






























































Dive into the world of Apache SINGA, a distributed platform for training big deep learning models over large data sets. Discover its architecture, features, and learn how to harness its potential using Docker.
Apache SINGA was developed by the DB System Group of the National University of Singapore in partnership with Zhejiang University’s databases group. This system assists in picture identification as well as natural language processing. It embraces many well-known deep learning models, and consists of three main parts: IO Core, Model, and Core. Initiated in 2014, its initial release was on October 8, 2015. Apache Incubator accepted its prototype in March 2015.
Apache SINGA, a distributed deep learning system, provides enhanced IO classes to write, read, encode, and decode files and data. It offers a built-in programming model based on the layer abstraction, which supports a variety of popular deep learning models. This application can be used to train synchronously, asynchronously, or in a combination of both. Hybrid training frameworks can also be modified to achieve good scalability. SINGA delivers different neural net partitioning schemes for training big models. The SINGA project has been released under Apache License 2.
History of Apache SINGA
There has been a huge surge of interest, in both industry and academia, in deep learning. It has provided great accuracy in areas such as multi-modal data analysis and state-of-the-art algorithms. However, many distributed training systems have been proposed to improve runtime performance like Caffe, Purine, Torch, and Google’s DistBelief. Through these systems, deep learning models can benefit from deeper structures and larger training data sets.
However, there are a few major challenges in developing a deep learning system. For example, there are a large number of parameters that suffer from a vast amount of communication overhead to synchronise nodes. Therefore, the scalability in terms of training time to reach a certain degree of accuracy is a challenge. Another challenge is that it is non-trivial for programmers to develop and train models with deep and complex model structures. Distributed training further increases the load of programmers, e.g., data and model partitioning, and network communication.
Hence, a distributed deep learning platform was introduced. SINGA is designed with a built-in programming model that supports a variety of popular deep learning models, such as energy models like restricted Boltzmann machines (RBMs), and feed-forward models including convolutional neural networks (CNNs).
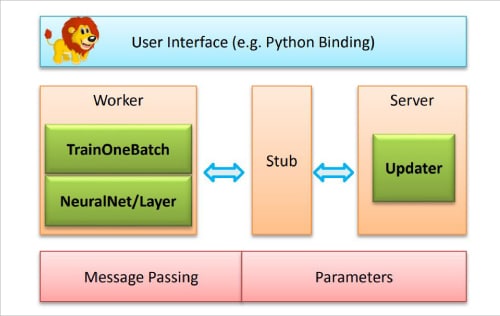
SINGA architecture
The SINGA architecture is very flexible and can run asynchronous, synchronous and hybrid training frameworks. Synchronous training enhances the efficiency of one iteration, and asynchronous training boosts the convergence rate. If the user has a fixed cluster size, then SINGA can run a hybrid framework that maximises scalability by trading off between efficiency and the convergence rate. SINGA can also help with different neural net partitioning programs to parallelise the training of large models, either through hybrid partitioning or feature dimension partitioning, such as partitioning on the batch dimension. It has GPU support and integrates with cluster management software.
SINGA applies stochastic gradient descent (SGD) algorithm to update parameters of deep learning models. The workload is dispersed over worker and server units. At each round, all workers call TrainOneBatch function to compute parameter gradients. TrainOneBatch pulls a NeuralNet object on behalf of the neural net, and calls the layers of the NeuralNet in a definite order. The resulting gradients are sent to the local stub that collects the requests and forwards them to equivalent servers for updating. Servers respond to workers with the improved parameters for the next iteration. To start a training job, users submit a job configuration consisting of four components:
- A NeuralNet describing the neural net structure with detailed layer settings and their connections.
- A TrainOneBatch algorithm that is custom-made for different model categories.
- An Updater defining the protocol for updating parameters at the server side.
- A Cluster topology specifying the distributed architecture of workers and servers.
Features
This open source platform is designed to scale up deep learning to thousands of GPUs, which means you can process massive amounts of data with improved accuracy. Developers can tailor Apache SINGA to their specific needs, with customisable features and modular design. Here are some of SINGA’s key features.
User-friendly: It comes with an intuitive programming model based on the layer abstraction, and many built-in layers are already provided. It is easy for users to implement their deep learning algorithms without much knowledge of the underlying distributed platform. Different types of popular deep learning models can be expressed and trained using SINGA.
Scalable: It provides a general architecture to exploit the scalability of different training frameworks. Synchronous training frameworks improve the efficiency of training iterations while asynchronous training frameworks improve the convergence rate. SINGA also offers diverse partitioning schemes to parallelise the training of large models, feature dimension or hybrid partitioning.
Other features: It supports training on a single node (i.e., process) with multiple GPU cards. It is integrated with the Mesos framework using Docker, which bundles Mesos and SINGA.
Installation guidelines using Docker
Assuming Docker is already installed on the system, add your user to the Docker group to run Docker commands without sudo.
CPU-only $ docker run -it apache/singa:X.Y.Z-cpu-ubuntu16.04 /bin/bash
With GPU enabled, install Nvidia-Docker after installing Docker:
$ nvidia-docker run -it apache/singa:X.Y.Z-cuda9.0-cudnn7.4.2-ubuntu16.04 /bin/bash
Run the command given below:
version-(cpu gpu)[-devel]
Explanation
Version: SINGA version
cpu: The image cannot run on GPUs
gpu: The image can run on Nvidia GPUs
devel: Indicator for development
OS: OS version number
Apache SINGA opens up a new realm of possibilities in deep learning. Its documentation and code are available on the Apache Incubator website. A quick start guide and some sample examples are also provided.
















