






























































Apache Kafka is one of the most popular open source message brokers. Found in almost all microservices environments, it has become an important component of Big Data manipulation. This article gives a brief description of Apache Kafka, followed by a case study that demonstrates how it is used.
Have you ever wondered how e-commerce platforms are able to handle immense traffic without getting stuck? Ever thought about how OTT platforms are able to deliver content to millions of users, smoothly and simultaneously? The key lies in their distributed architecture.
A system designed around distributed architecture is made up of multiple functional components. These components are usually spread across several machines, which collaborate with each other by exchanging messages asynchronously over a network. Asynchronous messaging is what enables scalable, non-blocking communication among components, thereby allowing smooth functioning of the overall system.
Asynchronous messaging
The common features of asynchronous messaging are:
- The producers and consumers of the messages are not aware of each other. They join and leave the system without the knowledge of the others.
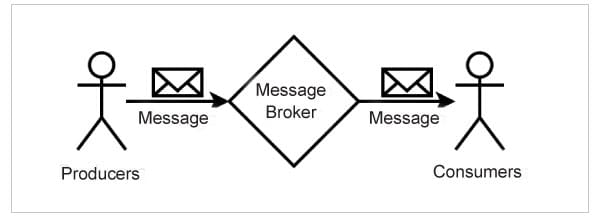
- A message broker acts as the intermediary between the producers and consumers.
- The producers associate each of the messages with a type, known as topic. A topic is just a simple string.
- It is possible that producers send messages on multiple topics, and multiple producers send messages on the same topic.
- The consumers register with the broker for messages on one or more topics.
- The producers send the messages only to the broker, and not to the consumers.
- The broker, in turn, delivers the messages to all the consumers that are registered against the topic.
- The producers do not expect any response from the consumers. In other words, the producers and consumers do not block each other.
There are several message brokers available in the market, and Apache Kafka is one of the most popular among them.
Apache Kafka
Apache Kafka is an open source distributed messaging system with streaming capabilities, developed by the Apache Software Foundation. Architecturally, it is a cluster of several brokers that are coordinated by the Apache Zookeeper service. These brokers share the load on the cluster while receiving, persisting, and delivering the messages.
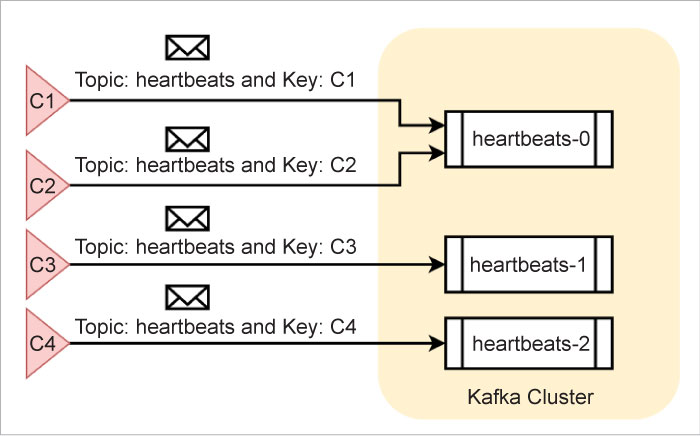
Partitions: Kafka writes messages into buckets known as partitions. A given partition holds messages only on one topic. For example, Kafka writes messages on the topic heartbeats into the partition named heartbeats-0, irrespective of the producer of the messages.
However, in order to leverage the cluster-wide parallel processing capabilities of Kafka, administrators often create more than one partition for a given topic. For instance, if the administrator creates three partitions for the topic heartbeats, Kafka names them as heartbeats-0, heartbeats-1, and heartbeats-2. Kafka writes the heartbeat messages across all the three partitions in such a way that the load is evenly distributed.
There is yet another possible scenario in which the producers associate each of the messages with a key. For example, a component uses C1 as the key while another component uses C2 as the key for the messages that they produce on the topic heartbeats. In this scenario, Kafka makes sure that the messages on a topic with a specific key are always found only in one partition. However, it is quite possible that a given partition may hold messages with different keys. Figure 2 presents a possible message distribution among the partitions.
Leaders and ISRs: Kafka maintains several partitions across the cluster. The broker on which a partition is maintained is called the leader for the specific partition. Only the leader receives and serves the messages from its partitions.
But what happens to a partition if its leader crashes? To ensure business continuity, every leader replicates its partitions on other brokers. The latter act as the in-sync-replicas (ISRs) for the partition. In case the leader of a partition crashes, Zookeeper conducts an election and names an ISR as the new leader. Thereafter, the new leader takes the responsibility of writing and serving the messages for that partition. Administrators can choose how many ISRs are to be maintained for a topic.

