






























































We generate humongous amounts of data these days, and therefore need specific techniques to store and handle it. Apache Druid is a powerful and modern analytics database that is really fast and allows users to conduct real-time data analyses. Designed specifically for processing real-time event-driven data, it is a strong platform that combines the capability of time-series databases, column-oriented analytics databases and search systems.
In today’s world, data is the lifeblood of any software product. Every time we engage with a digital system, we generate data. The amount of data available has grown to the point where specialist tools are required to make sense of it. Real-time analytics allows for the extraction of insights from large amounts of data. To undertake this type of analysis, we need custom-built tools that can store and process data in real time, allowing us to make real-time inferences.
Apache Druid is not simply a traditional data warehouse but is tailor-made to handle real-time analytics of event-driven data. Druid is used to power the graphical user interface (GUI) of analytics applications.
It serves as the backend for providing the data manipulation for powering highly concurrent queries. Druid can be thought of as a combination of three major things (Figure 1):
- Time series databases
- Column oriented databases
- Search systems
Druid has applications across various domains. Almost all domains generate massive scales of data and Druid can be effectively deployed to analyse these. Some of the applications of Druid are (Figure 2):
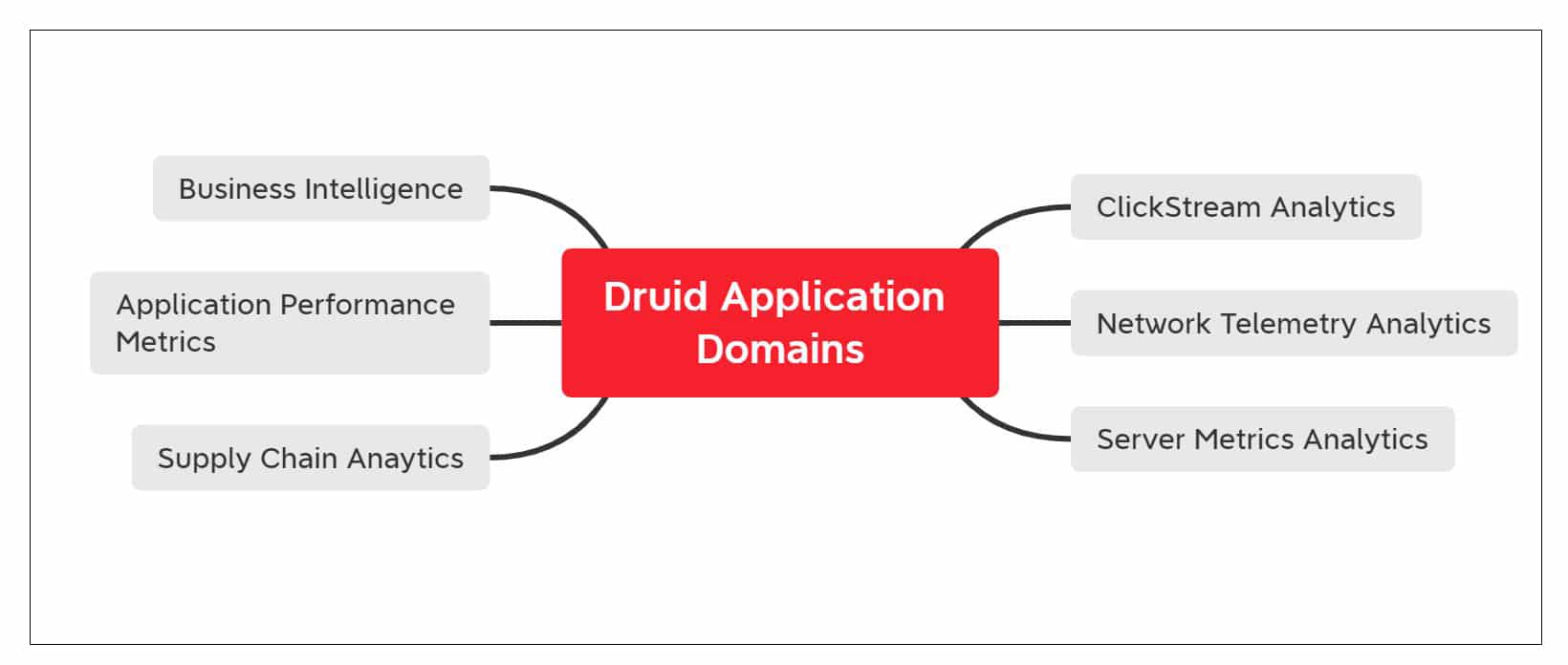
- Click stream, view stream and activity stream analytics can be carried out with Druid. User activity and behavioural analytics can be performed too
- Performance monitoring of networks with the help of network telemetry analytics
- Server metrics storage
