






























































Colaboratory is a free research project by Google created to help disseminate machine learning education and research. It’s a Jupyter notebook environment that requires no setup and runs entirely on the cloud. Colaboratory can be live synced with Google Drive, and can be shared just as you share Google docs or sheets.
To work with today’s high performance and supercomputing applications associated with Big Data and deep learning, there is a need to integrate specialised hardware that can process the data sets with greater speed and accuracy. So there is a need to integrate Graphics Processing Units (GPUs) that can perform parallel computations to provide the maximum speed. In traditional Central Processing Units (CPUs) there are multiple cores that can process the computations. GPU computing integrates these hundreds of cores with the GPU as the co-processor to accelerate the CPU speed for engineering and scientific computations.
The concept of GPUs for system acceleration was first promoted by NVIDIA in 1999, with the GeForce 256 as the first GPU. NVIDIA GPUs have paved the way forward for the industry, and will provide a 1000X increase in computing speed by 2025.
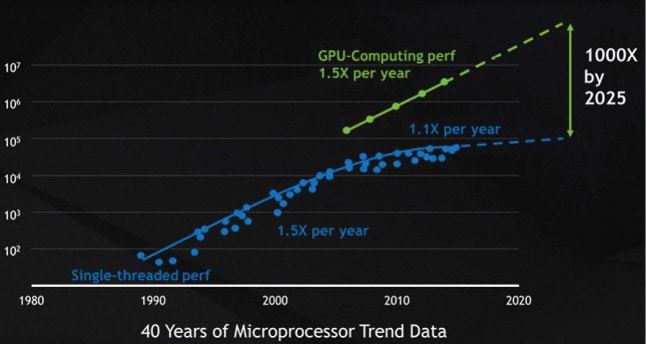
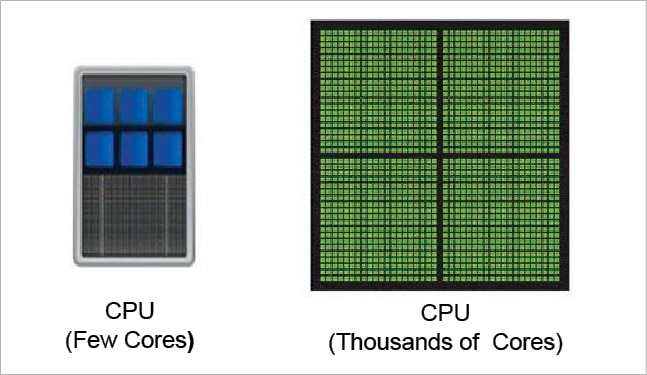
The global market size of GPUs is increasing rapidly. A report by Global Market Insights estimates the market size of GPU as a Service as over US$ 200 million in 2016. The report predicts that the compound annual growth rate (CAGR) of the GPU market will exceed 30 per cent till 2024.
Traditionally, GPU installation has been a costly affair. In addition, the computer needs to have a GPU card slot. To negate the GPU cost factor, there are many cloud based services that provide GPUs on the cloud. The services of remote computers that have GPUs can be hired without purchasing the GPU and installing it in the local system.
Prominent cloud services for deep learning and Big Data analytics
Table 1 gives a list of a few prominent cloud services that can be used for deep learning and Big Data based implementations, depending upon the usage. Many of these cloud service providers offer integration with the GPU so that high performance scientific computations can be carried out. Remote virtual servers are provided with the attached GPU for deep learning, machine learning and Big Data analytics.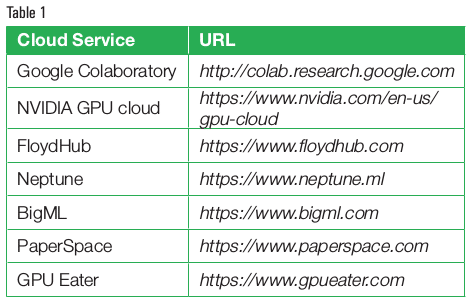 Using cloud based services, TensorFlow, Keras, Caffe, PyTorch and other Python based code can be implemented for deep learning and machine learning.
