

The recent explosion of IoT devices, an increased focus on site reliability engineering for hybrid clouds, real-time trading analysis, etc, have led to a greater spotlight on time series analysis and time series databases. This is because much larger time series data sets are being analysed today.
It’s not uncommon to deal with petabytes of data today, even when carrying out traditional types of analysis and reporting. Traditional databases, however, do not offer optimal mechanisms to store and retrieve large scale time series data. To meet the demand of time series analysis, new types of databases are emerging.
Real-world use cases
Time series data streams are gathered in many real-world scenarios. The volume of data and the velocity of data generation differ from case to case.
Typical scenarios from different fields are described below.
- Monitoring data gathered as part of site reliability engineering: Health, performance, and capacity parameters are collected periodically over time from various layers of infrastructure and applications. These time series data streams are analysed for anomalies, fault detection, forecasting, etc. Huge amounts of time series data need to be analysed in real-time to avoid service breakdowns and for quick recovery. This data is also stored and retrieved for processing later, such as capacity forecasting.
- IoT devices and sensors generate continuous streams of data.
- Autonomous trading algorithms continuously collect data on how the markets are changing in order to optimise returns.
- The retail industry collects and monitors supply chain and inventory data to optimise costs.
- Weather forecasting teams continuously collect climate parameters such as temperature, humidity, etc, for predictions.
- Autonomous vehicles continuously collect data about how their environment is changing, adjusting the drive based on weather conditions, engine status, and countless other variables.
- In the medical field, sensors generate time data streams for blood pressure tracking, weight tracking, cholesterol measurements, heart rate monitoring, etc.
There are numerous real-world scenarios where we collect time series data streams. These demand an efficient database for storing and retrieving time series data.
Time series data analysis
Time series data is a sequence of data points collected over time intervals, giving us the ability to track changes over time. Because data points in time series are collected at adjacent time periods, the observations can be correlated. This feature distinguishes time series data from traditional data. Time series data can be useful to help recognise patterns or a trend. Knowing the value of a specific parameter at the current time is quite different than the ability to observe its behaviour over a long time interval. Time series data allows us to measure and analyse change — what has changed in the past, what is changing in the present, and what changes may take place in the future. Time series data can track changes over milliseconds, days, or even years. Table 1 outlines the typical questions that time series analysis can help to answer.
| Category | Typical questions to be addressed |
| Prognostication | What are the short- and long-term trends for a measurement or group of measurements? |
| Introspection | How do several measurements correlate over a period of time? |
| Prediction | How do I build a machine learning model based on the temporal behaviour of many measurements correlated to externally known facts? |
| Introspection | Have similar patterns of measurements preceded similar events? |
| Diagnosis | What measurements might indicate the cause of some event, such as a system failure? |
| Forecasting | How many more servers will be needed for handling next quarter’s workload? |
| Segmentation | How to divide a data stream into a sequence of discrete segments in order to reveal the underlying properties of its source? |
Typical steps in time series data analysis are:
- Collecting the data and cleaning it
- Visualising with respect to time vs key feature
- Observing the stationarity of the series
- Developing charts to understand the nature of the data
- Model building such as AR, MA, ARMA and ARIMA
- Extracting insights from the predictions
There are three components of time series analysis — trend, seasonality and residual analysis.
Trend: This indicates the direction in which the data is moving over a period of time.
Seasonality: Seasonality is about periodic behaviour — spikes or drops caused by different factors like:
- Naturally occurring events like weather fluctuations
- Business or administrative procedures like the start or end of a fiscal year
- Social and cultural behaviour like holidays or festivals
- Calendar events, like the number of Mondays per month or holidays that change every year
Residual analysis: These are the irregular fluctuations that cannot be predicted using trend or seasonality analysis.
An observed data stream could be additive (trend + seasonality + residual) or multiplicative (trend * seasonality * residual).
Once these components are identified, models are built to understand time series and check for anomalies, forecasting and correlations. For time series data modelling, AR, MA, ARMA and ARIMA algorithms are widely adopted. Many other advanced AI/ML algorithms are being proposed for better evaluation.