- Supply chain analytics
- Analytics of digital marketing and advertising. Druid can be effectively implemented to query online advertising data. This can be used to infer the performance of advertising campaigns, conversion rates, etc
- IoT and device metrics
- Druid can be effectively used for business intelligence. With the ability to support high concurrency it becomes an ideal tool for interactive visual analytics.
The above is merely a sample list. Druid can be used in any scenario with identical criteria.
Key features of Druid
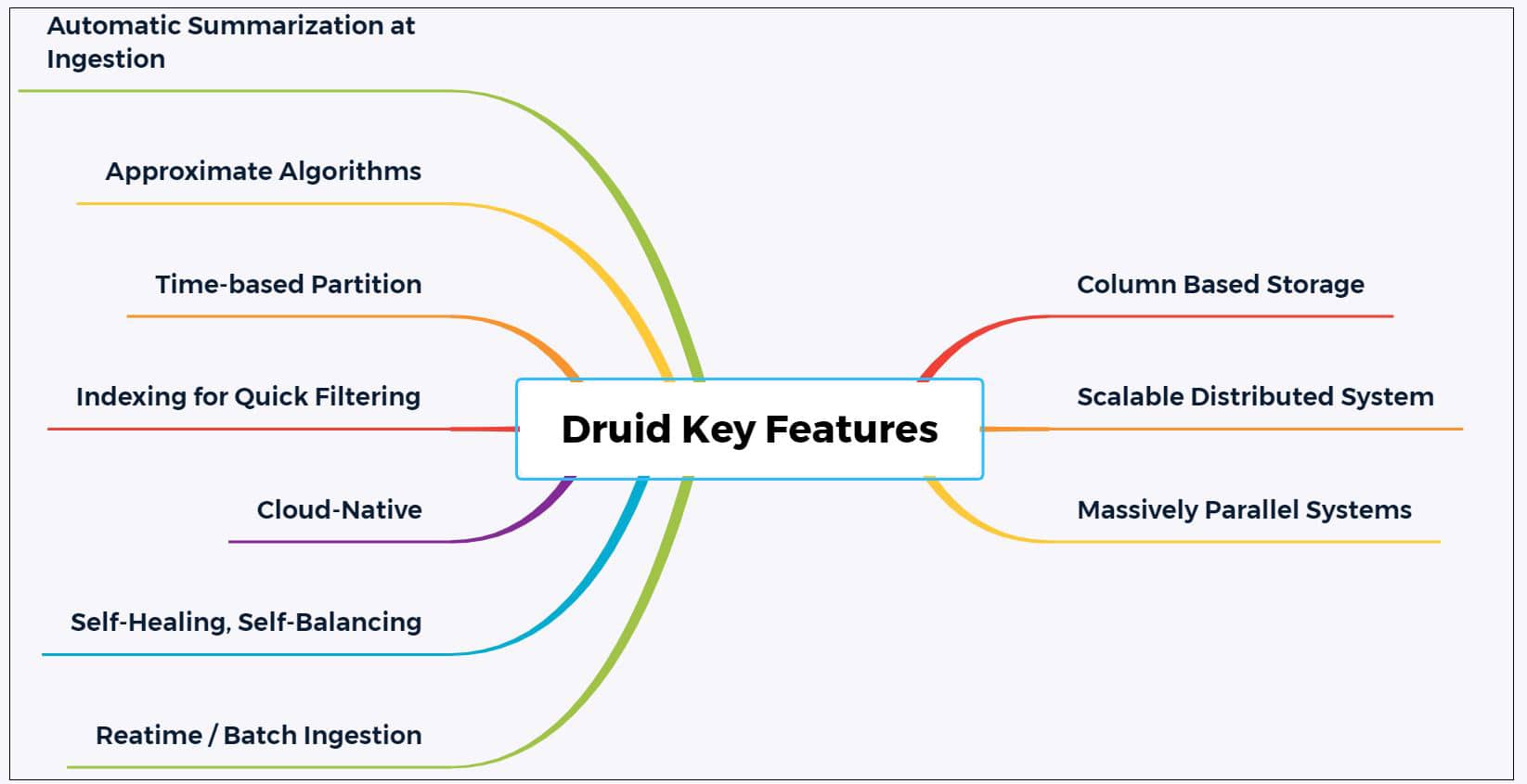
The inherent design of Druid makes it suitable for many scenarios where highly reliable, concurrent processing of massive real-time data is required. A few key features of Druid are listed below.
- Column based storage: Druid loads only those columns that are needed in the current scenario. The columns are also optimised for storage as per their data types. This enables quick scans and aggregation operations.
- Scalable distributed system: An important feature of Druid is its ability to be deployed in a distributed manner across tens or hundreds of servers.
- Massive parallel processing: Druid can process a given query in parallel mode across the entire cluster. This helps it to reduce the latency as much as possible.
Support for various types of data ingestion: Druid supports both real-time ingestion (explained later) and batch ingestion of data. In the case of real-time ingestion, the data becomes immediately available for querying. - Self-healing, self-balancing and easy to operate: Druid’s inherent design is such that if any of its servers fail then the request can be routed around to provide uninterrupted service 24×7. The official documentation states that Druid is designed to avoid planned downtimes for performing routines such as software updates and configuration enhancement.
