





























































Deep learning is a subset of artificial intelligence that uses artificial neural networks to model and imitate the functioning of the human brain. This article takes a look at how to work with pre-trained deep learning models for natural language processing (NLP).
Deep learning powers numerous artificial intelligence apps and services that automate analytical and physical processes. It is currently used in a very wide range of applications in the government, corporate and social sectors.
A few key applications of deep learning in real-world domains are:
- Real-time computer vision and image analytics
- Virtual assistants
- Automated manufacturing
- Speech recognition (vocal artificial intelligence)
- Data science and engineering
- Entertainment and musical notations
- Stock trading and financial data analytics
- Shopping patterns analysis in e-commerce
- Sentiment analysis on social media
- Customer relationship management systems
- Advertising and promotional activities
- Autonomous vehicles, self-driving cars and drones
- Natural language processing (NLP)
- Fraud detection and cyber security
- Emotional intelligence
- Healthcare and medical diagnosis
- Investment modelling
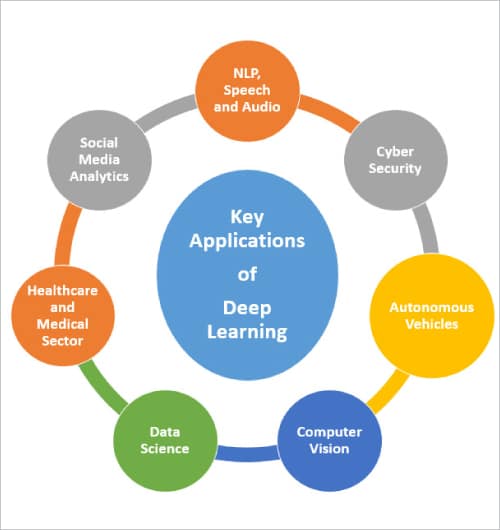
Figure 1: Key applications of deep learning
Classification of models in deep learning
A number of deep learning models are dedicated for a specific application area. In each field of research and application, a particular deep learning model is implemented to enable a higher degree of effectiveness, performance and accuracy (see Table 1).
Table 1: Deep learning models and use cases
| Deep learning model | Use cases |
| Classic neural networks (multilayer perceptrons) | Tabular data analysis, Classification and regression based problem solving |
| Convolutional neural networks | Image data sets, Optical character recognition (OCR) intelligence |
| Recurrent neural networks | Image classification, Image captioning, Sentiment analysis, Video classification |
| Self-organising maps (SOM) | Dimensionality reduction, Music, Video |
| Auto encoders | Huge data sets, Recommendation engines, Dimensionality reduction |
| Boltzmann machines | Monitoring and surveillance based applications |
Pre-trained models for multiple research domains
Pre-trained models are used to implement deep learning rapidly with high accuracy (see Table 2). These models have weights, which can be imported by researchers and scientists to deploy the deep learning application quickly in a particular domain without modelling from scratch.
| Object detection and image analytics |
|
| Natural language processing |
|
| Audio and speech |
|
The key advantages of using pre-trained models based libraries are:
- Inclusion of pre-trained weights with NLP architectures
- Inclusion of fine-tuning with pre-processing
- Easy-to-use scripts and APIs
- Multilingual support with international and regional languages
- Compatibility with graphics processing unit (GPU)
- Pre-programmed algorithms from leading companies
Installation and working with pre-trained NLP based models
HuggingFace (https://huggingface.co/) is one of the key platforms that provide pre-trained models for natural language processing (NLP). It is cloud based and can be integrated with Google Colab for running scripts.
To install the pre-trained NLP based models in Google Colab, execute the following:
! pip install pytorch-transformers ! pip install transformers ! pip install sentencepiece
Prediction of the next sequence in Google Search
When we write some text in Google Search, the next sequence is suggested by the back-end library of Google. For example, if we want to predict the next word after the sentence ‘What is the name of the Indian?’, the following transformer can be used:
import torch
from pytorch_transformers import GPT2Tokenizer, GPT2LMHeadModel
mytokenizer = GPT2Tokenizer.from_pretrained(‘gpt2’)
# Encode a text inputs
text = “what is name of the Indian “
indexed_tokens = mytokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
model = GPT2LMHeadModel.from_pretrained(‘gpt2’)
model.eval()
tokens_tensor = tokens_tensor.to(‘cuda’)
model.to(‘cuda’)
with torch.no_grad():
outs = model(tokens_tensor)
preds = outs[0]
pred_index = torch.argmax(preds[0, -1, :]).item()
pred_text = tokenizer.decode(indexed_tokens + [pred_index])
print(pred_text)
The output from the execution of this code will be predicted depending on the following:
- flag
- parliament
- others, depending upon the search
HuggingFace is providing pre-trained models for a very wide range of applications and being used by numerous corporate giants.