Using cloud based services, TensorFlow, Keras, Caffe, PyTorch and other Python based code can be implemented for deep learning and machine learning.
Using Google Colaboratory
Google Colaboratory provides the Tesla GPU based ‘free cloud’ for deep learning and scientific computations. The code for Keras, Tensorflow and PyTorch can be directly implemented on the free Tesla K80 GPU. The cloud service provides 4992 CUDA cores and a memory bandwidth of 480GB/sec (240GB/sec per GPU).
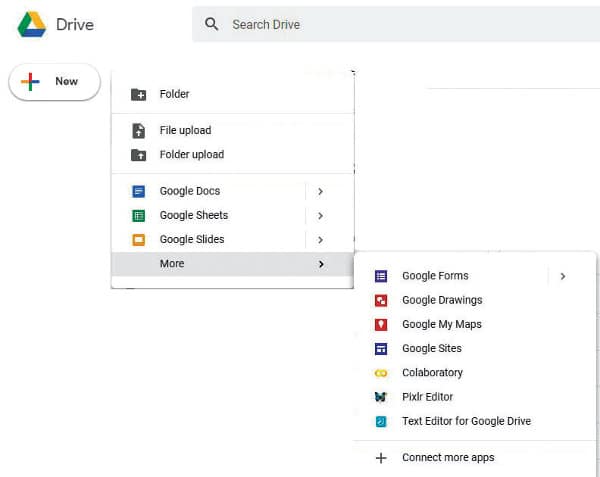
In every Google account, there is an option to enable the Google Colaboratory. In Google Drive, on the top left, click on ‘New’. Then click on ‘More’ to activate Google Colaboratory.
Once Google Colaboratory is enabled, Jupyter notebooks and the file explorer are displayed. In this panel, the data set and the Python code can be uploaded. In addition, the source code of Python can be directly executed in the cloud based Jupyter notebooks on Google Colaboratory.

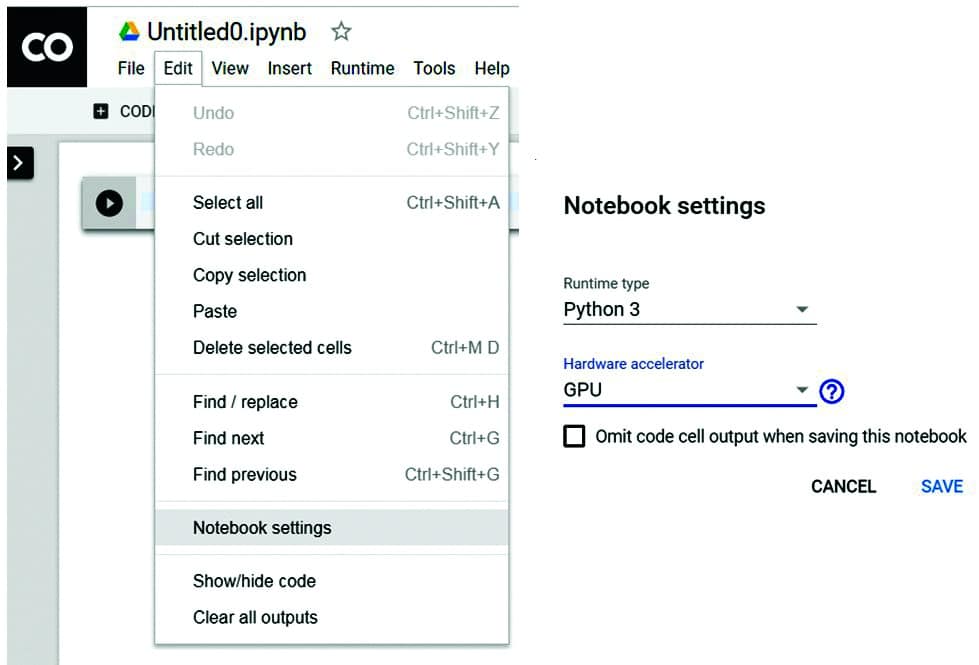
If the program source code is to be executed using GPU based computing, it must first be activated in Jupyter. In the ‘Edit’ menu, the option ‘Notebook Settings’ activates the GPU as a hardware accelerator. Once this option is selected, the code is executed using the GPU and generates the results with enormous speed.
