






























































ETL jobs are very common, with IT organisations handling very large data sets. Executing an ETL workflow on OpenStack infrastructure with just a few clicks is a boon for private cloud operators, compared to setting up Hadoop infrastructure on physical hardware or elsewhere. This article targets IT admins and data analysts who wish to do their workload analysis with Hadoop/Spark on top of an OpenStack private cloud.
When thinking about a leading open source cloud computing platform, OpenStack comes to mind, as it controls large pools of compute, storage and networking resources throughout data centres, and has gained much popularity in the technology market. It introduces new services and features in every release cycle to address critical IT requirements. A very important requirement for any IT organisation is to build a robust platform for performing data analytics with large data sets. Big Data is the latest buzzword in the IT industry. This article focuses on how OpenStack plays a key role in addressing Big Data use cases.
Big Data on OpenStack
Nowadays, data is generated everywhere and its volume is growing exponentially. Data is generated from Web servers, application servers and database servers in the form of user information, log files and system state information. Apart from this, a huge volume of data is generated from IoT devices like sensors, vehicles and industrial devices. Data generated from the scientific simulation model is also an example of a Big Data source. It is difficult to store this data and perform analytics with traditional software tools. Hadoop, however, can address this issue.
Let me share my use case with you. I have a large volume of data stored in an RDBMS environment. It does not perform well when the data grows bigger. I cannot imagine its performance when it grows even bigger. I do not feel comfortable with adopting the NoSQL culture at this stage, but I need to store and process the bulk of my data in a cost-effective way. I also need to scale the cluster at any time and require a better dashboard to manage all of its components. Hence, I planned to set up a Hadoop cluster on top of OpenStack and create my ETL job environment.
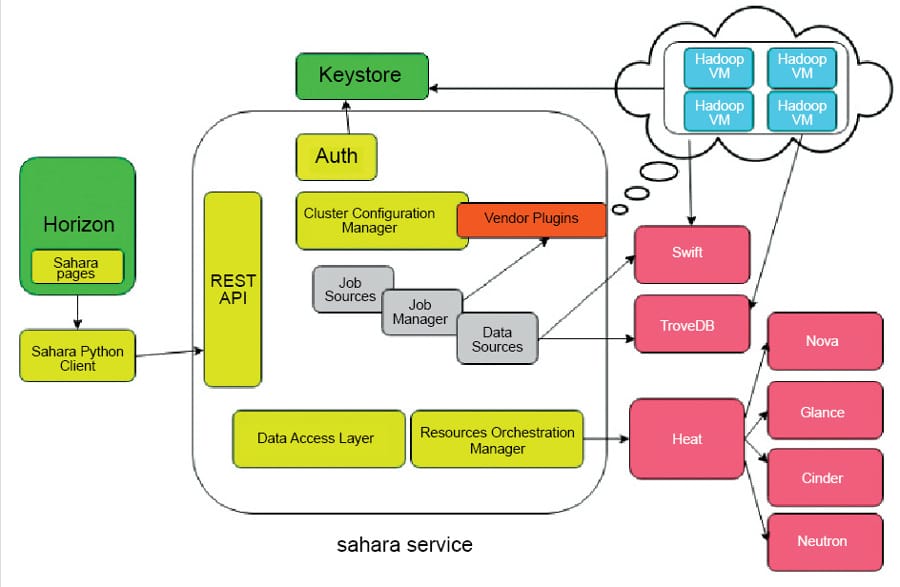
Hadoop is an industry standard framework for storing and analysing a large data set with its fault tolerant Hadoop Distributed File System and MapReduce implementation. Scalability is a very common problem in a typical Hadoop cluster. OpenStack has introduced a project called Sahara –Data Processing as a Service. OpenStack Sahara aims to provision and manage data processing frameworks such as Hadoop MapReduce, Spark and Storm in a cluster topology. This project is similar to the data analytics platform provided by the Amazon Elastic MapReduce (EMR) service. Sahara deploys the cluster in a few minutes. Besides, OpenStack Sahara can scale the cluster by adding or removing worker nodes, based on demand.
The benefits of managing a Hadoop cluster with OpenStack Sahara are:
- Clusters can be provisioned faster and are easy to configure.
- Like other OpenStack services, the Sahara service can be managed through its powerful REST API, CLI and horizon dashboard.
