





























































Small language models are proving to be game changers in the AI world. Deploying these models early on can give organizations an edge over the competition.
While the industry fixates on frontier large language AI models with hundreds of billions of parameters, a parallel transformation is underway. Small language models (SLMs)—typically ranging from 1B to 13B parameters—are proving that intelligent scale, not massive scale, drives business value. Organizations deploying SLMs are achieving 200-400% ROI within the first year, with deployment cycles measured in weeks rather than quarters.
This shift represents more than cost optimization. It represents a fundamental rethinking of how AI creates competitive advantage through speed of deployment, precision of application, data sovereignty, and operational resilience. The question is no longer whether to adopt small models, but how quickly your organization can architect around them before competitors do.
Real-world ROI
The conventional wisdom that larger models inherently deliver better outcomes is being challenged by empirical evidence across industries. Consider three representative scenarios that illustrate the strategic value of architectural precision over computational excess.
Customer service transformation
A Fortune 500 financial services firm replaced its third-party large model API with a fine-tuned 7B parameter model for tier-1 customer enquiries. The result: 89% accuracy on domain-specific queries, sub-100ms response times, and a 73% reduction in inference costs. More critically, they achieved full data residency compliance across all global markets—something not possible with API-based approaches. Time to full production: 11 weeks; first-year ROI: 340%.
Contract intelligence at scale
A legal technology provider implemented a specialized 3B parameter model for contract clause extraction and risk assessment. By training on their proprietary corpus of 2 million contracts, they achieved a 94% F1 score on clause identification—outperforming general-purpose models 3X their size. The architecture processes 10,000 contracts daily at one-tenth the cost of their previous solution, with complete audit trails and explainability. Deployment time: 6 weeks; payback period: 4 months.
Manufacturing intelligence
An industrial equipment manufacturer deployed edge-based 1.5B parameter models across 47 manufacturing facilities for predictive maintenance and quality control. Running on local GPUs, these models process sensor data in real time, trigger maintenance workflows, and generate natural-language reports for operators. The system operates during network outages, meets strict data locality requirements, and reduces unplanned downtime by 41%. Implementation across all sites: 9 weeks; annual savings: $14.2M.
Why SLMs work well
While economic efficiency drives initial interest in SLMs, sustained competitive advantage emerges from four architectural properties.
Deployment velocity
Small models can be fine-tuned, validated, and deployed in weeks rather than quarters. This agility transforms AI from a strategic initiative into a tactical capability, enabling rapid response to market changes, regulatory requirements, or competitive threats.
Precision through specialization
Domain-specific training creates models that deeply understand industry jargon, regulatory frameworks, and operational context. A 7B model trained on your data often outperforms a 70B generalist model on your specific tasks—while running 10X faster and consuming 90% less infrastructure.
Data sovereignty and risk mitigation
On-premises or VPC-deployed SLMs provide complete control over data residency, model behaviour, and compliance posture. This matters increasingly as regulations tighten globally and as organizations grapple with the liability implications of third-party AI decisions.
Operational resilience
Organizations running their own models avoid single-vendor dependencies, API throttling, unexpected pricing changes, and service degradation. Edge deployments enable critical operations to continue during network failures or cloud outages.

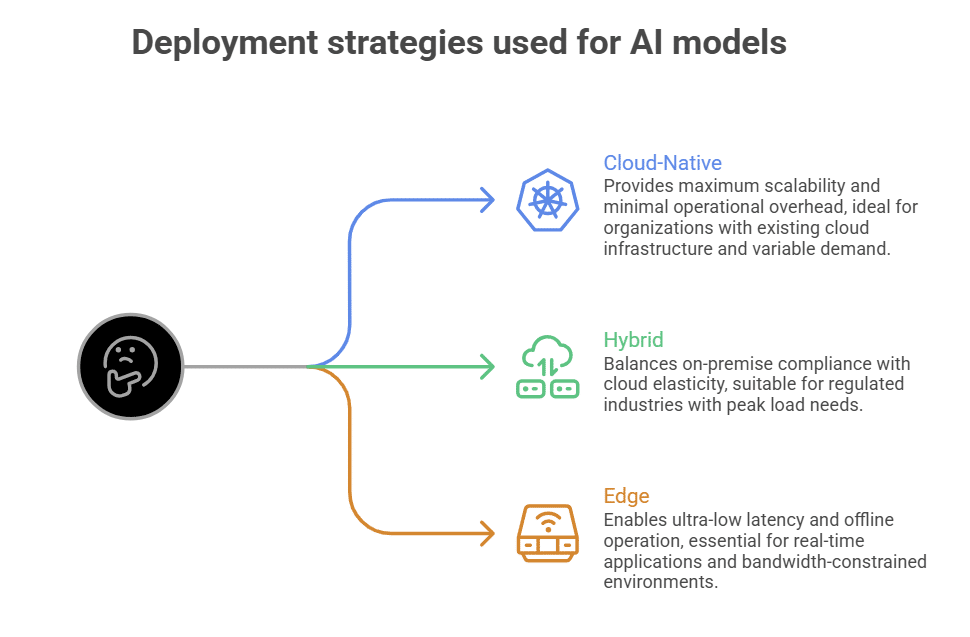
The architecture and deployment: Building for intelligent scale
Successful SLM deployments share a common architectural philosophy: modular, composable, and observable. Rather than monolithic AI platforms, organizations are building layered systems where each component can be independently optimized, scaled, and evolved.
