






























































Free and open source software can help you automate document creation in the most popular formats.
Governments, businesses and other organisations create a lot of documents. When they automate their systems, they purchase software components that cost hundreds or even thousands of dollars per year or per computer. It seems like a criminal waste.
I have self-published over two dozen books. They were all created using only free and open source software (FOSS). I find that other self-published authors have spent thousands of dollars to publish just one book. This does not include marketing. I am horrified when I read or hear about their expenses.
Why not pay some attention to free choices before splurging so much money on proprietary software? In this article, I will describe how anyone can create PDF and DOCX files for free. The entire toolchain will be FOSS. This process can be easily automated and integrated with application servers.
Use CommonMark (Markdown) for the source document
You can write your source documents in plain text, markup, markdown or directly in rich text. HTML (HyperText Markup Language) is markup. It is displayed as rich text. Rich text is what you see in a browser or document editor such as LibreOffice Writer. Markup is what you see when you do View » Source on a web page. The ODT file that you create in Writer is actually a renamed zip file with mostly XML files (eXtended Markup Language).
Markdown is the opposite of markup. It uses ordinary plain-text enhancements to unobtrusively mark up text. Before the World Wide Web came into existence, the internet was mostly email. Email, BBS and Usenet (newsgroups) users developed a plain-text style of formatting for their messages. For example, bold type was wrapped in **asterisks** and italicised text was wrapped in _underscores_. When John Gruber and Aaron Swartz created Markdown in 2004, they extended this style even further. It is now the most popular form of markdown. Markdown was released as a Perl script. Markdown documents were usually saved with the extension .md. I wrote my first book in Markdown and converted it like this:
perl markdown.pl jokebook.md > jokebook.html
Other implementations of Markdown were based on the Perl script but there were some differences. Finally, in 2019, Jeff Atwood and John MacFarlane published a standardised implementation of Markdown called CommonMark. I learned about it sometime in 2020 and earned the bragging rights for the first book on CommonMark. It is called ‘CommonMark Ready Reference’. Its digital version is available for free on almost all ebook stores (except Kindle). However, I will give you a quick intro so that you have an idea what it looks like.
Figure 1 shows how Markdown uses plain text enhancements to mark-up text. A more comprehensive quick-reference card for CommonMark/Markdown is available for free from my website as a printable PDF.

CommonMark has a proper specification. It also has an implementation written in C that is blisteringly fast. I have compiled the source, and offer the Linux and Windows executables from my website. You can find the build instructions in the ebook.
After compilation or downloading the executable, you can convert your
commonmark --unsafe --validate-utf8 jokebook.md > jokebook.html
CommonMark can generate headings, paragraphs, blockquotes, images, links, lists, code spans and blocks, horizontal breaks and line breaks. That is about it. It cannot generate tables and other fancy stuff. If you want those, you can write raw HTML and use the -unsafe option. By default, CommonMark omits raw HTML to protect software systems from code injections.
The HTML that the CommonMark executable or the Markdown Perl script generates is validation-safe and well-structured. However, it will not have HTML, HEAD, TITLE or BODY tags. The executable’s sole purpose is to create HTML markup that can be straightaway used in a pre-existing page or HTML template.
Imagine that this is the markdown source document:
Science Jokes ------------- * **How many astronauts would it take to a screw a lightbulb?** One to turn the bulb and several to prevent the spacecraft from spinning in the same direction. * **What did one radio wave say to another?** “You are interfering with my work.” * **What’s a radio engineer’s favourite food?** A can of tuna…..
CommonMark can be used to convert it like this:
echo ‘<!DOCTYPE html><html><title>2020 Jokebook</title></head><body>’ > jokebook.html commonmark --unsafe --validate-utf8 jokebook.md >> jokebook.html echo ‘</body></html>’ >> jokebook.html
The output HTML will look like this:
<!DOCTYPE html><html><title>2020 Jokebook</title></head><body> <h2>Science Jokes</h2> <ul> <li><strong>How many astronauts would it take to a screw a lightbulb?</strong><br /> One to turn the bulb and several to prevent the spacecraft from spinning in the same direction.</li> <li><strong>What did one radio wave say to another?</strong><br /> "You are interfering with my work."</li> <li><strong>What’s a radio engineer’s favourite food?</strong><br /> A can of tuna.</li> </ul> </body></html>
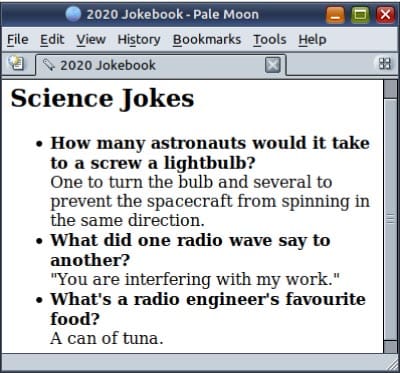
CommonMark-generated markup starts from <h2> and ends in </ul>. The rest is the HTML template. Figure 2 shows what the HTML looks like in a browser.