- Cloud native and fault-tolerant: After the ingestion of data, it becomes fault-tolerant and fail-safe by storing a copy in deep storage. (This is usually HDFS, cloud storage or a shared file system.) The data stored in this deep storage can be utilised in case Druid servers fail. The replication of data storage makes the recovery of systems simple and effective.
- Indexing for quicker retrieval: Druid employs indexing mechanisms such as ‘roaring’. These enable powerful and quick filtering of data across multiple columns.
- Time based partitioning: Druid has the ability to partition data as per time first, and then based on fields. This enables efficient handling of time series data by accessing those specific partitions that match the temporal range of the current query.
- Approximate algorithms: Another important attribute of Druid is the inclusion of algorithms to perform approximate distinct count and approximate ranking, as well as to build approximate histograms and quantiles.
- Automatic summarisation during ingestion: Druid has the ability to perform data summarisation at ingestion time. Because of this, pre-aggregation is carried out to a certain extent. This plays a significant role in increasing the performance of Druid.
Powered by Druid
The power of Druid can be understood by looking at the long list of industry majors who use it. The complete list is available on the official website at https://druid.apache.org/druid-powered. Due to space constraints this article lists only a few of the major implementations.
- Alibaba: Druid is used for performing real-time analytics of users’ interactions on Alibaba’s e-commerce website.
- British Telecom: Druid was implemented at British Telecom after conducting a detailed comparison across various parameters such as ingestion, read performance, aggregation, high availability, etc. A detailed report on this is available at https://imply.io/videos/why-british-telecom-chose-druid-over-cassandra.
