

This new series of articles will take readers on a journey that explores the regular expressions in various programming languages. The first article in this series takes a detailed look at the use of regular expressions in Python.
Often when people discuss regular expressions, they use the term ‘regex’, which leads to a mix up between regular expressions and the tools that use regular expressions for string searching. A classic example of this sort of mistake is people confusing regular expressions and grep, a UNIX utility for pattern matching. grep is a very powerful tool but whatever it may be, it definitely is not a synonym for regular expressions. A regular expression is not a tool but rather, a concept in formal language theory that defines how a sequence of characters can define a search pattern. On the other hand, grep is a tool that uses regular expressions for pattern matching. But there are a lot of other utilities and programming languages that use regular expressions for pattern matching.
The main problem with regular expressions is that the syntax as well as the manner of calling regular expressions differs for the various languages, with some of them closely resembling each other, while others having major differences between them. So, in this series of articles, we discuss how to use regular expressions in the following six programming languages — Python, Perl, Java, JavaScript, C++ and PHP. This doesn’t mean that these are the only programming languages or software that support regular expressions. There are a lot of others that do. For example, you can find regular expressions in programming languages like AWK, Ruby, Tcl, etc, and in software like sed, MySQL, PostgreSQL, etc. Moreover, even absolute beginners typing *.pdf in their search boxes on Windows to search all the PDF files in their system are using regular expressions. Since a lot of articles about regular expressions cover grep in detail, this article will not cover the most famous tool that uses regular expressions. In fact, the one tool that solely depends on regular expressions for its survival is grep. The main reason one needs to study regular expressions is that many results obtained from powerful data mining tools like Hadoop and Weka can often be replicated by using simple regular expressions.
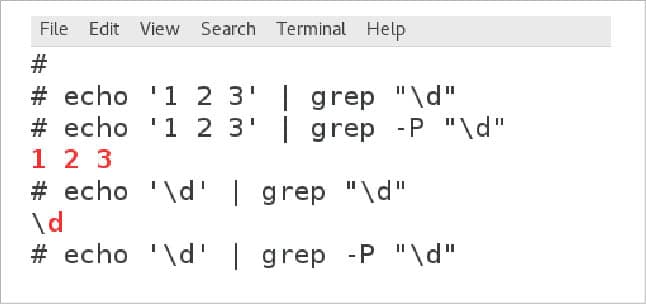
Some of the popular regular expression syntaxes include Perl-style, POSIX-style, Emacs-style, etc. The syntax of the regular expression used in a tool or programming language depends on the regular expression engine used in it. The ability to use more than one regular expression engine in a single tool itself leads to the support of more than one regular expression style. For example, the immensely popular regular expression tool by GNU called grep, by default, uses a regular expression engine that supports POSIX regular expressions. But it is also possible to use Perl-style regular expressions in grep by enabling the option -P. In Perl-style regular expressions, the notation \d defines a pattern with a digit, whereas in POSIX-style regular expressions, this regular expression does not have any special meaning. So, in the default mode of this regular expression, it will match the letter d and not a digit. But if the utility grep is using the Perl-style regular expressions then a digit will be matched by the same regular expression. In this series, all the regular expressions, and the strings and results obtained by using them are italicised to highlight them from normal text.
Figure 1 shows the output obtained when the default mode and the Perl style regular expressions are used with grep. The texts highlighted in red are the portions of the string matched by the given regular expression. In the figure, you can observe that the same regular expression while processing the same text in two different modes, matches different patterns.
As a side note, I would like to point out that all pattern matching utilities called grep are not the same. There are minor differences between the different implementations of grep. For example, all the implementations by GNU, IBM AIX and Solaris differ at least on certain functionalities. There are also variants of grep like egrep, fgrep, etc, which differ from grep in functionality as well as syntax.