- Plugins are available to support multiple Hadoop vendors such as Vanilla (Apache Hadoop), HDP (Ambari), CDH (Cloudera), MapR, Spark and Storm.
- Cluster size can be scaled up and down, based on demand.
- Clusters can be integrated with OpenStack Swift to store the data processed by Hadoop and Spark.
- Cluster monitoring can be made simple.
Apart from cluster provisioning, Sahara can be used as ‘Analytics as a Service’ for ad hoc or bursty analytic workloads. Here, we can select the framework and load the job data. It behaves as a transient cluster and will be automatically terminated after job completion.

Architecture
OpenStack Sahara is designed to leverage the core services and other fully managed services of OpenStack. It makes Sahara more reliable and capable of managing the Hadoop cluster efficiently. We can optionally use services such as Trove and Swift in our deployment. Let us look into the internals of the Sahara service.
- The Sahara service has an API server which responds to HTTP requests from the end user and interacts with other OpenStack services to perform its functions.
- Keystone (Identity as a Service) authenticates users and provides security tokens that are used to work with OpenStack, limiting users’ abilities in Sahara to their OpenStack privileges.
- Heat (Orchestration as a Service) is used to provision and orchestrate the deployment of data processing clusters.
- Glance (Virtual Machine Image as a Service) stores VM images with operating system and pre-installed Hadoop/ Spark software packages to create a data processing cluster.
- Nova (Compute as a Service) provisions a virtual machine for data processing clusters.
- Ironic (Bare metal as a Service) provisions a bare metal node for data processing clusters.
- Neutron (Networking as a Service) facilitates networking services from basic to advanced topologies to access the data processing clusters.
- Cinder (Block Storage) provides a persistent storage media for cluster nodes.
- Swift (Object Storage) provides reliable storage to keep job binaries and the data processed by Hadoop/ Spark.
- Designate (DNS as a Service) provides a hosted zone to keep DNS records of the cluster instances. Hadoop services communicate with the cluster instances by their host names.
- Ceilometer (Telemetry as a Service) collects and stores the metrics about the cluster for metering and monitoring purposes.
- Manila (File Share as a Service) can be used to store job binaries and data created by the job.
- Barbican (Key Management Service) stores sensitive data such as password and private keys securely.
- Trove (Database as a Service) provides a database instance for the Hive metastore, and stores the states of the Hadoop services and other management services.
Setting up a Sahara cluster
The OpenStack team has provided clear documentation on how to set up Sahara services. Do follow the steps given in the installation guide to deploy Sahara in your environment. There are several ways in which the Sahara service can be deployed. To experiment with it, Kolla would be a good choice. You can also manage a Sahara project through the Horizon dashboard (https://docs.openstack.org/sahara/latest/install/index.html).
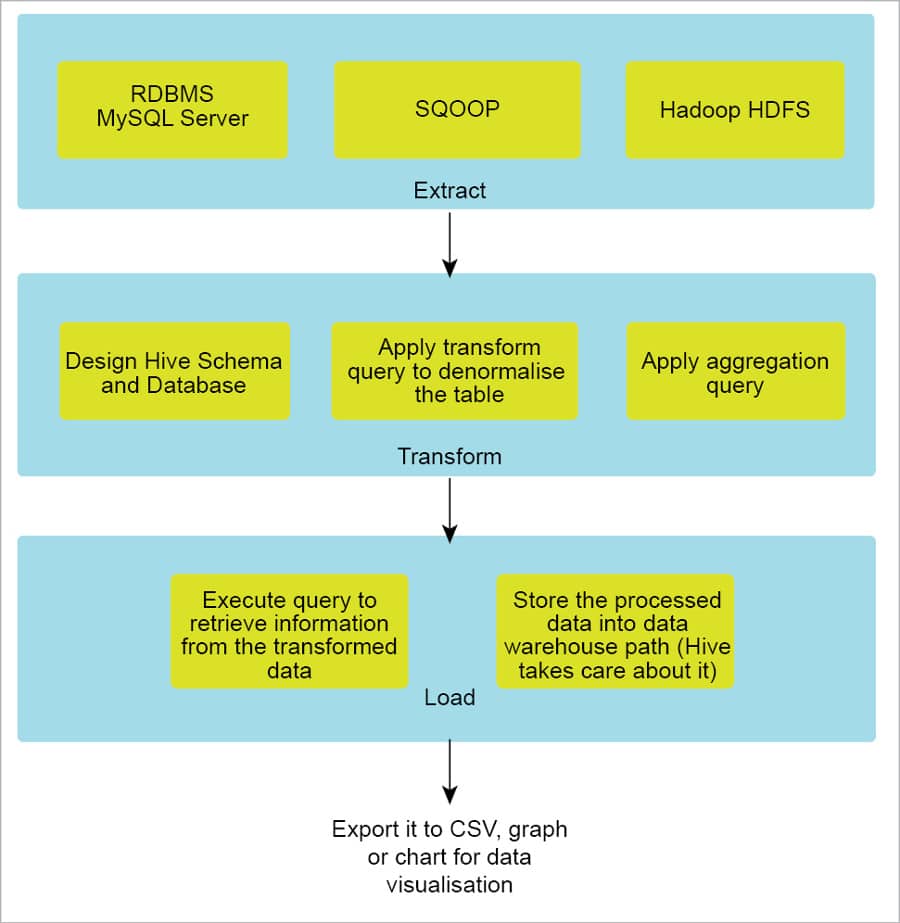
ETL (extract, transform and load) or ELT (extract, load and transform) with a Sahara cluster
There are numerous ETL tools available in the market and traditional data warehouses have their own benefits and limitations—they might be in some other location, rather than in your data source. The reason I am targeting Hadoop is that it is an ideal platform to run your ETL jobs. Data in your data store can come in various forms like structured, semi-structured and unstructured data. The Hadoop ecosystem has tools to ingest data from different data sources including databases, files and other data streams, and store it in a centralised Hadoop Distributed File System (HDFS). As the volume of data grows rapidly, Hadoop clusters can be scaled and you can leverage OpenStack Sahara.