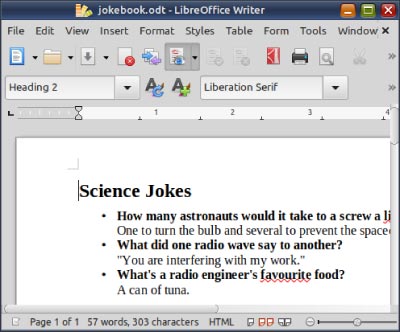
Use LibreOffice to create ODT, DOCX and PDFs
You already know that LibreOffice is the FOSS alternative to Microsoft Office. It has a word processor Writer (the Word alternative), spreadsheet application Calc (the Excel alternative), presentation slide maker Impress (the PowerPoint alternative), and a few other applications. While LibreOffice hoots and toots like a regular GUI application, it also has a demure command-line interface.
To convert the afore-mentioned HTML document to ODT format, type:
libreoffice --convert-to “odt” jokebook.html
You can use the same HTML document and convert it to DOCX so that Microsoft Office users can feel happy. (Microsoft Word can edit ODT files just fine.)
libreoffice --convert-to “docx:MS Word 2007 XML” jokebook.html
You can use the ODT or DOCX file that you generated and convert it to a PDF file:
libreoffice --convert-to “pdf” jokebook.odt
Why not convert to PDF straight from the HTML? Why create the intermediate ODT or DOCX file? Because the HTML document does not have any concept of page size, margins, headers, footers and all that jazz.
Create documents with images
When you convert a HTML document containing images, the resultant ODT or DOCX documents will show the images all right. When you move the documents or mail them to someone, the images will disappear. This is because the images in the ODT or DOCX documents continue to be loaded from the source image files. To fix this problem, you need to encode the images as text. This is similar to how images and attachments are encoded in email messages — using base64 encoding. View the message source of an email containing an attachment; you will find the file encoded as plain text.
Instead of using an image file like this:
<img src=”lion-and-deer.png” />
… you can encode it as text like this …
<img src=”data:image/png;base64,iVBORw0KGgoAAAA…” />
That is not all. I have truncated the actual text of the encoded image. The full text is nearly 600 lines. If you are curious, try a command like this:
base64 lion-and-deer.png
You do not have to dirty your hands with manual text-encoding. LibreOffice will encode the images as text.
echo ‘<!DOCTYPE html><html><title>2020 Jokebook</title></head><body>’ > jokebook.htm commonmark --unsafe --validate-utf8 jokebook.md >> jokebook.htm echo ‘</body></html>’ >> jokebook.htm libreoffice --convert-to “html:HTML:EmbedImages” jokebook.htm
Here, the .htm file (referring to an external image) was created by CommonMark. LibreOffice consumed that .htm file and created a .html file with the text-encoded image. This self-contained HTML is now portable and not dependent on any external files. When you convert such an HTML document, the resultant ODT or DOCX file will also be self-contained and portable. Even if you delete the image file, you will still be able to see it in the .html, .odt or .docx files.
libreoffice --convert-to “html:HTML:EmbedImages” jokebook.htm libreoffice --convert-to “odt” jokebook.html libreoffice --convert-to “docx:MS Word 2007 XML” jokebook.odt libreoffice --convert-to “pdf” jokebook.odt
Enhanced document content
As mentioned earlier, CommonMark outputs only a limited set of HTML tags. For creating content that it does not support, you will have to add raw HTML in your markdown.
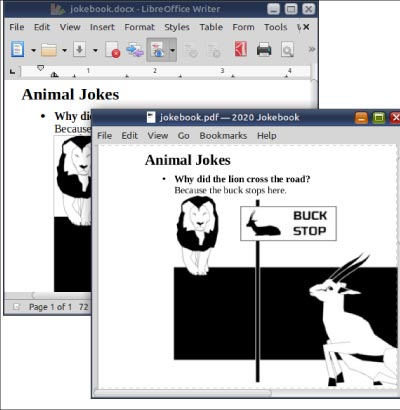
Animal Jokes ------------ * **Why did the lion cross the road?** Because <span style=”color: white; background-color: red; border-radius: 0.5em; border: 2px dashed yellow; “>the buck stops here</span>. 
Do not go overboard with this raw HTML content. LibreOffice has its own limited set of HTML tags and CSS styles that it can convert.
What does the screenshot in Figure 6 say? LibreOffice does not do rounded corners, among other things. So, temper your excitement.
