






























































One of the recent applications of neural networks has been in the field of art and music. Are artificial neural networks capable of creativity? Well, they are, although not on par with the human faculty. What are the challenges of creating music and art through algorithms? What are the various approaches? These are some of the questions that are addressed in this article.
Over decades, artificial neural networks (ANNs) have come a long way from single layer perceptrons that solved simple classification problems to highly complex networks for deep learning. Today, neural networks are used for more than just classification or optimisation problems in various fields of application. One of the most recent applications of artificial neural networks is in the field of art and music. The goal here is to simulate human creativity and serve as an assisting tool for artists in their creations.
Early works
One of the first works of using ANNs for music composition was carried out as early as 1988 by Lewis and Todd. Lewis used a multi-layer perceptron, while Todd experimented with a Jordon autoregressive neural network (AR-NN) to generate music sequentially. The music composed with AR-NNs algorithmically had global coherence and structure issues. To circumvent that, Eck and Scmidhuber used long short-term memory (LSTM) neural networks to capture the temporal dependencies in a composition. In 2009, when deep learning networks were becoming more interesting for research, Lee and Andrew Ng started using deep convoluted neural networks (CNN) for music genre classification. This formed a basis for advanced models that used high-level (semantic) concepts from music spectrograms. Most recently, Wavenet models and generative adversarial networks (GAN) have been used for generating music. Waveform-based models outperformed spectrogram-based ones, provided that enough training material was available.
LSTM, CNN and GAN
We shall now discuss the various ANN models that are used to create music and art.
LSTM networks are a variant of recurrent neural networks (RNN) that are capable of learning long term dependencies. The key to LSTMs is the cell state, which stores information. The ability to add to or remove information from the cell state is regulated by gates that are a sigmoid neural network layer coupled with a pointwise multiplication operation. Since music sequences are time series with long term dependencies, it is appropriate to use LSTMs.
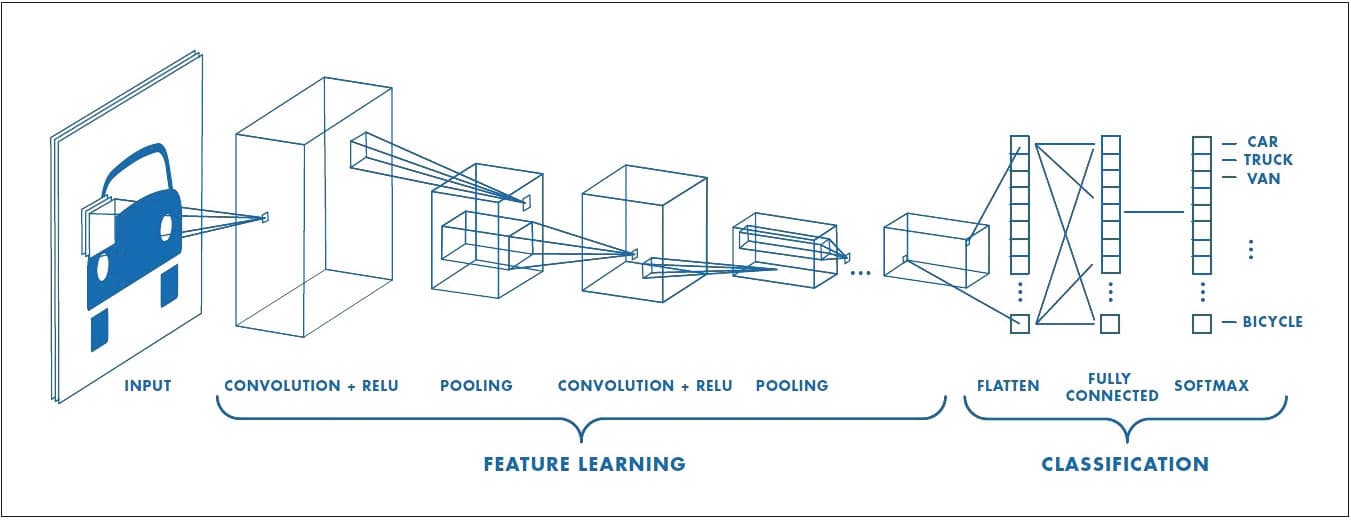
CNN or convoluted neural networks are designed to process input images. Their architecture is composed of two main blocks. The first block functions as a feature extractor, which matches templates by applying convolution filtering operations. It returns feature maps that are normalised and/or resized. The second block constitutes the classification layer. The network constitutes an input layer, hidden layers and output layer. In CNNs, the hidden layers perform convolutions. This typically includes a layer that does multiplication or dot product with the ReLU activation function, followed by other convolution layers like the pooling layers and normalisation layers. A typical CNN architecture is shown in Figure 1.
