































































The Document Object Model (DOM) is a programming interface for HTML and XML documents. It provides a structured representation of a document and it defines a way that the structure can be accessed from the programs so that they can change the document structure, style and content. The DOM provides a representation of the document as a structured group of nodes and objects that have properties and methods. Essentially, it connects Web pages to scripts or programming languages.
A Web page is a document that can either be displayed in the browser window or as an HTML source that is in the same document. The DOM provides another way to represent, store and manipulate that same document. In simple terms, we can say that the DOM is a fully object-oriented representation of a Web page, which can be modified by any scripting language.
The W3C DOM standard forms the basis of the DOM implementation in most modern browsers. Many browsers offer extensions beyond the W3C standard.
All the properties, methods and events available for manipulating and creating the Web pages are organised into objects. For example, the document object that represents the document itself, the tableObject that implements the special HTMLTableElement DOM interface to access the HTML tables, and so forth.
Why is DOM important?
Dynamic HTML (DHTML) is a term used by some vendors to describe the combination of HTML, style sheets and scripts that allow documents to be animated. The W3C DOM working group is aiming to make sure interoperable and language-neutral solutions are agreed upon.
As Mozilla claims the title of Web Application Platform, support for the DOM is one of the most requested features; in fact, it is a necessity if Mozilla wants to be a viable alternative to the other browsers. The user interface of Mozilla (also Firefox and Thunderbird) is built using XUL and the DOM to manipulate its own user interface.
How do I access the DOM?
You dont have to do anything special to begin using the DOM. Different browsers have different implementations of it, which exhibit varying degrees of conformity to the actual DOM standard but every browser uses some DOM to make Web pages accessible to the script.
When you create a script, whether its inline in a script element or included in the Web page by means of a script loading instruction, you can immediately begin using the API for the document or window elements. This is to manipulate the document itself or to get at the children of that document, which are the various elements in the Web page.
Your DOM programming may be something as simple as the following, which displays an alert message by using the alert( ) function from a window object or it may use more sophisticated DOM methods to actually create them, as in the longer examples that follow:
<body onload = window.alert (welcome to my home page!); >
Aside from the script element in which JavaScript is defined, this JavaScript sets a function to run when the document is loaded. This function creates a new element H1, adds text to that element, and then adds H1 to the tree for this document, as shown below:
<html>
<head>
<script>
// run this function when the document is loaded
window.onload = function() {
// create a couple of elements
// in an otherwise empty HTML page
heading = document.createElement(h1);
heading_text = document.createTextNode(Big Head!);
heading.appendChild(heading_text);
document.body.appendChild(heading);
}
</script>
</head>
<body>
</body>
</html>
DOM interfaces
These interfaces just give you an idea about the actual things that you can use to manipulate the DOM hierarchy. The object representing the HTMLFormElement gets its name property from the HTMLFormElement interface but its className property from the HTMLElement interface. In both cases, the property you want is simply in the form object.
Interfaces and objects
Many objects borrow from several different interfaces. The table object, for example, implements a specialised HTML table element interface, which includes such methods as createCaption and insertRow. Since an HTML element is also, as far as the DOM is concerned, a node in the tree of nodes that makes up the object model for a Web page or an XML page, the table element also implements the more basic node interface, from which the element derives.
When you get a reference to a table object, as in the following example, you routinely use all three of these interfaces interchangeably on the object, perhaps unknowingly:
var table = document.getElementById (table);
var tableAttrs = table.attributes; // Node/Element interface
for (var i = 0; i < tableAttrs.length; i++) {
// HTMLTableElement interface: border attribute
if(tableAttrs[i].nodeName.toLowerCase() == border)
table.border = 1;
}
// HTMLTableElement interface: summary attribute
table.summary = note: increased border ;
Core interfaces in the DOM
These are some of the important and most commonly used interfaces in the DOM. These common APIs are used in the longer examples of DOM. You will often see the following APIs, which are types of methods and properties, when you use DOM.
The interfaces of document and window objects are generally used most often in DOM programming. In simple terms, the window object represents something like the browser, and the document object is the root of the document itself. The element inherits from the generic node interface and, together, these two interfaces provide many of the methods and properties you use on individual elements. These elements may also have specific interfaces for dealing with the kind of data those elements hold, as in the table object example.