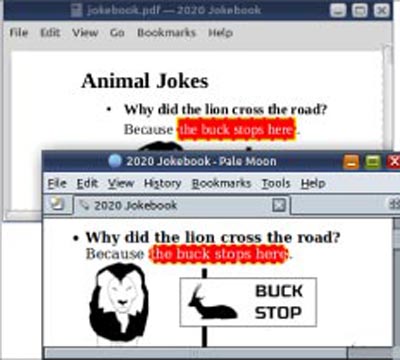
This use of raw HTML is crude. It defeats the idea of markdown. The purpose of CommonMark is to create a well-structured document. Special styling can be affected by including CSS styles in the HTML template. I leave that as homework for you or your developers. (Just brush up on CSS pseudo-classes, selectors and attribute matching.) I gave the above example to make the concept easy to understand.
Unlike styles, tables are not fancy stuff. They are the nuts and bolts of financial documents. For those, you can use raw HTML inline. LibreOffice will convert HTML tables all right.
What about headers and footers? Does CommonMark support them? Can they be added to the HTML template similar to CSS styles? Unfortunately, no. This kind of toolchain is good for one-page documents. Or, multi-page documents without headers and footers. If you want those, then you have to use a different tool called wkhtmltopdf. This is essentially a headless Firefox browser that can convert heavily formatted HTML documents to PDF. You can specify headers and footers using separate HTML files. I created all 29 of my books using this tool. It supports lots of CSS styles that LibreOffice does not support. My books would not look so rich if I relied on LibreOffice. (wkhtmltopdf is based on an old Firefox codebase that is not being updated. A lone Indian is maintaining it. It has a few bugs. Read my Unicode tricks article on how I fixed them.) Also, unlike LibreOffice, wkhtmltopdf can execute JavaScript. It has an option for adding a few seconds of delay so that the JavaScript can do its thing before wkhtmltopdf starts printing the document to PDF. So, for simple documents, use LibreOffice. And, for heavy-duty documents, use wkhtmltopdf. Both these programs will use the headings in the source document to create the bookmark tree in the PDF document. LibreOffice has one advantage that wkhtmltopdf does not have — it can create ePUB ebooks and several other types of documents.
Additional document features
If you have to merge two ODT or DOCX documents, I do not know of or care for any tool to do it. Do the merging in the markdown source material and then create the combined document.
For PDFs, there are lots of tools. For my books, I have to combine some page-size images with the PDF of the interior pages. For that, I use ImageMagick and pdftk.
magick title-page.png -resize 100% front.pdf pdftk front.pdf jokes.pdf output book.pdf
pdftk is a very powerful tool and does more than merging PDF pages or collating them from different documents. It can also watermark and encrypt your PDF.
pdftk book.pdf output book-encrypted.pdf \
encrypt_128bit \
owner_pw RcHrDsTlMn^012 \
user_pw FrSfTWrFnDtn^321
And, for a touch of class, add metadata to the PDF:
echo “InfoBegin” > meta.txt echo “InfoKey: Title” >> meta.txt echo “InfoValue: 2020 Jokebook by V. Subhash” >> meta.txt echo “InfoBegin” >> meta.txt echo “InfoKey: Subject” >> meta.txt echo “InfoValue: Fresh Clean Jokes” >> meta.txt
echo “InfoBegin” >> meta.txt echo “InfoKey: Author” >> meta.txt echo “InfoValue: V. Subhash (© 2022 V. Subhash. All rights reserved.)” >> meta.txt pdftk “jokebook.pdf” update_info meta.txt output 2020-jokebook.pdf
Whatever I cannot do with these free PDF tools, I go ahead and write my own custom utility using iText Java. For example, when I found that pdftk was unable to handle some of my bigger books, I used a JAR file executable that I had created using iText.
Use in online applications
Document creation requires a lot of heavy lifting in terms of CPU usage, disk access and memory requirements. Do not integrate these tools directly with web applications. Use a dæmon (background process or service) that is launched by the OS on startup to do the document creation. Your web applications should just queue document-creation jobs to this dæmon. When the documents are ready, the dæmon should invoke an API routine in the web application to notify that the job has been completed. Otherwise, your online users will crash your system when their numbers build up.
Donate
If free software such as those mentioned in this article helped you to reduce costs, then make it a point to donate some money to their projects. If you are an independent software vendor (ISV), then tell your client that you did not write all the code and some part of the system relies on free tools. Tell the client to make donations commensurate to the usage of the free software in that system. The creator of iText has an incredible story (check the Reference given at the end of this article) of how Google refused to offer nothing more than a T-shirt and a mug for using his PDF library in their products such as Google Analytics, Google Docs and Google Calendar. Do not be like that. Indian corporations have a statutory obligation to divert a certain amount of their profits to charitable causes. Most of them will be glad to route donations to open source projects as CSR (corporate social responsibility) grants.