Prediction of a word when filling in the blanks
The classical case of filling in the blanks with real-time search can be solved using a pre-trained model of NLP.
Here is an example to predict the word that can be used in place of [MASK].
from transformers import pipeline myprediction = pipeline(‘fill-mask’, model=’bert-base-uncased’) myprediction (“This is a [MASK].”)
The output is:
[{‘score’: 0.03235777094960213,
‘sequence’: ‘this is a dream.’,
‘token’: 3959,
‘token_str’: ‘dream’},
{‘score’: 0.030467838048934937,
‘sequence’: ‘this is a mistake.’,
‘token’: 6707,
‘token_str’: ‘mistake’},
{‘score’: 0.028352534398436546,
‘sequence’: ‘this is a test.’,
‘token’: 3231,
‘token_str’: ‘test’},
{‘score’: 0.025175178423523903,
‘sequence’: ‘this is a game.’,
‘token’: 2208,
‘token_str’: ‘game’},
{‘score’: 0.024909017607569695,
‘sequence’: ‘this is a lie.’,
‘token’: 4682,
‘token_str’: ‘lie’}]
from transformers import pipeline
unmasker = pipeline(‘fill-mask’, model=’bert-base-uncased’)
myprediction (“He is a [MASK].”)
The output is:
[{‘score’: 0.17371997237205505,
‘sequence’: ‘he is a christian.’,
‘token’: 3017,
‘token_str’: ‘christian’},
{‘score’: 0.08878538012504578,
‘sequence’: ‘he is a democrat.’,
‘token’: 7672,
‘token_str’: ‘democrat’},
{‘score’: 0.06659623980522156,
‘sequence’: ‘he is a republican.’,
‘token’: 3951,
‘token_str’: ‘republican’},
{‘score’: 0.03911091387271881,
‘sequence’: ‘he is a vegetarian.’,
‘token’: 23566,
‘token_str’: ‘vegetarian’},
{‘score’: 0.036758508533239365,
‘sequence’: ‘he is a catholic.’,
‘token’: 3234,
‘token_str’: ‘catholic’}]
Prediction of a word using a pre-trained NLP model
We can predict a word using a pre-trained NLP model as follows:
import torch
from pytorch_transformers import BertTokenizer, BertModel, BertForMaskedLM
# Loading of Tokenizer
mytokenizer = BertTokenizer.from_pretrained(‘bert-base-uncased’)
# Input Tokenization
text = “[CLS] Who was Puppet Expert ? [SEP] Puppet Expert was a puppeteer [SEP]”
t_Text = mytokenizer.tokenize(text)
# Masking of Token
masked_index = 8
t_Text[masked_index] = ‘[MASK]’
assert t_Text == [‘[CLS]’, ‘who’, ‘was’, ‘Puppet’, ‘Expert’, ‘?’, ‘[SEP]’, ‘Puppet’, ‘[MASK]’, ‘was’, ‘a’, ‘puppet’, ‘##eer’, ‘[SEP]’]
# Conversion of Token
i_token = tokenizer.convert_tokens_to_ids(t_Text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Conversion of Inputs to Tensors
t_tensor = torch.tensor([i_token])
segments_tensors = torch.tensor([segments_ids])
# Loading of Weights from Pre-Training Model
model = BertForMaskedLM.from_pretrained(‘bert-base-uncased’)
model.eval()
# Invocation of GPU
t_tensor = t_tensor.to(‘cuda’)
s_tensors = segments_tensors.to(‘cuda’)
model.to(‘cuda’)
# Prediction of tokens
with torch.no_grad():
outputs = model(t_tensor, token_type_ids=s)
predictions = outputs[0]
pred_index = torch.argmax(predictions[0, masked_index]).item()
pred_token = tokenizer.convert_ids_to_tokens([pred_index])[0]
assert pred_token == ‘Expert’
print(‘Pred token is:’,pred_token)
The output is:
100%|██████████| 231508/231508 [00:00<00:00, 703114.82B/s] 100%|██████████| 433/433 [00:00<00:00, 81193.38B/s] 100%|██████████| 440473133/440473133 [00:20<00:00, 21132461.45B/s] Predicted token is: Expert
Research scholars, academicians and practitioners working in the domain of speech and natural language processing can use free and open source pre-trained models for their research work as these enable a high degree of accuracy and performance with real-world data sets. The models available in such cloud based platforms are quite effective for dynamic applications including audio forensics, speech recognition, speech-to-text translation, language analytics, and many others.


