The GPU based cloud of Google Colaboratory can be viewed with the basic instructions. Using these instructions, details like memory, processor, threads, etc, can be displayed so that the programmer comes to know the actual configuration of the cloud server of Google Colaboratory.
Instructions that can be directly executed on the Jupyter notebooks in Google Colaboratory are given below.
To display the GPU name and the count, give the following instructions:
!nvidia-smi -L !nvidia-smi !lscpu | grep ‘Model’
To display the number of sockets and available slots for physical processors, give the following command:
!lscpu | grep ‘Details of Socket’
To view the number of cores in each processor for scientific and engineering computations, issue the following instruction:
!lscpu | grep ‘Number of Cores / Socket:’
To display the number of threads in each core for parallel computations, give the following commands:
!lscpu | grep ‘Thread(s) per Core’ !lscpu | grep “L3 Cache”
To display clock details, type the following command:
!lscpu | grep “MHz”
To view the memory available, give this instruction:
!cat /proc/meminfo | grep ‘MemAvailable’
To view the hard disk available for use, give this command:
!df –hT /
The overall details that are displayed are:
- CPU
- 1 single core hyper threaded (1 core, 2 threads)
- Xeon processors
- 3GHz (No turbo boost)
- 45MB cache
- GPU
- 1xTesla K80
- Compute 3.7
- 2496 CUDA cores
- 12GB GDDR5 VRAM
- RAM: ~12.6 GB
- Disk: ~33 GB
- Idle time: 90 minutes
It should be noted that in Google Colaboratory, the disk, RAM, VRAM, CPU cache, etc, and all other data on our allotted virtual machine will be erased after every 12 hours. This means that the access is temporary.
Uploading and extraction of Big Data files
The Big Data files can be uploaded on Google Colaboratory in ZIP or RAR compression formats. To uncompress the files, the related tool can be installed dynamically on Colaboratory.
To upload files dynamically, use the following commands:
from google.colab import files uploaded = files.upload()
On execution, the window for selecting the file from the local hard disk will open and the files will be uploaded to the cloud.
For installation of p7zip to extract the compressed files, give these commands:
!apt-get install p7zip-full !p7zip -d filename.tar.7z !tar -xvf filename.tar
To extract the compressed files using p7zip, give the following command:
!unzip filename.zip
To remove the file from the server and to list the existing files, type:
!rm filename.zip !ls
Using TensorFlow and Keras in Google Colaboratory
Google Colaboratory is equipped with TensorFlow and Keras. These integrate the framework and APIs for deep learning. Python based libraries of SciPy and NumPy are also associated so that the numerical and scientific computations can be done effectively. A number of benchmark data sets are available, which can be processed with TensorFlow and Keras in Colaboratory.
Within the panel of Google Colaboratory, there are a number of examples and live scenarios that can be executed in real-time. For example, the URL https://colab.research.google.com/notebooks/gpu.ipynb presents the output from a GPU based computation of deep learning. In this implementation, the speed of the GPU is 45 times that of a traditional CPU. Other scenarios and examples can be explored in a similar way.
Installation of PyTorch on Google Colaboratory
PyTorch is one of the powerful and widely used libraries for deep learning written in Python. It can be installed on Google Colaboratory with the execution of the following instructions on the Jupyter notebook:
!pip3 install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl
!pip3 install torchvision
from os import path
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = ‘{}{}-{}’.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
accelerator = ‘cu80’ if path.exists(‘/opt/bin/nvidia-smi’) else ‘cpu’
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.3.0.post4-{platform}-linux_x86_64.whl torchvision
import torch
Scope for research and development
Google Colaboratory can be used by research scholars and practitioners who do not have onboard access to a GPU. To work with deep learning and high performance computing, GPU based computations, which are traditionally costly, are required. Rather than purchasing and working with the GPU, GPU based cloud services like Google Colaboratory prove better and cost-effective. Big Data files can be directly uploaded on the Google Colaboratory dashboard for processing and analytics. In addition, it can be live synced with Google Drive so that the data sets uploaded on the Drive can be accessed and processed in the working dashboard of Google Colaboratory.
Implementations that need large resources such as biometric applications, signal processing and Big Data visualisation can also be processed in the Google Colaboratory with better speed and performance.

















{kind=link}