- Cisco: At Cisco, Druid powers the network flow data analytics in real time.
- Netflix: Druid is used to aggregate the many data streams at Netflix. A detailed article is available at https://netflixtechblog.com/how-netflix-uses-druid-for-real-time-insights-to-ensure-a-high-quality-experience-19e1e8568d06, which explains how Druid is being used by Netflix for providing real-time insights to enable a high-quality experience for its customers.
- PayPal: Druid has been adapted at PayPal to handle massive volumes of data. This is used for internal exploratory analytics.
- Walmart: Druid is employed at Walmart for event stream analytics. Further details are available at https://medium.com/walmartglobaltech/event-stream-analytics-at-walmart-with-druid-dcf1a37ceda7.
Ingestion
The term ingestion has been used a few times in this article. Before the actual installation of Druid, let’s understand what ingestion is and what its types are.
Druid organises data in the form of segments. Each of these segments is a data file. These files carry a few million rows. Loading of data in Druid is termed ingestion, and consists of the following:
- Reading data from the source system
- Building of segments based on this data
Ingestion can be carried out in two ways:
- Streaming ingestion
- Batch ingestion
Each of these ingestion systems has support for its own sources from which it pulls the data. Streaming ingestion is recommended and popular. It reads data directly from Kafka. The Kinesis indexing service is also used.
In the case of batch indexing, there are three options:
- index_parallel
- index_hadoop
- index
To understand Druid better, it is important to have an idea about its design and components. With a primarily multi-process and distributed architecture, Druid is cloud-friendly in its design.
Druid processes and servers
There are many types of processes as listed below.
- Coordinator: Manages data availability on the clusters
- Overlord: For controlling the assignment of data ingestion workloads
- Broker: This is for handling queries from external clients
- Router: Used to route requests to brokers, coordinators and overlords
- Historical: For storing the data that can be queried
- Middle manager: This is responsible for ingesting data There are three types of servers.
- Master: This is for running the coordinator and overlord processes. It also manages data availability and ingestion.
- Query: This runs broker and router processes (optional). It is used for handling queries from external clients.
- Data: This runs the historical and middle manager processes. It is used to execute ingestion workloads.
External dependencies
Druid has three external dependencies.
- Deep storage: This is a shared file storage which is accessible by each Druid server. This can be a distributed object store such as S3 or a network mounted file system.
- Metadata storage: This is used for storing various shared system metadata. This can include items such as segment usage information and task information.
- ZooKeeper: This is used for various activities such as internal service discovery, coordination and leader election.
The architecture diagram of Druid (from the official documentation) illustrates the components and their interaction (Figure 4).

Druid installation
Druid may be installed on a laptop for experimental purposes. It has various startup configurations. You should try the micro-quickstart configuration for evaluating Druid. The nano-quickstart configuration requires very few resources — one CPU and 4GB RAM.
The basic requirements for installing Druid on your computer are as follows:
- Operating systems like Linux and Mac OS X. Similar UNIX based OSes are also supported. The official documentation lists that Windows is not supported.
- Java 8 (update 92 or later).
If your system satisfies the above requirements, download version 0.21.1 from https://www.apache.org/dyn/closer.cgi?path=/druid/0.21.1/apache-druid-0.21.1-bin.tar.gz. Then extract it from the terminal and navigate to the directory:
tar -xzf apache-druid-0.21.1-bin.tar.gz cd apache-druid-0.21.1
Druid can be started with the micro-quickstart configuration using the following command:
./bin/start-micro-quickstart
This command launches instances of ZooKeeper and Druid services:
$ ./bin/start-micro-quickstart Running command[zk], logging to[/apache-druid-0.21.1/var/sv/zk.log]: bin/run-zk conf Running command[coordinator-overlord], logging to[/apache-druid-0.21.1/var/sv/coordinator-overlord.log]: bin/run-druid coordinator-overlord conf/druid/single-server/micro-quickstart Running command[broker], logging to[/apache-druid-0.21.1/var/sv/broker.log]: bin/run-druid broker conf/druid/single-server/micro-quickstart Running command[router], logging to[/apache-druid-0.21.1/var/sv/router.log]: bin/run-druid router conf/druid/single-server/micro-quickstart Running command[historical], logging to[/apache-druid-0.21.1/var/sv/historical.log]: bin/run-druid historical conf/druid/single-server/micro-quickstart Running command[middleManager], logging to[/apache-druid-0.21.1/var/sv/middleManager.log]: bin/run-druid middleManager conf/druid/single-server/micro-quickstart
Once the services are started, the Druid console can be opened by navigating to http://localhost:8888. You will find the output as shown in Figure 5.

