



























































This article introduces YugaByteDB, an open source, cloud native relational DB for powering global, Internet scale apps. YugaByteDB has the features of both SQL as well as NoSQL databases, giving rise to a hybrid database system that is cloud native.
First generation database systems are SQL based (DBMS, RDBMS) and are suitable for relational data models. The second generation database systems are NoSQL (Not only SQL) based (MongoDB, Hadoop), and are suitable for semi-structured or unstructured data models. There are many situations in which first generation database systems miss some of the functionalities of second generation DB systems and vice versa. To address this gap, the current trend is towards third generation NewSQL database systems.
NewSQL DB systems have most of the features of SQL as well as NoSQL, and work as hybrid database systems. A trending NewSQL DB system is YugaByteDB, an open source distributed database that is cloud native and suitable for highly scalable data access with geo-distributed access.
In general, SQL is more convenient for fast writes to databases and NoSQL is for fast reads from a database, whereas NewSQL DBs like YugaByteDB are suitable for both fast read and write since they are cloud native solutions. It is most convenient to use them for large enterprise solutions such as data lakes, batch processing and live visualisation reports from massive data processing.
YugaByteDB is not only distributed and cloud native but also ensures high performance, Internet-scale and geo-distributed service. The architecture and core layers make it cloud-agnostic and available for on-premise deployments (hybrid cloud). It fully supports distributed and container deployments. YugaByteDB is designed for extensibility with the objective of re-using PostgreSQL’s query layer code in its internal layering architecture.
It supports distributed transactions for large scale processing. YugaByteDB is a consistent and partition tolerant (CP tolerant) database and hence achieves very high availability. Its architectural design is very similar to that of Google Cloud Spanner, which is also a CP system, by design. The design of YugaByteDB ensures that the complete database cluster (irrespective of the single or multiple nodes in its deployment instance) makes it available to applications as a single logical SQL database like any other common RDBMS. Hence, it comes with the flexibility of PostgreSQL and the easy-to-understand ACID (atomicity, consistency, isolation and durability) transaction semantics for applications that make it easy to use.
Starting off with YugaByteDB
YugaByteDB is available as a local installation (to install in Windows, Linux, etc, as a standalone DB). The Yugabyte platform, as a multi-node clustered installation, is suitable for the private or public cloud (SaaS) in AWS, Azure, GCP or other pivotal cloud service provider environments and also as Yugabyte Cloud, a PaaS platform, as a containerised solution (Dockerized).
YugaByteDB has an API interfacing service to run SQL commands through YSQL (Yugabyte SQL) and can use standard ANSI commands as used in PostgreSQL. This is because YugaByteDB is based on a Postgre query layer as a client interface.
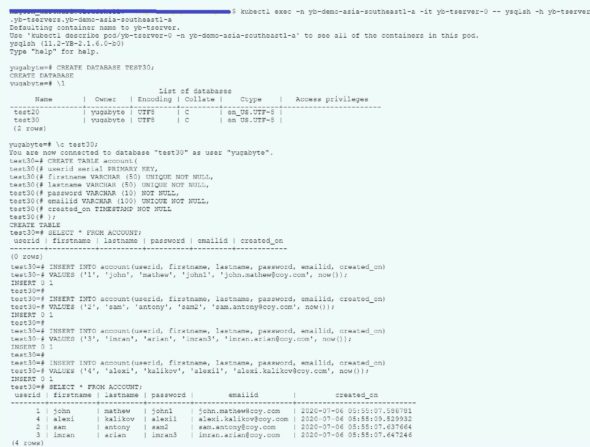
Figure 1 shows how to connect to a single-node YugaByteDB instance and run YSQL commands to create a database and table, and also to insert records to the table.
An application built for a PostgreSQL database with the best one-node performance can scale out without changing the application when moving to YugaByteDB, and vice versa.
An overview of YSQL
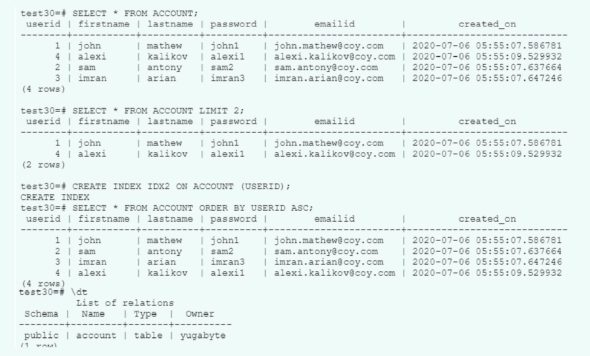
YugaByteDB is an open source database and it can run anywhere — on multi-cloud environments, the hybrid cloud and also in a containerised Kubernetes environment. At the same time, it can remain fully compatible with PostgreSQL by using a client interface called YSQL, which is a distributed SQL API and is compatible with PostgreSQL. Figure 2 shows standard DDL (data definition), DQL (data query) and DML (data manipulation) operations done using YSQL commands in a Yugabyte database.