Model foundation (Layer 1)
The base model selection drives all downstream decisions. Modern SLM architectures leverage transformer variants optimized for efficiency: Mistral 7B and Mixtral 8x7B for general intelligence, Phi-3 family for reasoning tasks, Llama 3 variants for balanced performance, and Gemma models for Google ecosystem integration. The choice depends on three factors: task complexity, latency requirements, and available infrastructure.
Critical consideration
Model licence compatibility with target deployment model. Apache 2.0 and MIT licences permit unrestricted commercial use; some licences impose restrictions on derivative works or competitive use.
Data and fine-tuning pipeline (Layer 2)
The differentiator between commodity and competitive advantage. This layer encompasses data curation, quality assurance, synthetic data generation, and continuous training pipelines. Leading implementations use DVC for data versioning, Label Studio or Argilla for annotation workflows, and automated quality filters to maintain training data hygiene.
- Critical consideration: Fine-tuning strategies range from full fine-tuning for maximum performance to LoRA and QLoRA for parameter-efficient adaptation. Organizations typically start with instruction tuning on 1,000-10,000 examples, then iterate based on production feedback. The key is treating fine-tuning as a continuous process, not a one-time event.
Inference and serving infrastructure (Layer 3)
Where architecture meets reality. The inference layer must balance throughput, latency, and cost across diverse deployment targets: cloud, edge, and hybrid configurations. Modern stacks use vLLM or TensorRT-LLM for GPU optimization, delivering 10-30X throughput gains over naive implementations. For CPU-only environments, llama.cpp and GGUF quantization enable surprisingly capable inference on commodity hardware.
- Critical consideration: Production rollout includes model quantization strategy, batching policies, request-routing logic, failover behaviour, and cost allocation. Organizations achieving sub-50ms p95 latency typically employ sophisticated caching, speculative decoding, and continuous batching techniques.
Integration and orchestration (Layer 4)
SLMs rarely operate in isolation. This layer provides retrieval-augmented generation, tool use capabilities, multi-step reasoning, and integration with enterprise systems. LangChain and LlamaIndex provide foundational abstractions; production systems typically extend these with custom components for error handling, retries, circuit breaking, and business logic.
- Key architectural decision: Local-first vs cloud-dependent retrieval. Organizations handling sensitive data increasingly implement on-premises vector stores using Qdrant, Weaviate, or Milvus rather than managed services, ensuring end-to-end data sovereignty.
Observability and governance (Layer 5)
Production AI systems require specialized observability beyond traditional application monitoring. This layer tracks model performance metrics, data drift, latency distributions, cost per inference, and business impact. Tools like Weights & Biases, MLflow, and Langfuse provide experiment tracking and production monitoring. Mature organizations implement real-time alerting on accuracy degradation, automated model rollback, and continuous evaluation against golden datasets.
- Critical consideration: Deployment speed determines competitive impact. Organizations achieving production deployment in under 90 days follow a disciplined progression from proof of concept to scaled operations.
It’s important to identify processes where AI can reduce cycle time, improve accuracy, or enable previously impossible capabilities. Ideal first use cases have clear success metrics, accessible training data, and tolerance for 85-90% accuracy. Avoid starting with mission-critical systems or areas requiring 99%+ precision. Establish a cross-functional team including domain experts, data scientists, infrastructure engineers, and security stakeholders. Define success criteria, budget parameters, and governance framework.