Message persistence: The brokers map each of the partitions to a specific file on the disk, for persistence. By default, they keep the messages for a week on the disk! The messages and their order cannot be altered once they are written to a partition. Administrators can configure policies like message retention, compaction, etc.
Consuming the messages: Unlike most other messaging systems, Apache Kafka does not actively deliver the messages to its consumers. Instead, it is the responsibility of the consumers to listen to the topics and read the messages. A consumer can read messages from more than one partition of a topic. And it is also possible that multiple consumers read messages from a given partition. Kafka guarantees that no message is read more than once by a given consumer.
Kafka also expects that every consumer is identified with a group ID. Consumers with the same group ID form a group. Typically, in order to read messages from N number of topic partitions, an administrator creates a group with N number of consumers. This way, each consumer of the group reads messages from its designated partition. If the group consists of more consumers than the available partitions, the excess consumers remain idle.
In any case, Apache Kafka guarantees that a message is read only once at the group level, irrespective of the number of consumers in the group. This architecture gives consistency, high-performance, high scalability, near-real-time delivery, and message persistence along with zero-message loss.
Installing and running Kafka
Although, in theory, the Apache Kafka cluster can consist of any number of brokers, most of the clusters in production environments usually consist of three or five of these.
Here, we will set up a single-broker cluster that is good enough for the development environment.
Download the latest version of Kafka from https://kafka.apache.org/downloads using a browser. It can also be downloaded with the following command, on a Linux terminal:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/2.8.0/kafka_2.12-2.8.0.tgz
We can move the downloaded archive file kafka_2.12-2.8.0.tgz to some other folder, if needed. Extracting the archive creates a folder by the name kafka_2.12-2.8.0, which will be referred to as KAFKA_HOME hereafter.
Open the file server.properties under the KAFKA_HOME/config folder and uncomment the line with the following entry:
listeners=PLAINTEXT://:9092
This configuration enables Apache Kafka to receive plain text messages on port 9092, on the local machine. Kafka can also be configured to receive messages over a secure channel as well, which is recommended in the production environments.
Irrespective of the number of brokers, Apache Zookeeper is required for broker management and coordination. This is true even in the case of single-broker clusters. Since Zookeeper is already bundled with Kafka, we can start it with the following command from KAFKA_HOME, on a terminal:
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
Once Zookeeper starts running, Kafka can be started in another terminal, with the following command:
./bin/kafka-server-start.sh ./config/server.properties
With this, a single-broker Kafka cluster is up and running.
Verifying Kafka
Let us publish and receive messages on the topic topic-1. A topic can be created with a chosen number of partitions with the following command:
./bin/kafka-topics.sh --create --topic topic-1 --zookeeper localhost:2181 --partitions 3 --replication-factor 1
The above command also specifies the replication factor, which should be less than or equal to the number of brokers in the cluster. Since we are working on a single-broker cluster, the replication factor is set to one.
Once the topic is created, producers and consumers can exchange messages on that topic. The Kafka distribution includes a producer and a consumer for test purposes. Both of these are command-line tools.
To invoke the producer, open the third terminal and run the following command:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-1
This command displays a prompt at which we can key in simple text messages. Because of the given options on the command, the producer sends the messages on topic-1 to the Kafka that is running on port 9092 on the local machine.
Open the fourth terminal and run the following command to start the consumer tool:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-1 –from-beginning
This command starts the consumer that connects to the Kafka on port number 9092 on the local machine. It registers for reading the messages on topic-1. Because of the last option on the command line, the consumer receives all the messages on the chosen topic from the beginning.
Since the producer and consumer are connecting to the same broker and referring the same topic, the consumer receives and displays the messages on its terminal.
Now, let’s use Kafka in the context of a practical application.
Case study
ABC is a hypothetical bus transport company, which has a fleet of passenger buses that ply between different cities across the country. Since ABC wants to track each bus in real-time for improving the quality of its operations, it comes up with a solution around Apache Kafka.
ABC first equips all its buses with devices to track their location. An operations centre is set up with Apache Kafka, to receive the location updates from each of the hundreds of buses. A dashboard is developed to display the current status of all the buses at any point in time. Figure 5 represents this architecture.
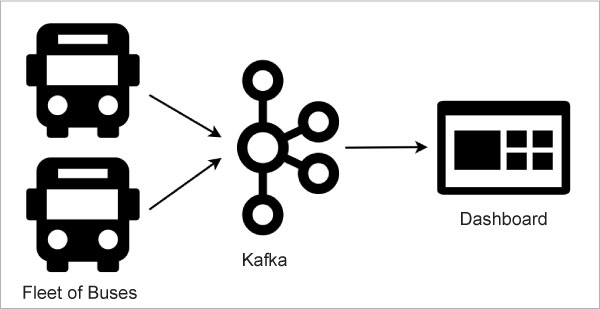