The following are a few common APIs in XML and Web page scripting that show the use of DOM:
- document.getElementById (id)
- element.getElementsByTagName (name)
- document.createElement (name)
- parentNode.appendChild (node)
- element.innerHTML
- element.style.left
- element.setAttribute
- element.getAttribute
- element.addEventListener
- window.content
- window.onload
- window.dump
- window.scrollTo
Testing the DOM API
Here, you will be provided samples for every interface that you can use in Web development. In some cases, the samples are complete HTML pages, with the DOM access in a <script> element, the interface (e.g., buttons) necessary to fire up the script in a form, and the HTML elements upon which the DOM operates listed as well. When this is the case, you can cut and paste the example into a new HTML document, save it, and run the example from the browser.
There are some cases, however, when the examples are more concise. To run examples that only demonstrate the basic relationship of the interface to the HTML elements, you may want to set up a test page in which interfaces can be easily accessed from scripts.
An introduction to the DOM inspector
The DOM inspector is a Mozilla extension that you can access from the Tools -> Web Development menu in SeaMonkey, or by selecting the DOM inspector menu item from the Tools menu in Firefox and Thunderbird or by using Ctrl/Cmd+Shift+I in either application. The DOM inspector is a standalone extension; it supports all toolkit applications, and its possible to embed it in your own XULRunner app. The DOM inspector can serve as a sanity check to verify the state of the DOM, or it can be used to manipulate the DOM manually, if desired.
When you first start the DOM inspector, you are presented with a two-pane application window that looks a little like the main Mozilla browser. Like the browser, the DOM inspector includes an address bar and some of the same menus. In SeaMonkey, additional global menus are available.
Using the DOM inspector
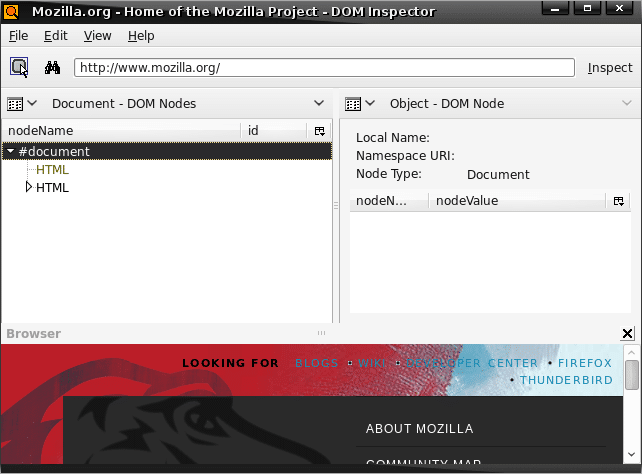
Once youve opened the document for the page you are interested in Chrome, youll see that it loads the DOM nodes viewer in the document pane and the DOM node viewer in the object pane. In the DOM nodes viewer, there should be a structured, hierarchical view of the DOM.
By clicking around in the document pane, youll see that the viewers are linked; whenever you select a new node from the DOM nodes viewer, the DOM node viewer is automatically updated to reflect the information for that node. Linked viewers are the first major aspect to understand when learning how to use the DOM inspector.
Inspecting a document
When the DOM inspector opens, it may or may not load an associated document, depending on the host application. If it doesnt automatically load a document or loads a document other than the one youd like to inspect, you can select the desired document in a few different ways.
There are three ways of inspecting any document, which are described below.
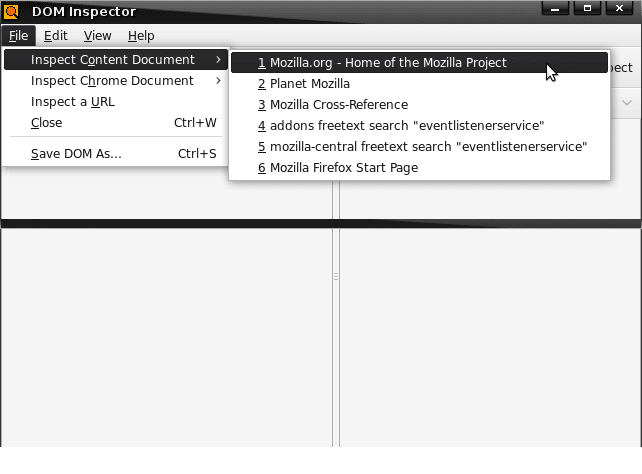
Inspecting content documents: The Inspect Content Document menu popup can be accessed from the File menu, and it will list the currently loaded content documents. In the Firefox and SeaMonkey browsers, these will be the Web pages you have opened in tabs. For Thunderbird and SeaMonkey Mail and News, any messages youre viewing will be listed here.