Regular expressions in Python
Python is a general-purpose programming language invented by Guido van Rossum. The two active versions of it are Python 2 and Python 3, with Python 2.7 most likely being the last version of Python 2 and Python 3.6 being the current stable version of Python 3. Since we are concentrating on regular expressions in Python, we don’t need to worry too much about the general differences between these two versions. Since both Python 2 and Python 3 use the same module for handling regular expressions, there is no real difference between the two. I have executed all the scripts in this article with Python 2.7.12. The Python module that supports regular expressions is called re. The module re supports Perl-style regular expressions by using a regular expression engine called PCRE (Perl Compatible Regular Expressions). There is another module called regex which also supports regular expressions in Python. Even though this module offers some additional features when compared with the module re, we will use the module re in this tutorial for two reasons. First, regex is a third-party module whereas re is part of the Python standard library. Second, regex has an old and a new version, known respectively as version 0 and version 1 with major differences between the two. This makes a study of the module regex even more difficult.
The module re
Python regular expressions simplify the task of pattern matching a lot by specifying a pattern that can match strings. The first thing you must do is import the module re with the command import re. Python does not support a new type for representing regular expressions; instead, strings are used for representing regular expressions. For this reason, a regular expression should be compiled into a pattern object, having methods for various operations like searching for patterns, performing string substitutions, etc. If you want to search for the word ‘UNIX’, the required regular expression is the word itself, i.e., UNIX. So, this string should be compiled with the function compile( ) of module re. The required command is pat = re.compile(‘UNIX’), where the object pat contains the compiled regular expression pattern object.
Optional flags of the function compile( )
The function compile( ) has a lot of optional flags. Some of the important ones are DOTALL or S, IGNORECASE or I, LOCALE or L, MULTILINE or M, VERBOSE or X, and UNICODE or U. DOTALL changes the behaviour of the special symbol dot (.). With this flag enabled, even the new line character \n will be matched by the special symbol dot (.). IGNORECASE allows case insensitive search. LOCALE will enable a locale-aware search by considering the properties of the system being used. This allows users to perform searches based on the language preferences of their system. MULTILINE enables separate search on multiple lines in a single string. VERBOSE allows the creation of more readable regular expressions. UNICODE allows searches dependent on the Unicode character properties database.
Now, consider the regular expression with the flag IGNORECASE enabled, pat = re.compile(‘UNIX’, re.IGNORECASE). What are the strings that will be matched by this regular expression? Well, we are performing a case insensitive search on the word ‘UNIX’, so words like ‘UNIX’, ‘Unix’, ‘unix’ and even ‘uNiX’ will be matched by the given regular expression.
A Python script for regular expression processing
Consider the text file named file1.txt shown below to understand how a regular expression based pattern match works in Python.
unix is an operating system Unix is an Operating System UNIX IS an OPERATING SYSTEM Linux is also an Operating System
Consider the Python script run.py, which reads a file name from the keyboard and opens it. The program then carries out a line by line search on the file for the pattern given by the compiled regular expression object called pat. The object pat describing the regular expression is compiled in the Python shell and not in the script, so that the same Python script run.py can be called to process different regular expressions without any modification to the script. The Python shell can be invoked by typing the command python in the terminal. The script run.py reads the file name from the keyboard; so different text files can be processed with this Python script.
filename = raw_input('Enter File Name to Process: ')
with open(filename) as fn:
for line in fn:
m = pat.search(line)
if m:
print m.group( )
Now it is time to understand how the script run.py works. The name of the file to be processed is read into a variable called the filename. The with statement of Python, introduced in Python 2.5, is used to open and close the required file. The file is then read line by line to find a match for the required regular expression with a for loop. The line of code, m = pat.search(line) searches for the pattern described by the regular expression in the compiled pattern object ‘pat’ in the string stored in the variable ‘line’. It returns a ‘Match’ object if a match is found or a ‘None’ object if a match is not found. This returned object is saved in the object ‘m’ for further processing. The line of code ‘if m:’ checks whether the object ‘m’ contains a ‘Match’ object or a ‘None’ object. If object ‘m’ is ‘None’ then the if conditional fails and no action is taken. But on the other hand if ‘m’ contains a ‘Match’ object, then the matched string is printed on the screen by the line print m.group( ). The method group( ) is defined for the object ‘Match’ and it returns the string matched by the regular expression.