We can use YCQL, which is a semi-relational API built for high performance and massive scale (similar to Hbase for the NoSQL Hadoop interface), with its roots in Cassandra Query Language (CQL). This makes YugaByteDB suitable for distributed and NoSQL capabilities. YSQL provides all the following standard facilities of a transaction database system:
- Transaction isolation
- Explicit row locks during critical operations
- Single-row transactions in business processing
- Distributed transactions in batch processing
- Transaction IO path details in enrichment
- Sharding facilities, in which a larger distributed database is logically partitioned into smaller data shards, making it easier to manage the database and faster to query during transaction processing
YSQL also provides tablet splitting, co-located tables in distributed instances, the default replication mechanism to enable high availability or real-time data across nodes, cluster replication to enable data safety, read replicas for higher performance across nodes, persistence in transaction handling, as well as higher performance in both relational and distributed data handling.
YugaByteDB Cloud instance
The YugaByteDB Cloud instance can be easily created with the pre-defined templates available in Terraform and AWS Cloud formation scripts, as given below.
The following GNU command in Windows or Linux environments downloads the AWS CloudFormation template:
wget https://raw.githubusercontent.com/yugabyte/aws-cloudformation/master/yugabyte_cloudformation.yaml
After downloading the above YAML script, you can run the command given below in the AWS CLI (console interface) to create the YugaByteDB instance in the AWS Cloud subscription:
aws cloudformation create-stack --stack-name <stack-name> --template-body file://yugabyte_cloudformation.yaml --parameters ParameterKey=DBVersion, ParameterValue=2.1.8.2,ParameterKey=KeyName,ParameterValue=<ssh-key-name>
Layering the architecture of YugaByteDB
Since YugaByteDB is a NewSQL type of database providing RDBMS and NoSQL DB functionalities, it has two layers — one for each of these services — called the query layer and the Document Store (DocDB) layer, as shown in Figure 3.
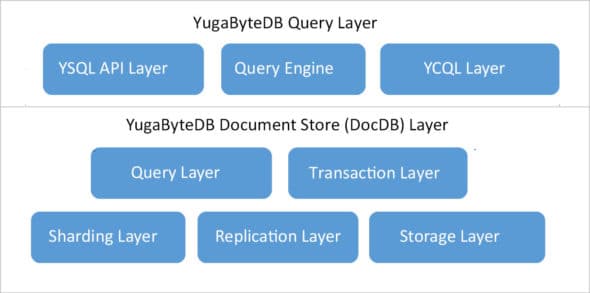
Each layer is lightweight and flexible enough to adopt to API calls and service requests to handle transaction processing in the database.
DocDB interface
DocDB or the Document Store layer is the distributed document store for facilitating strong Database write consistency in transaction processing (a resilient feature for highly resistant DB operations), automatic sharding to improve query performance (partitions the DB on its own), and flexible tuning to improve data read consistency and speed.
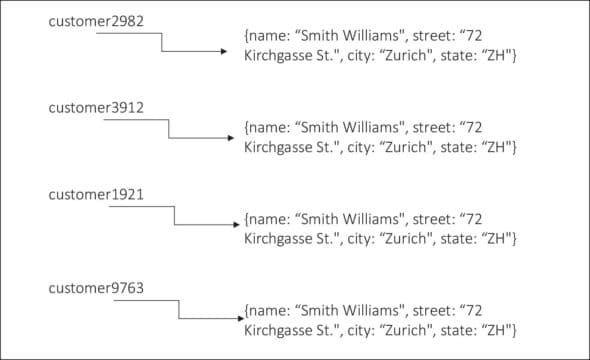
Data in DocDB is stored in a key-value pair in the table, where the table consists of rows of data, each row comprising a key to identify the data and a document paired to it as a JSON or XML element (Figure 4).
YugaByteDB offers high performance with a rate of about 1 million read/writes per second consistently while processing large volumes of data, as per benchmarking reports, and hence it is very helpful in adapting to cloud migration based solutions including the hybrid cloud and multi-cloud solutions. Since it provides containerised solutions with Docker and Kubernetes, it is more suitable for geo-distributed and high performance solutions for refactoring on-premise DBs to the cloud. In addition, it provides PostgreSQL capabilities and hence is suitable for licence optimisation in cloud adoption by migrating Oracle or MSSQL DBs to cloud based YugaByteDB. As per YugaByteDB documentation, it has partnered with Blitzz, which provides a quick tool to migrate DBs like Oracle, MongoDB, MySQL, DynamoDB and Cassandra to YugaByteDB with zero downtime. Blitzz supports YSQL and YCQL APIs to migrate to YugaByteDB.
You can start with YugaByteDB from its documentation page at
https://docs.yugabyte.com/















{kind=link}