






























































Whisper, OpenAI’s latest speech recognition model, opens doors to seamless speech-to-text transcription, revolutionising communication across languages.
Today, generative AI has become the hottest topic and has the highest buzz in the field of technology. Everyone wants to know what it is and how to use it the best way they can. GenAI is basically the subfield of artificial intelligence designed to create new content, whether it be images, text, audio, or any other form of binary or non-binary data. This is in accordance with the data upon which the model has been trained. Today, OpenAI’s ChatGPT is one of the most popular generative AI models that everyone is interested in. OpenAI has also released another amazing model, known as Whisper, which we will focus on here.
Whisper is an open source machine learning model that can recognise and transcribe speech, and can work with a wide range of languages. Given an audio input, it can detect the language, generate the transcription in that language, and then translate it into English.
Speech recognition has been a topic of research for a long time now. The earliest methods used techniques such as time warping and Hidden Markov Models (HMM). Eventually, like most applications of data science, deep learning approaches became prevalent in this field. With the help of Big Data technologies, deep learning proved to be very effective. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) were used majorly. The Transformers library introduced by Google disrupted most machine learning tasks and applications as it proved to be incredibly useful. Whisper has been built using this library, which is based on the encoder-decoder format. It can be said that Whisper is a major milestone in the field of speech-to-text transcriptions.
So let’s learn how to use Whisper.
First, let us install Whisper. This can be done using the following command:
pip install whisper (base) Jishnus-MacBook-Air:~ jishnusaurav$ pip install whisper Collecting whisper Downloading whisper-1.1.10.tar.gz (42 kB) Preparing metadata (setup.py) ... done Requirement already satisfied: six in ./anaconda3/lib/python3.11/site-packages (from whisper) (1.16.0) Building wheels for collected packages: whisper Building wheel for whisper (setup.py) ... done Created wheel for whisper: filename=whisper-1.1.10-py3-none-any.whl size=41121 sha256-8c8051947499458bc06c3b1ab1cff2f 3005604624c1fca58271356f596241070 Stored in directory: /Users/jishnusaurav/Library/Caches/pip/wheels/21/65/ee/4e6672aabfa486d3341a39a04f8f87c77e5156149299b5a7d0 Successfully built whisper Installing collected packages: whisper Successfully installed whisper-1.1.10
Sometimes, you may encounter an error. In that case, you can use the command shown in Figure 1.
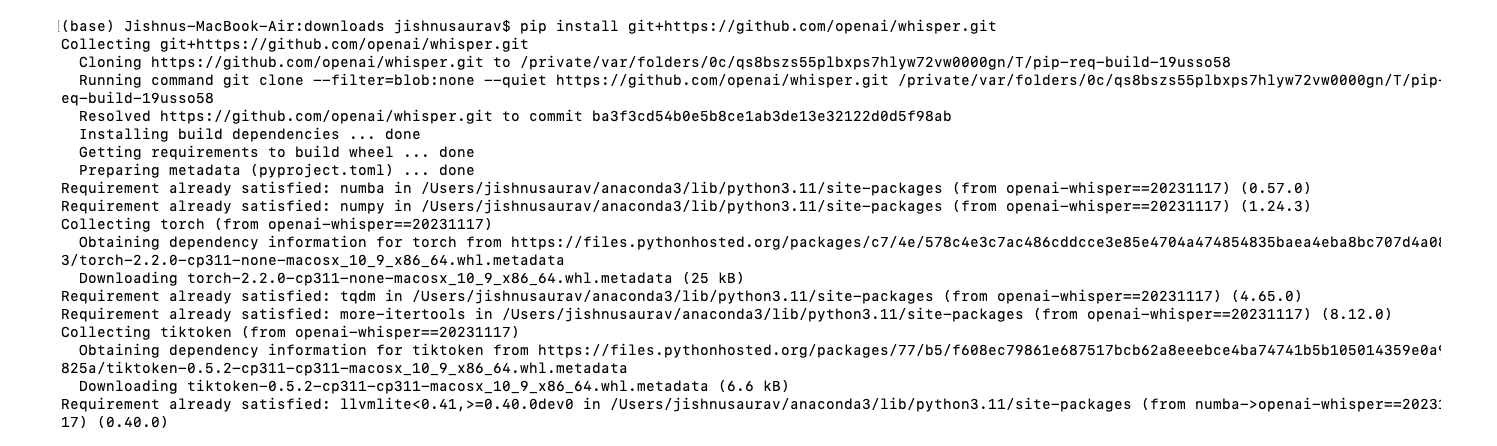
Next, we need to install ffmpeg. If you are using a Mac, you can use the command shown in Figure 2.
brew install ffmpeg
Otherwise, you can use the following command:
sudo apt update && sudo apt install ffmpeg
Now that we are all set and ready to use the Whisper model, let us proceed!
You can use the following command. I recorded a sample audio and will be using it here. Alternatively, you can also use audio files from the internet.
whisper sample_audio.wav (base) Jishnus-MacBook-Air: downloads jishnusaurav$ whisper audio_sample.wav /Users/jishnusaurav/anaconda3/lib/python3.11/site-packages/whisper/transcribe.py:126: UserWarning: FP16 is not supported on CPU; using FP32 instead warnings.warn(“FP16 is not supported on CPU; using FP32 instead”) Detecting language using up to the first 30 seconds. Use --language to specify the language Detected language: English [00:00.000 --> 00:07.000] hi this is jishnu how are you doing today
As you can see, the transcription turned out to be perfect.
You can also try this out with other languages.
I have recorded an audio file in Hindi and used the following command. This gives us the perfect transcription as a result.
whisper audio_sample_hindi.wav --language Hindi (base) Jishnus-MacBook-Air: downloads jishnusaurav$ whisper audio_sample_hindi.wav --language Hindi /Users/jishnusaurav/anaconda3/lib/python3.11/site-packages/whisper/transcribe.py:126: UserWarning: FP16 is not supported on CPU; using FP32 instead warnings.warn(“FP16 is not supported on CPU; using FP32 instead”) [00:00.000 --> 00:05.000] मेरा नाम िजशनू है और मैं बहुत अच्छ इन्सान हूं (base) Jishnus-MacBook-Air: downloads jishnusaurav$
You can either specify the language using the language argument, or you can provide Whisper with the audio file directly, and it will detect the language automatically, using the first few seconds of the audio file and provide you with the transcription.
You can also obtain the English translation using the command given below. You can use the – translate parameter for this purpose as an argument and, as you can see, you get the perfect translation.
[(base) Jishnus-MacBook-Air: downloads jishnusaurav$ whisper audio_sample_hindi.wav --language Hindi --task translate ]
/Users/jishnusaurav/anaconda3/lib/python3.11/site-packages/whisper/transcribe.py:126: UserWarning: FP16 is not suppo
rted on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
[00:00.000 --> 00:05.000] My name is Jishnu and I am a very good person.
(base) Jishnus-MacBook-Air: downloads jishnusaurav$
We can also run Whisper using Python code. In case you want to run it on a larger number of files, the basic code is shown below. This code can be further updated to be used for batch processing, etc.
import whisper model = whisper.load_model(“base”) result = model.transcribe(“audio_sample.wav”) print(result[“text”])
That was it! You have now successfully used the OpenAI Whisper model to perform speech-to-text transcription. There are numerous uses of speech-to-text, from improving customer service to obtaining official transcripts. You have taken your first step towards automating such processes. You can use this as a foundation and learn more from the official documentation to build more applications and use cases for Whisper. The Whisper official website and Git repository are shared below.