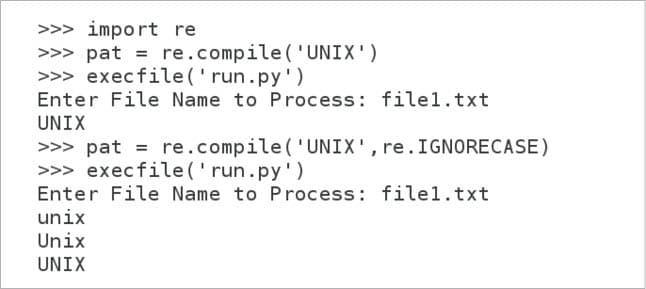
Figure 2 shows the output obtained by the regular expression with and without the compiler flag IGNORECASE enabled. If you observe the figure carefully, you will see that the module re is imported first and then the pattern is compiled in the Python shell with the line of code, pat = re.compile(‘UNIX’). Then the line of code, execfile(run.py) executes the Python script run.py and the output of this case-sensitive search results in the match of a single string UNIX. As mentioned earlier, the function compile( ) has many optional flags. The pattern object pat is recompiled a second time with the line of code, pat = re.compile(‘UNIX’,re.IGNORECASE) executed on the Python shell with the flag IGNORECASE enabled. The script run.py is executed again and this case-insensitive search results in the match of strings unix, Unix and UNIX.
In the script run.py, if you replace the line of code print m.group( ) with the code print line, the whole line in which a match is found will be printed. This Python script is called line.py. For example, for the pattern, pat = re.compile(‘UNIX’) the modified script will print UNIX IS AN OPERATING SYSTEM instead of UNIX.
The method group( ) is not the only method defined for the object match. The other methods defined are start( ), end( ), span( ) and groups( ). The method start( ) returns the starting position of the match and the method end( ) returns the ending position of the match. The method span( ) returns the starting and ending positions as a tuple. For example, if you replace the line of code print m.group( ) in the script run.py with the code print m.span( ) with the pattern pat = re.compile(‘UNIX’) then the tuple (0,4) will be printed. This Python script is called span.py. In order to understand the working of groups( ) method we need to understand the meaning of the special symbols used in Python regular expressions.
Special symbols in Python regular expressions
The following characters: . (dot), ^ (caret), $ (dollar), * (asterisk), + (plus), ? (question mark), { (opening curly bracket), } (closing curly bracket), [ (opening square bracket), ] (closing square bracket), \ (backslash), | (pipe), ( (opening parenthesis) and ) (closing parenthesis) are the special symbols used in Python regular expressions. They have special meaning and hence using them in a regular expression will not lead to a literal match for these characters.
The most important special symbol is backslash (\) which is used for two purposes. First, backslash can be used to create more meta characters in regular expressions. For example, \d means any decimal digit, \D means any non-decimal digit, \s means any whitespace character, \S means any non-whitespace character and \n, \t, etc, all have their usual meaning. Second, if a special symbol is prefixed with a backslash, then its special meaning is removed and thereby results in the literal match of that special symbol. For example, \\ matches a \ and \$ matches a $. The backslash creates some problems because it is a special symbol in Python regular expressions as well as Python strings. So, if you want to search for the pattern \t in a string, you first need to precede \ with another \ for a literal match resulting in the string \\t. But when you are passing this as an argument to re.compile( ) as a string, you have to precede each of these \ with yet another \ because Python strings also consider \ as a special symbol. Thus, the simply insane regular expression \\\\t only will result in a match for \t. In order to overcome this problem, Python regular expressions use the raw string notation which keeps the regular expressions simple. In raw string notation, every regular expression string is prefixed with an r so that you don’t need to add backslash multiple times. So the following two regular expressions: pat = re.compile(‘\\\\t’) and pat = re.compile(r’\\t’) will match the same pattern \t.
The symbol * results in the matching of zero or more repetitions of the preceding regular expression. The regular expression ab* will match all the strings starting with an a and ending with zero or more b’s. The set of all strings matched by the regular expression is {a, ab, abb, abbb, …}. The symbol + results in the matching of one or more repetitions of the preceding regular expression. The regular expression ab+ will match all the strings starting with an a and ending with one or more b’s. The set of all strings matched by the regular expression is {ab, abb, abbb, …}. The difference between the two is that ab* will match the single character string a, whereas ab+ will not match this string. The symbol ? results in the matching of zero or one repetition of the preceding regular expression. The regular expression ‘ab?’ will match the strings a and ab.