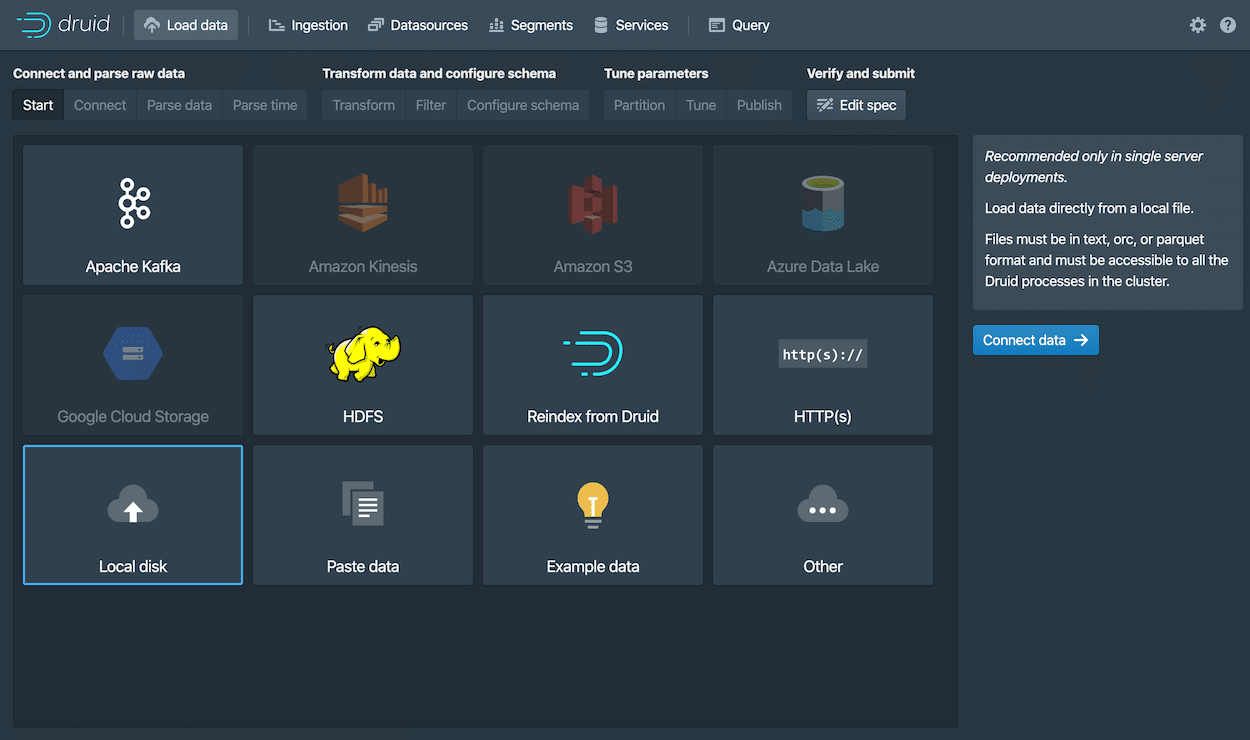
Then data can be loaded from the Load Data -> Local Disk option, as shown in Figure 6. The example data from the tutorial folder can be chosen.