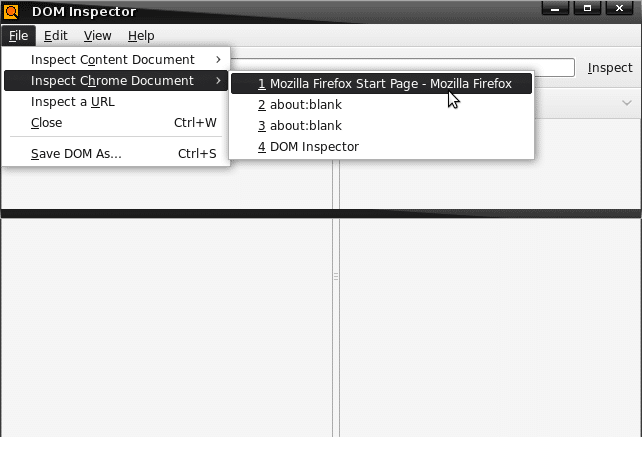
Inspecting Chrome documents: The Inspect Chrome Document menu popup can be accessed from the File menu, and it will contain the list of currently loaded Chrome windows and sub-documents. A browser window and the DOM inspector are likely to already be open and displayed in this list. The DOM inspector keeps track of all the windows that are open, so to inspect the DOM of a particular window in the DOM inspector, simply access that window as you would normally do and then choose its title from this dynamically updated menu list.
Inspecting arbitrary URLs: We can also inspect the DOM of arbitrary URLs by using the Inspect a URL menu item in the File menu, or by just entering a URL into the DOM inspectors address bar and clicking Inspect or pressing Enter. We should not use this approach to inspect Chrome documents, but instead ensure that the Chrome document loads normally, and use the Inspect Chrome Document menu popup to inspect the document.
When you inspect a Web page by this method, a browser pane at the bottom of the DOM inspector window will open up, displaying the Web page. This allows you to use the DOM inspector without having to use a separate browser window, or without embedding a browser in your application at all. If you find that the browser pane takes up too much space, you may close it, but you will not be able to visually observe any of the consequences of your actions.
DOM inspector viewers
You can use the DOM nodes viewer in the document pane of the DOM inspector to find and inspect the nodes you are interested in. One of the biggest and most immediate advantages that this brings to your Web and application development is that it makes it possible to find the mark-up and the nodes in which the interesting parts of a page or a piece of the user interface are defined.
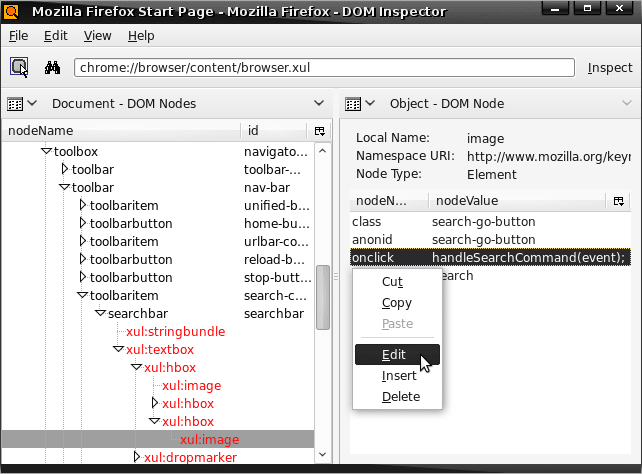
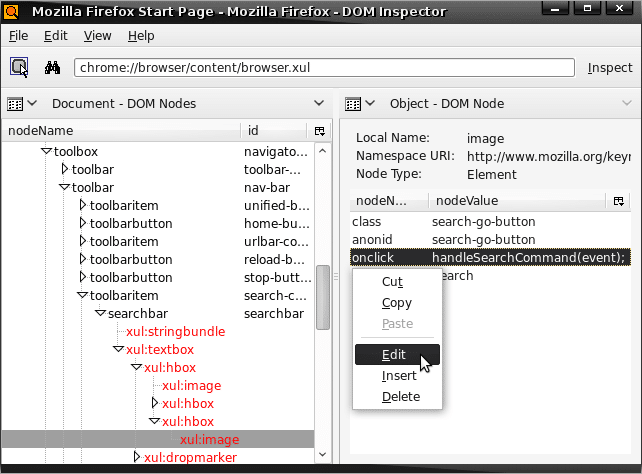
One common use of the DOM inspector is to find the name and location of a particular icon being used in the user interface, which is not an easy task otherwise. If youre inspecting a Chrome document, as you select nodes in the DOM nodes viewer, the rendered versions of those nodes are highlighted in the user interface itself. Note that there are bugs that prevent the flasher from the DOM inspector APIs that are working currently on certain platforms.