The two symbols [ and ] are used to denote a character class. For example, [abc] will match all strings having the letters a, b or c. A hyphen can be used to denote a set of characters. The regular expression [a-z] matches all strings having lower case letters. Inside the square brackets used for specifying the character class, all the special characters will lose their special meaning. [ab*] matches strings containing the characters a, b or *.
The caret symbol ^ has two purposes. First, it checks for a match at the beginning of a string. ^a matches all the strings starting with an a. Second, the caret symbol inside square brackets means negation. ^[^a] matches all the lines that start with a character other than a. So, a line like aaabbb will not be matched whereas a line like bbbaaa will be matched. The symbol $ matches at the end of a string. a$ will result in the matching of all the strings ending with an a.

As explained earlier, the special symbol dot (.) results in the match of any character except the new line character \n, and the DOTALL flag of compile( ) will result in a match of even a new line character. a.c will match strings like aac, abc, acc, a9c, etc. The symbol | is the or operator of a regular expression. black|white will match the strings with the sub-strings, black or white. So, strings like blackboard, whitewash, black & white, etc, will be matched by the regular expression.
The special symbols, opening and closing curly brackets, are used for searching repeating patterns. This is the one notation that has confused many people who use regular expressions. I would like to analyse why this occurs. Every textbook and article on regular expressions declares that the regular expression a{m} matches all the patterns with m number of a’s, and rightly so. Now consider the contents of the text file file2.txt.
a aa aaa aaaa aaaaa
Let us have the following pattern: pat = re.compile(‘a{3}’) executed on the Python terminal and then call our script run.py to do the rest. You might expect to see just one line selected, the line aaa. But the output in Figure 3 shows you that the lines, aaa, aaaa and aaaaa are also matched by this pattern because the string aaa is printed thrice. The textbook definition kind of suggests to you that only aaa should be matched but you are getting much more than that selected. Most of the textbooks that deal with regular expressions fail to explain this anomaly and that is the one point I would like to clarify once and for all, in this article, if nothing else. Theoretical Computer Science 101 says that finite automata do not have the ability to count. Regular expressions and finite automata are different ways of describing the same thing. I can’t explain this any further but you have to believe me on this. Now what is the reason for three lines getting selected instead of the single line aaa? If you look at the two additional lines selected, aaaa and aaaaa, both contain the sub-string, aaa. That again tells us regular expressions are not counting; instead, they match for patterns and nothing more.
The other possibilities with this notation are a{,m} which searches for patterns with m or less number of a’s; a{m,} which searches for patterns with m or more a’s; and a{m,n} which searches for patterns with m to n number of a’s, where m can be any integer constant. But do remember that just like a{m}, the regular expressions a{,m} and a{m,n} will also lead to counter intuitive results due to the same reasons mentioned earlier.
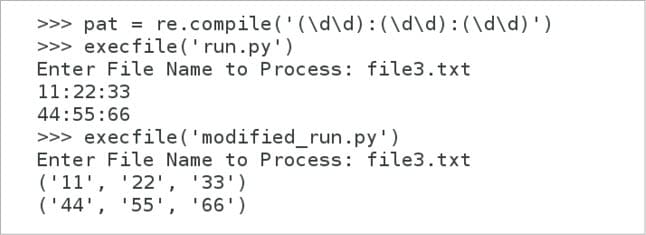
The last two special symbols to be explained are the opening and closing parenthesis. These are used to indicate the start and end of a group. For example, (abc)+ will match strings like abc, abcabc, abcabcabc, etc. The contents of a group can be retrieved after a match, and can be used to match with the later parts of a string with the \number special sequence. The groups( ) method of the match object left unexplained earlier can also be discussed now. Let us assume we are searching for a pattern where three two-digit numbers are separated by a colon, like 11:22:33, 44:55:66, etc. Then one possible regular expression is (\d\d):(\d\d):(\d\d). The text file file3.txt contains the following text.