The following steps can be carried out:
- Data can be parsed based on the input format.
- Time based parsing can be carried out.
- Transform, filter and configuration can be explored.
- The rollup options can be either turned on or off.
- Partition can be carried out by selecting the segment granularity.
- Tune and publish can be carried out.
- The spec can be edited if required. Finally, the data can be submitted.
Each step is explained with an illustrative screenshot in the official documentation at https://druid.apache.org/docs/latest/tutorials/index.html.
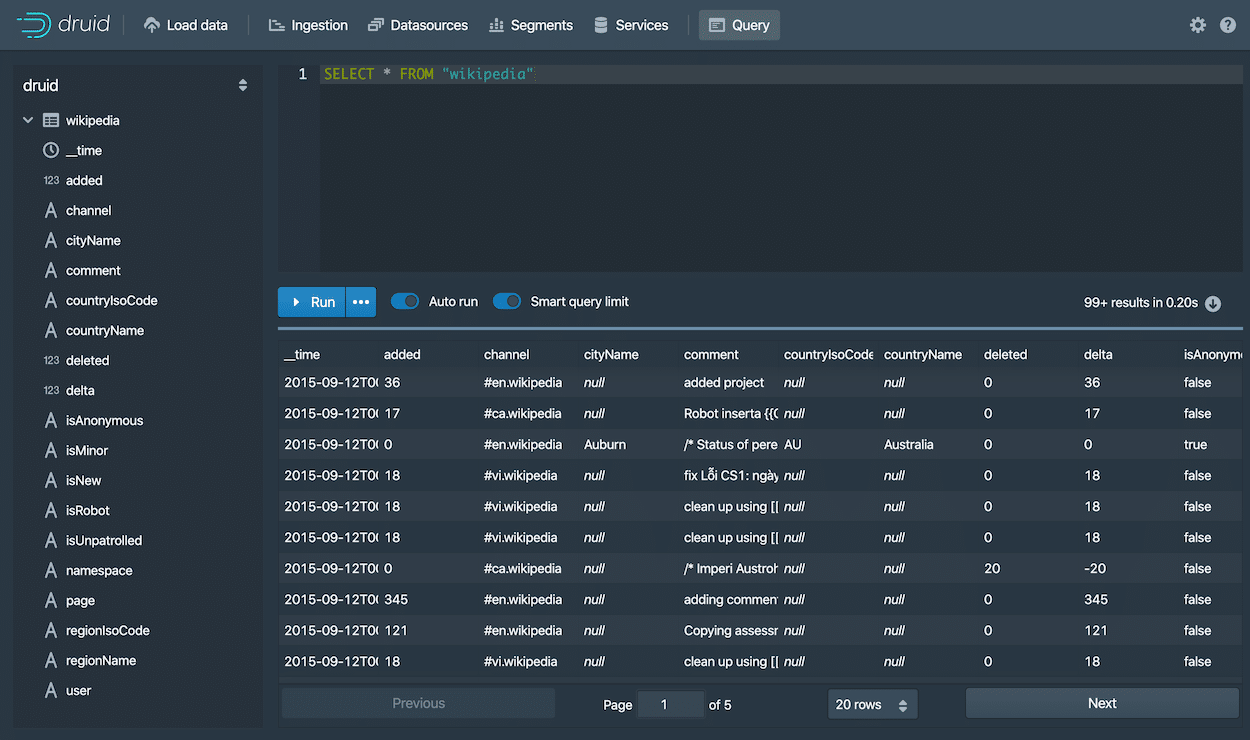
Querying of the data can be carried out with the following steps:
- Select the DataSources tab.
- You can select a particular source and choose Query with SQL.
- Next, type this simple query to view the results:
SELECT * FROM “Wikipedia”
If you are working on a project that involves time series data and a large number of events, Druid is a great way to improve the performance of your app.

















{kind=link}