Apache Hive is the data warehouse project built on top of the Hadoop ecosystem. It is a proven tool for ETL analysis. Once the data is extracted from the data sources with tools such as Sqoop, Flume, Kafka, etc, it should be cleansed and transformed by Hive or Pig scripts, using the MapReduce technique. Later we can load the data to the table we have created during the transformation phase and analyse it. This can be generated as a report and visualised with any BI tool.
Another advantage of Hive is that it is an interactive query engine and can be accessed via Hive Query Language, which resembles SQL. So a database operative can execute a job in the Hadoop ecosystem without prior knowledge of Java and MapReduce concepts. The Hive query execution engine parses the Hive query and converts it into a sequence of MapReduce/Spark jobs for a cluster. Hive can be accessed by the JDBC/ODBC driver and Thrift clients.
Oozie is a workflow engine available in the Hadoop ecosystem. A workflow is nothing but a set of tasks that needs to be executed as a sequence in a distributed environment. Oozie helps us to convert a simple workflow into cascading multiple workflows and creates coordinated jobs. However, it is ideal for creating workflows for complex ETL jobs. It does not have modules to support all actions related to Hadoop. A large organisation might have its own workflow engine to execute its tasks. We can use any workflow engine to carry out our ETL job. OpenStack Mistral (Workflow as a Service) is the best example. Apache Oozie resembles OpenStack Mistral in some aspects. It acts as a job scheduler and can be triggered at regular intervals of time.
Let us look at a typical ETL job process with Hadoop. An application stores its data in a MySQL server. The data stored in the DB server should be analysed within the shortest time and at minimum cost.
The extract phase
The very first step is to extract data from MySQL and store it in HDFS. Apache Sqoop can be used to export/import from a structured data source such as an RDBMS data store. If the data to be extracted is semi-structured or unstructured, we can use Apache Flume to ingest the data from a data source such as a Web server log, a Twitter data stream or sensor data.
sqoop import \ --connect jdbc:mysql://<database host>/<database name> \ --driver com.mysql.jdbc.Driver --table <table name> \ --username <database user> \ --password <database password> \ --num-mappers 3 \ --target-dir hdfs://Hadoop_sahara_local/user/rkkrishnaa/database
The transform phase
The data extracted from the above phase is not in a proper format. It is just raw data, and should be cleansed by applying a proper filter and data aggregation from multiple tables. This is our staging and intermediate area for storing data in HDFS.
Now, we should design a Hive schema for each table and create a database to transform the data stored in the staging area. Typically, the data is in CSV format and each record is delimited by a comma (,).
We don’t need to check HDFS data to know how it is stored. Since we have imported it from MySQL, we are aware of the schema. It is almost compatible with Hive except for some data types.
Once the database is modelled, we can load the extracted data for cleaning. Still, the data in the table is de-normalised. Aggregate the required columns from the different tables.