11:22:33 aa:bb:cc dd:cc:ee 44:55:66
Now with the command, pat = re.compile(‘(\d\d):(\d\d):(\d\d)’) and the script run.py executed on the Python shell, we will get the output shown in Figure 4. This time, there are no surprises; the output shown on the screen is as expected. The figure also shows the execution of a modified script modified_run.py with the line of code print m.group( ) in run.py replaced with the line print m.groups( ). From the figure, it is clear that the groups( ) method of the match object returns a tuple with all the selected values, unlike the group( ) method which returns a string.
Functions in module re
We have already discussed the functions compile( ) and search( ) in the module re. There are also other functions like match( ), split( ), findall( ), sub( ), escape( ), purge( ), etc, in the module re. The function match( ) is used for matching at the beginning of a string with the given regular expression pattern. For example, after executing the command, pat = re.compile(‘UNIX’) in the Python shell, the command, pat.match(“OS is UNIX”) will not give a match, whereas the command pat.match(“UNIX is OS”) will give a match. The function split( ) splits a string by the occurrences of the specified regular expression pattern. The command, re.split(‘\d’, ‘a1b2c3’) returns the list of elements selected. In this case, the selected list is [‘a’, ‘b’, ‘c’] because the separating character is a decimal digit.
The function findall( ) returns all the non-overlapping matches of a pattern in the given string, as a list of strings. The command, print re.findall(‘aba’, ‘abababa’) will return the list [‘aba’, ‘aba’] as the result. In this case, only two occurrences of the strings, aba, are found because findall( ) searches for non-overlapping matches of a string. Regular expressions are generally used for pattern matching, but Python is a very powerful programming language and this makes even its regular expressions far more powerful than the ordinary. An instance of the enhanced power of the Python regular expressions can be found in the function sub( ), which returns the string obtained by replacing the leftmost non-overlapping occurrences of the given regular expression in a string with the replacement string provided. For example, with the command, pat = re.compile(‘Regex’) executed in the Python shell, the command pat.sub(‘Python’, ‘Regex is excellent’) will return the string, Python is excellent. The function escape( ) is used to escape all the characters in the given pattern, except alphanumeric characters in ASCII. The command print re.escape(‘a.b.c’) executed in the Python shell will return a\.b\.c. The function purge( ) clears the regular expression cache.
A few examples in Python
Now that most of the regular expression syntax has been presented to you, let us go through a few examples where Python regular expressions are called into action. What will be the string matched by the regular expression ^a\.z$ ? The caret symbol ^ makes sure that there should be an a at the beginning of the required pattern. The dollar symbol $ at the end ensures that the matched string should end with an z. The regular expression \. makes sure that there is a literal match for a dot (.) in between characters a and z. So only the lines containing the string a.z will be matched by this regular expression. Now, what does the regular expression a.z mean? Well, this matches any string with a sub-string containing an a followed by any character other than a new line character and then followed by an z. So, strings like a.z, aaz, abz, azz, etc, will be matched by this regular expression. What is the pattern matched by the regular expression ^(aa).*\(zz)$ ? This regular expression matches all the strings that start with the sub-string aa and end with the sub-string zz with zero or more characters in between them. So, strings like aazz, aaazzz, aabzz, etc, will be matched by this regular expression.
If you want to test a new regular expression pattern, you should follow these steps — open a terminal and type the command python to invoke the Python shell. Then, execute the command import re on the shell. Now, execute the command, pat = re.compile(‘###’), where you have to replace ### with the regular expression you want to test. Then execute the script run.py with the command execfile(‘run.py’) to view the results. This article has also discussed a number of ways to modify the script run.py. This script, its modified versions and all the text files used for testing in this article can be downloaded from opensourceforu.com/article_source_code/july17regex.zip.
This is just the beginning of our journey. The Python regular expressions discussed in this article are not comprehensive but they are more than sufficient for good data scientists to get on with their work. By the end of this series, you will have a good command over regular expressions. In the next article, we will discuss yet another programming language where regular expressions perform their miracles. But the best thing is that even if you are interested in just one programming language, say Python, the remaining articles in this series will still interest you because we will discuss a different set of regular expressions. So, with a little effort, you will be able to convert those regular expressions in other programming languages to Python regular expressions. The same applies to enthusiasts of other programming languages also.



{kind=link}
[…] and new ideas to make the utility more general-purpose. Just to share the project is written in Python and […]