In this architecture, the devices on the buses act as the message producers. They send their current location to Kafka on the topic abc-bus-location, periodically. For processing the messages from different buses, ABC chooses to use the trip code as the key. For example, if the bus from Bengaluru to Hubballi runs with the trip code BLRHBL003, then BLRHBL003 becomes the key for all the messages from that specific bus during that specific trip.
The dashboard application acts as the message consumer. It registers with the broker against the same topic abc-bus-location. Consequently, the topic becomes the virtual channel between the producers (buses) and the consumer (dashboard).
The devices on the buses never expect any response from the dashboard application. In fact, none of them is even aware of the presence of the others. This architecture enables non-blocking communication between hundreds of buses and the central office.
Implementation
Let’s assume that ABC wants to create three partitions for maintaining the location updates. Since the development environment has only one broker, the replication factor should be set to one.
The following command creates the topic accordingly:
./bin/kafka-topics.sh --create --topic abc-bus-location --zookeeper localhost:2181 --partitions 3 --replication-factor 1
The producer and consumer applications can be written in multiple languages like Java, Scala, Python, JavaScript, and a host of others. The code in the following sections provides a peek into the way they are written in Java.
Java producer: The Fleet class simulates the Kafka producer applications running on six buses of ABC. It sends location updates on abc-bus-location to the specified broker. Please note that the topic name, message keys, message body, and broker address are hard-coded only for simplicity.
public class Fleet {
public static void main(String[] args) throws Exception {
String broker = “localhost:9092”;
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
String topic = “abc-bus-location”;
Map<String, String> locations = new HashMap<>();
locations.put(“BLRHBL001”, “13.071362, 77.461906”);
locations.put(“BLRHBL002”, “14.399654, 76.045834”);
locations.put(“BLRHBL003”, “15.183959, 75.137622”);
locations.put(“BLRHBL004”, “13.659576, 76.944675”);
locations.put(“BLRHBL005”, “12.981337, 77.596181”);
locations.put(“BLRHBL006”, “13.024843, 77.546983”);
IntStream.range(0, 10).forEach(i -> {
for (String trip : locations.keySet()) {
ProducerRecord<String, String> record
= new ProducerRecord<String, String>(
topic, trip, locations.get(trip));
producer.send(record);
}
});
producer.flush();
producer.close();
}
}
Java consumer: The Dashboard class implements the Kafka consumer application and it runs at the ABC Operations Centre. It listens to abc-bus-location with the group ID abc-dashboard and displays the location details from different buses as soon as messages are available. Here, too, many details are hard coded which are otherwise supposed to be configured:
public static void main(String[] args) {
String broker = “127.0.0.1:9092”;
String groupId = “abc-dashboard”;
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
@SuppressWarnings(“resource”)
Consumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(“abc-bus-location”));
while (true) {
ConsumerRecords<String, String> records
= consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
String topic = record.topic();
int partition = record.partition();
String key = record.key();
String value = record.value();
System.out.println(String.format(
“Topic=%s, Partition=%d, Key=%s, Value=%s”,
topic, partition, key, value));
}
}
}
}
Dependencies: A JDK of 8+ version is required to compile and run this code. The following Maven dependencies in the pom.xml download and add the required Kafka client libraries to the classpath:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.8.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.7.25</version> </dependency>
Deployment
As the topic abc-bus-location is created with three partitions, it makes sense to run three consumers to read the location updates quickly. For that, run the Dashboard in three different terminals simultaneously. Since all the three instances of Dashboard register with the same group ID, they form a group. Kafka attaches each Dashboard instance with a specific partition.
Once the Dashboard instances are up and running, start the Fleet on a different terminal. Figure 6, Figure 7, and Figure 8 are sample console messages on the Dashboard terminals.
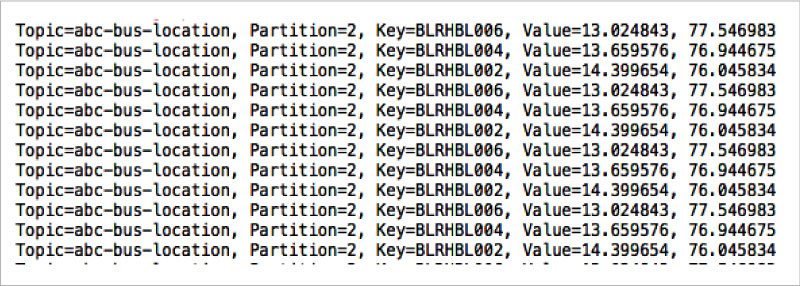
A closer look at the console messages reveals that the consumers on the first, second and third terminals are reading messages from partition-2, partition-1, and partition-0, in that order. Also, it can be observed that the messages with the keys BLRHBL002, BLRHBL004 and BLRHBL006 are written into partition-2, the messages with the key BLRHBL005 are written into partition-1, and the remaining are written into partition-0.

The good thing about Kafka is that it can be scaled horizontally to support a large number of buses and millions of messages as long as the cluster is designed appropriately.

Beyond messaging
More than 80 per cent of the Fortune 100 companies are using Kafka, according to its website. It is deployed across many industry verticals like financial services, entertainment, etc. Though Apache Kafka started its journey as a simple messaging service, it has propelled itself into the Big Data ecosystem with industry-level stream processing capabilities. For the enterprises that prefer a managed solution, Confluent offers a cloud based Apache Kafka service for a subscription fee.




















{kind=link}