If you inspect the main browser window, for example, and select nodes in the DOM nodes viewer, you will see the various parts of the browser interface being highlighted with a blinking red border. You can traverse the structure and go from the topmost parts of the DOM tree to lower level nodes, such as the search-go-button icon that lets users perform a query using the selected search engine.
The list of viewers available from the viewer menu gives you some idea about how extensive the DOM inspectors capabilities are. The following descriptions provide an overview of these viewers capabilities:
- The DOM nodes viewer shows attributes of nodes that can take them, or the text content of text nodes, comments and processing instructions. The attributes and text contents may also be edited.
- The Box Model viewer gives various metrics about XUL and HTML elements, including placement and size.
- The XBL Bindings viewer lists the XBL bindings attached to elements. If a binding extends to another binding, the binding menu list will list them in descending order to root binding.
- The CSS Rules viewer shows the CSS rules that are applied to the node. Alternatively, when used in conjunction with the Style Sheets viewer, the CSS Rules viewer lists all recognised rules from that style sheet. Properties may also be edited. Rules applying to pseudo-elements do not appears.
- This viewer gives a hierarchical tree of the object panes subject. The JavaScript Object viewer also allows JavaScript to be evaluated by selecting the appropriate menu item in the context menu.
Three basic actions of DOM node viewers are described below.
Selecting elements by clicking: A powerful interactive feature of the DOM inspector is that when you have it open and have enabled this functionality by choosing Edit > Select Element by Click (or by clicking the little magnifying glass icon in the upper left portion of the DOM Inspector application), you can click anywhere in a loaded Web page or the Inspect Chrome document. The element you click will be shown in the document pane in the DOM nodes viewer and the information will be displayed in the object pane.
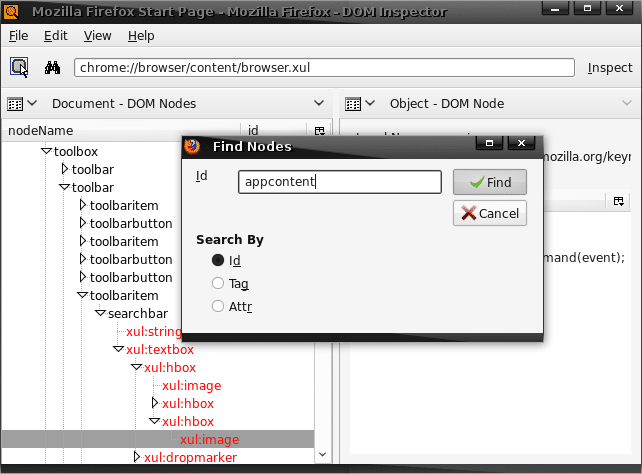
Searching for nodes in the DOM: Another way to inspect the DOM is to search for particular elements youre interested in by ID, class or attribute. When you select Edit > Find Nodes... or press Ctrl + F, the DOM inspector displays a Find dialogue that lets you find elements in various ways, and that gives you incremental searching by way of the <F3> shortcut key.
Updating the DOM, dynamically: Another feature worth mentioning is the ability the DOM inspector gives you to dynamically update information reflected in the DOM about Web pages, the user interface and other elements. Note that when the DOM inspector displays information about a particular node or sub-tree, it presents individual nodes and their values in an active list. You can perform actions on the individual items in this list from the Context menu and the Edit menu, both of which contain menu items that allow you to edit the values of those attributes.
This interactivity allows you to shrink and grow the element size, change icons, and do other layout-tweaking updatesall without actually changing the DOM as it is defined in the file on disk.
References
[1] https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model
[2] https://developer.mozilla.org/en/docs/Web/API/Document

















{kind=link}