Open a Hive or Beeline shell, or if you have HUE (Hadoop User Experience) installed, do open the Hive editor and run the commands given below:
CREATE DATABASE <database name>; USE <database name>; CREATE TABLE <table name> ( variable1 DATATYPE , variable2 DATATYPE , variable3 DATATYPE , . , . , . , variable DATATYPE ) PARTITIONED BY (Year INT, Month INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ STORED AS TEXTFILE; LOAD DATA INPATH ‘hdfs://Hadoop_sahara_local/user/rkkrishnaa/database/files.csv’
Similarly, we can aggregate the data from the multiple tables with the ‘OVERWRITE INTO TABLE’ statement.
Hive supports partitioning tables to improve the query performance by distributing the execution load horizontally. We prefer to partition the columns that store the year and month. Sometimes, a partitioned table creates more tasks in a MapReduce job.
The load phase
We have checked the transform phase earlier. It is time to load the transformed data into a data warehouse directory in HDFS, which is the final state of the data. Here we can apply our SQL queries to get the appropriate results.
All DML commands can be used to analyse the warehouse data based on the use case (https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML).
Results can be downloaded as CSV, graphs or charts for analysis. They can be integrated with other popular BI tools such as Talend OpenStudio, Tabelau, etc.
What next?
We had a brief look at the benefits of OpenStack Sahara and explored a typical example of an ETL task in the Hadoop ecosystem. It is time to automate the ETL job with the Oozie workflow engine.
If you are experienced in using Mistral, you can stick with it. Most Hadoop users are acquainted with Apache Oozie, so I am using Oozie for this example.
Step 1: Create a job.properties file, as follows:
nameNode=hdfs://hadoop_sahara_local:8020
jobTracker=<rm-host>:8050
queueName=default
examplesRoot=examples
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}
oozie.libpath=/user/root
Step 2: Create a workflow.xml file to define the tasks for extracting data from the MySQL data store to HDFS, as follows:
<workflow-app xmlns=”uri:oozie:workflow:0.2” name=”my-etl-job”>
<global>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
</global>
<start to=”extract”/>
<action name=”extract”>
<sqoop xmlns=”uri:oozie:sqoop-action:0.2”>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<command>import --connect jdbc:mysql://<database host>:3306/<database name> --username <database user> --password <database password> --table <table name> --driver com.mysql.jdbc.Driver --target-dir hdfs://hadoop_sahara_local/user/rkkrishnaa/database${date} --m 3 </command>
</sqoop>
<ok to=”transform”/>
<error to=”fail”/>
<action name=”transform”>
<hive xmlns=”uri:oozie:hive-action:0.2”>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>oozie.hive.defaults</name>
<value>/user/rkkrishnaa/oozie/hive-site.xml</value>
</property>
</configuration>
<script>transform.q</script>
</hive>
<ok to=”load”/>
<error to=”fail”/>
<action name=”load”>
<hive xmlns=”uri:oozie:hive-action:0.2”>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>oozie.hive.defaults</name>
<value>/user/rkkrishnaa/oozie/hive-site.xml</value>
</property>
</configuration>
<script>load.q</script>
</hive>
<ok to=”end”/>
<error to=”fail”/>
</action>
<kill name=”fail”>
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name=”end”/>
</workflow-app>
Step 3: Create the file transform.q:
LOAD DATA INPATH ‘hdfs://hadoop_sahara_local/user/rkkrishnaa/database${date}/files.csv’
Step 4: Create the file load.q:
SELECT name, age, department from sales_department where experience > 5;
The above workflow job will do the ETL operation. We can customise the workflow job based on our own use case. There are a lot of mechanisms to handle task failure in our workflow job. Email action helps to track the status of the workflow task. This ETL job can be executed on a daily or weekly basis, at any time. Usually, organisations perform these long running tasks during weekends or at night.
To know more about workflow action, check out https://oozie.apache.org/docs/3.3.1/index.html.
OpenStack has integrated a very large Hadoop ecosystem to its universe. Many cloud providers offer the Hadoop service with just a few clicks on their cloud management portal. OpenStack Sahara proves the ability and robustness of OpenStack infrastructure. According to an OpenStack user survey, very few organisations have adopted the Sahara service in their private cloud. Sahara supports most of the Hadoop vendor plugins to operate the Hadoop workload effectively. So, go ahead and execute your ETL workflow with OpenStack Sahara.

















{kind=link}