Time series databases
A time series database (TSDB) is a database optimised for time-stamped or time series data. Time series data is simply measurements or events that are tracked, monitored, down sampled, and aggregated over time. These could be server metrics, application performance monitoring, network data, sensor data, events, clicks, trades in a market, and many other types of analytics data.
Looking back 10 years, the amount of data that was once collected in 10 minutes for some very active systems is now generated every second. To process these high volumes, we need different tools and approaches.
To design an optimal TSDB, we must analyse the properties of time series data, and the demands of time series analysis applications. The typical characteristics of time series data and its use cases are:
- Time series is a sequence of values, each with a time value indicating when the value was recorded.
- Time series data entries are rarely amended.
- Time series data is often retrieved by reading a contiguous sequence of samples.
- Most of the time, we collect and store multiple time series. Queries to retrieve data from one or a few time series for a particular time range are very common.
- The volume and velocity of time series data is very high.
- Both long-term and short-term trends in the time series are very important for analysis.
- Summarising or aggregating high volume time series data sets is a very basic requirement.
- Traditional DB operations such as searching, sorting, joining tables, etc, are not required.
Properties that make time series data very different from other data workloads are data life cycle management, summarisation, and large range scans of many records. TSDB is designed to simplify and strengthen the process for real-world time series applications.
Storing time series data in flat files limits its utility. Data will outgrow these and the access is inefficient. Traditional RDBMS databases are not designed from the ground up for time series data storage. They will not scale well to handle huge volumes of time series data. Also, the schema is not appropriate. Getting a good performance for time series from an SQL database requires significant customisation and configuration. Without that, unless you’re working with a very small data set, an SQL-based database will simply not work properly. A NoSQL non-relational database is preferred because it scales well and efficiently to enable rapid queries based on time range.
A TSDB is optimised for best performance for queries based on a range of time. New NoSQL non-relational databases come with considerable advantages (like flexibility and performance) over traditional relational databases (RDBMS) for this purpose. NoSQL databases and relational databases share the same basic goals: to store and retrieve data and to coordinate changes. The difference is that NoSQL databases trade away some of the capabilities of relational databases in order to improve scalability. The benefits of making this trade include greater simplicity in the NoSQL database, the ability to handle semi-structured and denormalised data and, potentially, much higher scalability for the system.
At very large scales, time-based queries can be implemented as large, contiguous scans that are very efficient if the data is stored appropriately in a time series database. And if the amount of data is very large, a non-relational TSDB in a NoSQL system is typically needed to provide sufficient scalability.
Non-relational time series databases enable discovery of patterns in time series data, long-term trends, and correlations between data representing different types of events. The time ranges of interest extend in both directions. In addition to the very short time-range queries, long-term histories for time series data are needed, especially to discover complex trends.
Time series databases have key architectural design properties that make them very different from other databases. These include time-stamp data storage and compression, data life cycle management, data summarisation, the ability to handle large time series-dependent scans of many records, and time series aware queries.
For example, with a time series database, it is common to request a summary of data over a large time period. This requires going over a range of data points to perform computations like a percentile increase this month of a metric over the same period in the last six months, summarised by month. This kind of workload is very difficult to optimise for with a distributed key value store. TSDBs are optimised for exactly this use case and can give millisecond-level responses over months of data. Here is another example. With time series databases, it’s common to keep high precision data around for a short period of time. This data is aggregated and down sampled into long-term trend data. This means that for every data point that goes into the database, it will have to be deleted after its period of time is up. This kind of data life cycle management is difficult for application developers to implement in regular databases. They must devise schemes for cheaply evicting large sets of data and constantly summarising that data at scale. With a time series database, this functionality is provided out-of-the-box.
Since time series data comes in time order and is typically collected in real-time, time series databases are immutable and append-only to accommodate extremely high volumes of data. This append-only property distinguishes time series databases from relational databases, which are optimised for transactions but only accommodate lower ingest volumes. In general, depending on their particular use case, NoSQL databases will trade off the ACID principles for a BASE model (whose principles are basic availability, soft state and eventual consistency). For example, one individual point in a time series is fairly useless in isolation, and the important thing is the trend in total.