Multiple candidate models must be deployed using Hugging Face, Ollama, or LM Studio for rapid experimentation. Test each model against representative tasks using your actual data. Measure task-specific accuracy, latency, and resource consumption. This phase should feel experimental—testing assumptions, discarding what doesn’t work, and iterating daily. Conduct prompt engineering experiments before committing to fine-tuning; well-crafted prompts can bridge surprising performance gaps.
Curate 1,000-5,000 high-quality examples rather than 100,000 mediocre ones. Use domain experts to validate training data. Implement systematic quality checks: Are instructions clear? Are outputs consistent? Does the data reflect actual business requirements? Begin fine-tuning on cloud-based GPU resources (vast.ai, RunPod, or AWS/GCP/Azure) using parameter-efficient methods such as LoRA. This enables rapid iteration without massive infrastructure investment. Continuously evaluate against holdout test sets.
Deploy infrastructure starting with the inference server, monitoring, and basic orchestration. Use containerization (Docker) and orchestration (Kubernetes or simpler alternatives like Docker Compose for early stages) to enable consistent deployment across environments. Implement comprehensive logging, latency tracking, and cost monitoring from day one. Set up A/B testing infrastructure to compare model performance against baseline systems. Establish incident response procedures and rollback mechanisms before user exposure.
Monitor obsessively. Collect feedback systematically. Measure against the success criteria defined at the start of the design phase. Document lessons, celebrate wins, and prepare for scaled rollout. The goal is proof that the system creates measurable business value, not perfection.
| Layer | Component | Open source tools |
| Model foundation | Base models | Mistral 7B, Mixtral 8x7B, Llama 3.3 70B, Phi-4, Gemma 2 (2B-27B), Qwen2.5 (0.5B-72B) |
| Model hub | Hugging Face Hub, Ollama | |
| Data pipeline | Data versioning | DVC, Git LFS, LakeFS |
| Annotation | Label Studio, Argilla, Prodigy | |
| Synthetic data | NeMo Curator, DataTrove, Lilac | |
| Training and fine-tuning | Training framework | Hugging Face Transformers, Axolotl, LLaMA-Factory, PEFT |
| Distributed training | DeepSpeed, Accelerate, PyTorch FSDP | |
| Experiment tracking | Weights & Biases, MLflow, TensorBoard | |
| Inference infrastructure | GPU inference | vLLM, TensorRT-LLM, Text Generation Inference (TGI), LocalAI |
| CPU inference | llama.cpp, GGML/GGUF, ONNX Runtime | |
| Model serving | Ray Serve, BentoML, KServe, Triton Inference Server | |
| Quantization | bitsandbytes, GPTQ, AWQ, AutoGPTQ | |
| Orchestration | Application framework | LangChain, LlamaIndex, Haystack, Semantic Kernel |
| Vector database | Qdrant, Weaviate, Milvus, Chroma, pgvector | |
| Agent framework | AutoGen, CrewAI, LangGraph, OpenAI Swarm | |
| Deployment | Containerisation | Docker, Podman |
| Orchestration | Kubernetes, Docker Compose, Nomad | |
| CI/CD | GitHub Actions, GitLab CI, Jenkins, ArgoCD | |
| Observability | LLM monitoring | Langfuse, Phoenix, LangSmith (commercial with free tier) |
| Infrastructure | Prometheus, Grafana, Loki, Jaeger | |
| Evaluation | DeepEval, RAGAS, TruLens, PromptFoo | |
| Security and governance | Model security | NeMo Guardrails, Llama Guard, Prompt Armor |
| Model registry | MLflow Model Registry, Hugging Face Hub (private repos) |
Navigating the challenges
Successful deployments encounter predictable obstacles. Anticipating these challenges enables proactive mitigation rather than reactive crisis management.
The cold start problem
Start with synthetic data generation using larger models or commercial APIs to create an initial training corpus. Use active learning to identify high-value examples for human annotation. Leverage transfer learning from similar domains. Consider data partnerships or licensed datasets for rapid bootstrapping. Many organizations achieve surprising results with just 500-1000 carefully curated examples.
Infrastructure complexity
Adopt managed inference platforms like Together AI, Replicate, or Modal for early-stage deployments. As scale increases, evaluate build vs buy decisions based on true total cost of ownership—including engineering time, opportunity cost, and strategic value of in-house capability. Many organizations reach optimal economics with hybrid approaches — managed services for experimentation and low-volume workloads, self-hosted for high-volume production.
Model performance degradation
Implement continuous monitoring with automated alerts on accuracy drops. Establish feedback loops capturing production errors for retraining. Schedule regular model refresh cycles—monthly or quarterly, depending on domain volatility. Maintain shadow deployments of candidate models to enable rapid switching when primary models degrade. Treat model operations as ongoing programmes, not one-time projects.
