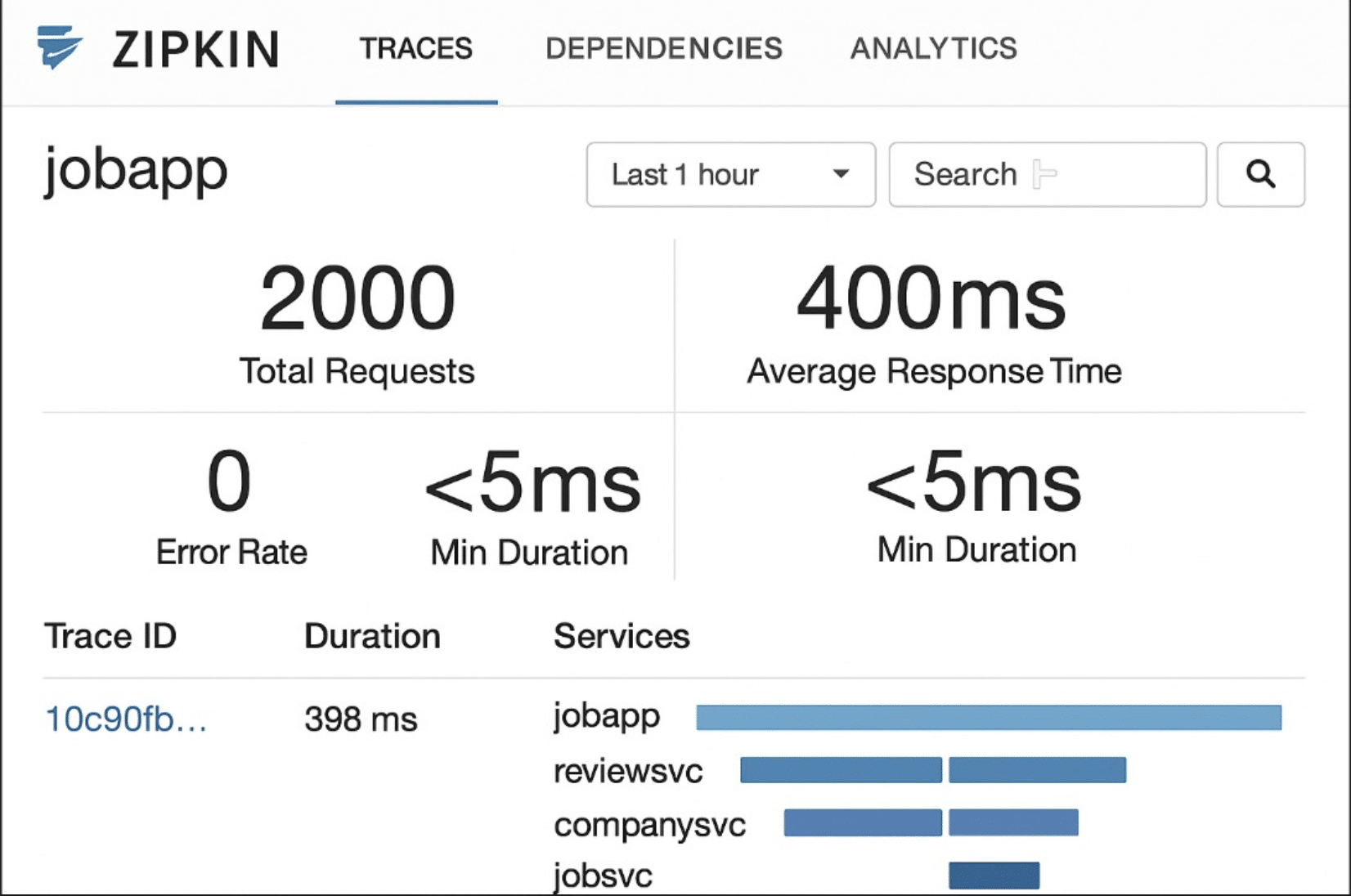
Deployment time
The full deployment of the monolithic application took approximately 30 minutes with downtime. In the microservices setup, deployment of individual services (Job, Company, and Review) now takes about 5 minutes per service with zero downtime using rolling updates. This resulted in an 83% reduction in deployment time.
Fault isolation and recovery
Previously, a failure in one module could cause partial or total system downtime. With microservices, failures are isolated; for instance, issues in the Review service do not affect Job or Company services. Average recovery time was reduced from around 20 minutes to about 3 minutes due to independent service restarts.
Resource utilisation
Monolithic deployment required 4 vCPUs and 8GB RAM constantly, irrespective of module loads. In contrast, microservices scaled independently:
Job service: 2 vCPUs, 4GB RAM
Company service: 1 vCPU, 2GB RAM
Review service: 1 vCPU, 2GB RAM
This led to a 30–40% reduction in total resource consumption under normal load conditions.
Improvements and challenges
The migration to a microservices architecture significantly enhanced the flexibility, performance, and reliability of the job portal system. By decoupling services, implementing asynchronous communication (RabbitMQ), enabling service discovery (Eureka), utilising declarative REST clients (OpenFeign), and adopting distributed tracing (Zipkin), the system now supports dynamic scaling, fault isolation, and faster feature rollouts. Quantitatively, the platform achieved a 4X improvement in scalability, 83% faster deployment, and 30–40% savings in resource utilisation, validating the architectural shift and setting a robust foundation for future expansion.
Though this migration brought significant improvements, it also introduced new complexities that warranted careful management. While scalability, resilience, and development agility were greatly enhanced, challenges such as service orchestration, distributed data management, and inter-service communication overhead emerged. To address these, techniques like asynchronous messaging (RabbitMQ), service discovery (Eureka), client-side load balancing (Ribbon), and declarative REST clients (OpenFeign) were employed.
Furthermore, the implementation of circuit breakers using Resilience4j ensured that transient failures in one service did not propagate through the system, preserving overall stability. Monitoring tools such as Zipkin for distributed tracing and Spring Boot Actuator for health checks provided critical visibility into system behaviour, enabling proactive maintenance. Overall, the microservices approach introduced manageable trade-offs, and the net gain in system flexibility, fault isolation, and scalability validated the architectural transition as a sustainable foundation for future expansion.
















