






























































Due to the very heavy use of the Internet and social media, a huge amount of data is being generated every instance, all over the world. This data is useless unless it is collected, stored and analysed to derive useful conclusions that drive business and commerce. Tabula is a tool that extracts tabular data from PDF documents.
The Portable Document Format or PDF is used by most organisations today to create and disseminate information from online portals. Public information, notices, reports, etc, are released on online channels as PDF files so that the original formatting is retained.
Popular tools for the extraction of data from multiple sources
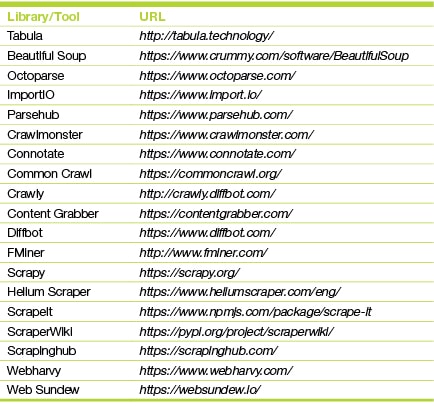
In data analytics, extraction, loading and transformation (ETL) are very important for the data set to be analysed effectively. Table 1 features the tools (and the related URLs) used by data scientists to fetch real-time data from Web portals and multiple sources.
Using Tabula to extract data from PDF files and reports
Tabula is a powerful tool used by data scientists and researchers to extract data from PDF files. Government reports, research papers and corporate documents are generally released and uploaded as PDF files. These may have the data in the form of tables. If these tables are directly copied and pasted to word processing applications like MS Word, the formatting gets changed and a lot of time is wasted in reformatting this data. But with Tabula, the tables in PDF files can be extracted easily without the formatting being tampered with.
 Tables that are extracted and loaded from PDF files using Tabula can be transformed into multiple formats including Comma Separate Values (CSV), JavaScript Object Notation (JSON), Tab Separated Values (TSV) and Script formats. These formats can be directly accessed and manipulated using multiple programming languages for data analytics and predictive knowledge discovery.
Tables that are extracted and loaded from PDF files using Tabula can be transformed into multiple formats including Comma Separate Values (CSV), JavaScript Object Notation (JSON), Tab Separated Values (TSV) and Script formats. These formats can be directly accessed and manipulated using multiple programming languages for data analytics and predictive knowledge discovery.
Tabula can be downloaded from https://github.com/tabulapdf/tabula/releases/download/v1.2.1/tabula-win-1.2.1.zip. It can be downloaded in the form of a compressed Zip folder, which is extracted. The directory structure and the files that are available in Tabula after extraction are shown in Figure 2.
After opening the Tabula directory, an .exe file is executed. On execution of tabula.exe, the Web based engine gets initiated. Once the Tabula engine is started, the Tabula application is opened on the Web browser with the URL http://127.0.0.1:8080.
On opening this URL on the Web browser, the Tabula application is loaded to extract the tabular data from the PDF files. The URL http://127.0.0.1:8080 can also be opened as URL http://localhost:8080 on the Web browser to extract, load and transform (ETL) the data from PDF files.
The PDF files from which the tabular data is to be extracted get imported in the Tabula dashboard on the Web browser (Figure 4).
After importing the PDF files to the Tabula application, the tabular data is automatically detected. On clicking ‘Preview & Export Extracted Data’, the tables are fetched from the PDF documents without any specific settings.
These tables can be transformed to CSV, TSV or JSON file formats so that the extracted data can be used for data analytics or plotting.

Tabula can be used by research scholars and data scientists to fetch selected tables from research papers and government reports for use in multiple applications. Research papers and analytics reports are generally prepared as PDF files and are available on various portals for users. With the help of
Tabula, data sets from the PDF files can be extracted and converted to the CSV or Excel formats so that the data mining or machine learning algorithms can be directly implemented. Also, once the data is extracted to the CSV format, it can be plotted for multiple applications.
