Organizational resistance
Design for human-in-the-loop workflows initially. Present AI outputs as recommendations requiring approval rather than automated actions. Provide transparency into model reasoning through attention visualization or chain-of-thought outputs. Measure and communicate impact in business terms: time saved, revenue generated, errors prevented. Build trust through consistent performance and clear escalation paths when the system encounters edge cases.
Security and compliance concerns
Engage security and compliance stakeholders from day one. Deploy in secure environments with appropriate network isolation, encryption at rest and in transit, and access controls. Implement comprehensive audit logging. For sensitive data, use on-premises or VPC deployments with no data egress. Document data handling procedures, model training provenance, and decision-making processes. Many organizations find that local SLM deployments actually simplify compliance compared to third-party API usage.
Best practices for SLM deployment
Organizations operating SLMs at scale converge on similar operational patterns. These practices separate experimental deployments from business-critical systems.
Resist the temptation to build general-purpose AI platforms. Begin with a single, well-defined use case with clear success metrics. Prove value. Then expand systematically to adjacent use cases, leveraging shared infrastructure and learned expertise. Organizations attempting to boil the ocean with universal AI initiatives consistently underdeliver compared to those pursuing focused, sequential deployments.
The performance ceiling is determined by training data quality, not model size. Allocate more resources to data curation, cleaning, and validation than to infrastructure or compute. Establish clear data quality standards. Review training examples manually. Remove ambiguous or contradictory data. This unglamorous work drives outsized performance improvements.
Modern quantization techniques enable 4-bit or 8-bit inference with minimal accuracy loss, reducing memory requirements by 4-8x and increasing throughput proportionally. Every SLM deployment should evaluate quantized variants. The performance-efficiency tradeoff typically favours quantization except for the most demanding tasks. This single optimization can eliminate 75% of infrastructure costs.
Automated evaluation against golden datasets should run on every code commit, model update, and production deployment. Maintain diverse test suites covering common cases, edge cases, adversarial inputs, and business-critical scenarios. Track metrics over time to detect gradual degradation. Production systems should continuously evaluate a sample of outputs against human judgment, feeding this data back into training pipelines.
Assume your current model will be replaced within 6-12 months. Abstract model interfaces to enable swapping base models without application. Assume your current model will be replaced within 6-12 months. Abstract model interfaces to enable swapping base models without application rewrites. Maintain version-controlled model registries. Implement blue-green deployment patterns enabling zero-downtime upgrades. The AI landscape evolves rapidly; architectural flexibility provides a lasting competitive advantage while specific model choices do not.
Technical metrics like perplexity and BLEU scores matter less than business outcomes. Define success in terms stakeholders care about: customer satisfaction scores, processing time reduction, error rate improvement, revenue impact, or cost savings. Connect AI system performance directly to business KPIs. This alignment ensures continued investment and organizational support.
Open source tech stack by SLM reference architecture layer
The stack in the table above enables progressive sophistication. Organizations can begin with a simple configuration: base model, basic inference, minimal monitoring, and systematically add capabilities as requirements evolve. Each layer remains independently swappable, preventing vendor lock-in and enabling continuous optimization.
The strategic opportunity in small language models extends beyond current cost savings or operational improvements. Organizations building competency in SLM deployment are establishing capabilities that compound over time: proprietary training data, domain-specific model expertise, optimized inference infrastructure, and institutional knowledge of what works.
Early movers are already seeing network effects. Each production deployment generates training data for the next iteration. Each solved integration problem becomes reusable infrastructure. Each successful use case builds organizational confidence and accelerates subsequent deployments. The gap between AI leaders and followers widens not through access to better models—those are freely available—but through their ability to deploy them systematically.
The question facing leadership teams is increasingly clear. As open source models approach or exceed proprietary model performance across narrow domains, and as deployment tools mature towards commodity status, competitive advantage accrues to organizations that move fastest from strategy to architecture to production at scale.
The quiet revolution in efficient AI is creating a window of opportunity measured in quarters, not years. Organizations that master the architecture, operations, and business integration of small language models are building sustainable advantages in an AI-enabled world. Those who wait for perfect clarity or mature platforms may find that the advantage has already been claimed by faster-moving competitors.
The infrastructure exists. The models are available. The case studies validate the approach. The remaining variable is organizational will and execution velocity. The leaders of 2026 will be defined not by who talks about AI strategy, but by who deploys it into production this quarter.
Disclaimer: The opinions expressed in this article are the author’s and do not reflect the views of the organisation he works in.
