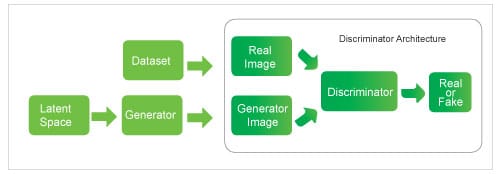
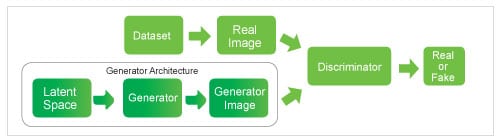
GAN or generative adversarial networks have a generator, discriminator and loss function. The role of the generator is to maximise the likelihood that the discriminator misclassifies its output as real. The discriminator’s role is to optimise towards 50 per cent where it cannot identify between real and generated images. The generator starts training alongside the discriminator. The latter trains a few epochs prior to starting the adversarial training, as it will be required to actually classify images. The loss function provides the stopping criteria for the generator and discriminator training processes. Figures 2-4 are pictorial block diagrams of the GAN architecture, the GAN generator and the GAN discriminator. GANs are better than LSTM in producing music because they are able to capture the large structural patterns in the latter.
Magenta: A Google Brain project
Magenta was an open source project developed by Google Brain in 2016, and is aimed at creating a new tool for artists when they work on developing new songs or artwork. Magenta is powered by Google’s TensorFlow machine learning platform, and can work with music and images. In the music domain, an agent automatically composes background music in real-time using the emotional state of the environment in which it is embedded. It chooses an appropriate composition algorithm dynamically from a database of previously chosen algorithms mapped to a given emotional state. Doug Eck and team worked with an LSTM model tuned with reinforcement learning. Reinforcement learning was used to teach the model to use certain rules while still allowing it to retain information learnt from data.
The LSTM model works on two metrics – the metrics we want to be low and the metrics we want to be high. The metrics associated with penalties are: a) notes not in key; b) mean autocorrelation – since the goal is to encourage variety, the model is penalised if the composition is highly correlated with itself; c) notes excessively related – LSTM is prone to repeat patterns. Reinforcement learning is brought in for creativity. The metrics associated with rewards are: a) compositions starting with a tonic note; b) leaps resolved – in order to avoid awkward intervals, leaps are taken in opposite directions, and leaping twice in the same direction is negatively rewarded; c) compositions (with unique maximum note and unique minimum note) in motif, which are a succession of notes representing a short musical idea. These metrics form a music theory rule. The degree of improvement of these metrics is determined by the reward given to a particular behaviour. The choice of metrics and the weights determine the shape of the music created. The most recent model of Magenta has used GAN and transformers to generate music with an improved long-term structure.
Challenges in music generation
The greatest challenge in the generation of music is to be able to encode various musical features. Once that is accomplished, the generative music is supposed to follow the broader structure, dynamics and rules of music. Musical dimensions such as timing and pitch have relative rather than absolute significance when it comes to how notes are placed in them. Features such as dynamics (that tells the volume of the sound from the instrument) and timbre (that differentiates between notes having the same pitch and loudness) are difficult to encode. There are other features such as duration, rest, timing and pitch that are also challenging to represent as extracted features.
Future trends
Various GAN models such as MidiNet, SSMGAN, C-RNN-GAN, JazzGAN, MuseGAN, Conditional LSTM GAN, etc, have been attempted for composing melody. Other generative models like the VAE, flow-based models, autoregressive models, transformers, RBMs, HMMs and many others have been used in research in this area. Melody generation is moving towards bringing in more musical diversity and structure handling capacity. Better interpretability and human control are being aimed for. Standardised test data sets and evaluation metrics, cross-modal generation, composition style transfer, lyrics-free singing and interactive music generation are some future research directions in this field.



