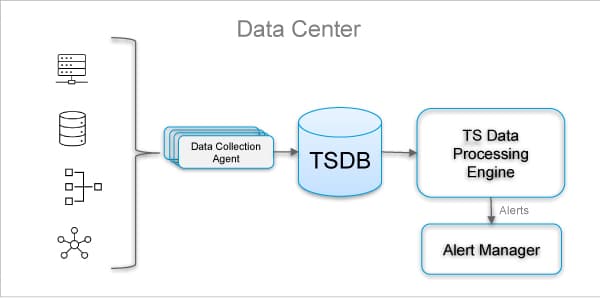
Alerts based on time series data analysis for site reliability
Time series data models are very common in site reliability engineering. Time series analysis is used to monitor system health, performance, anomaly detection, security threat detection, inventory forecasting, etc. Figure 1 shows a typical alerting mechanism based on analysing time series data collected from different components.
Modern data centres are complex systems with a variety of operations and analytics taking place around the clock. Multiple teams need access at the same time, which requires coordination. In order to optimise resource use and manage workloads, systems administrators monitor a huge number of parameters with frequent measurements for a fine-grained view. For example, data on CPU usage, memory residency, IO activity, levels of disk storage, and many other parameters are all useful to collect as time series.
Once these data sets are recorded as time series, data centre operations teams can reconstruct the circumstances that lead to outages, plan upgrades by looking at trends, or even detect many kinds of security intrusions by noticing changes in the volume and patterns of data transfer between servers and the outside world.
Open source TSDBs
Time series databases are the fastest growing segment in the database industry. There are many commercial and open source time series databases available. A few well-known open source time series databases are listed below:
- InfluxDB is one of the most popular time series open source databases, and is written in Go. It has been designed to provide a highly scalable data ingestion and storage engine. It is very efficient at collecting, storing, querying, visualising, and taking action on streams of time series data, events, and metrics in real-time. It uses InfluxQL, which is very similar to a structured query language, for interacting with data.
- Prometheus is an open source monitoring solution used to understand insights from metrics data and send the necessary alerts. It has a local on-disk time-series database that stores data in a custom format on disk. It provides a functional query language called PromQL.
- TimescaleDB is an open source relational database that makes SQL scalable for time series data. This database is built on PostgreSQL.
- Graphite is an all-in-one solution for storing and efficiently visualising real-time time series data. Graphite can store time series data and render graphs on demand. To collect data, we can use tools such as collectd, Ganglia, Sensu, telegraf, etc.
- QuestDB is a relational column-oriented database that can perform real-time analytics on time series data. It works with SQL and some extensions to create a relational model for time series data. It supports relational and time-series joins, which helps in correlating the data.
- OpenTSDB is a scalable time series database that has been written on top of HBase. It is capable of storing trillions of data points at millions of writes per second. It has a time-series daemon (TSD) and command-line utilities. TSD is responsible for storing data in or retrieving it from HBase. You can talk to TSD using HTTP API, telnet, or a simple built-in GUI. You need tools like flume, collectd, vacuumetrix, etc, to collect data from various sources into OpenTSDB.
Cloud native TSDBs
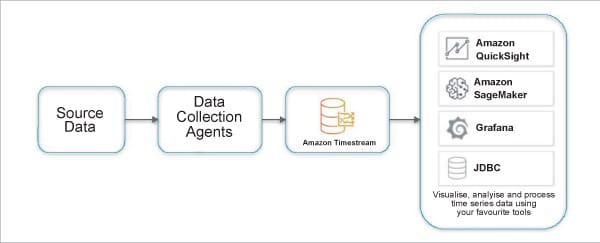
Cloud hyperscalers like Azure, AWS and Google offer time series databases and analytics services as part of their cloud portfolio. AWS Timestream is a serverless time series database service that is fast and scalable. It is used majorly for IoT applications to store trillions of events in a day and is 1000 times faster with 1/10th the cost of relational databases. Using its purpose-built query engine, you can query recent and historical data simultaneously. It provides multiple built-in functions to analyse time series data to find useful insights.
Microsoft Azure Time Series Insights provides a time series analytics engine. For data ingestion there are Azure IoT Hub and Event Hub services. To analyse cloud infrastructure and time series streams, these cloud vendors offers a range of native tools such as AWS CloudWatch, Azure Monitor, Amazon Kinesis, etc.



{kind=link}