






























































According to Wikipedia, NoSQL (Not only SQL) databases provide a mechanism for storage and retrieval of data that is modelled on means other than the tabular relations used in relational databases.
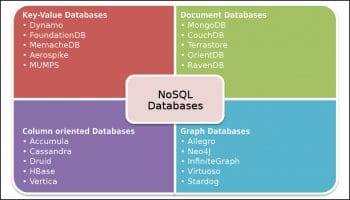
There are four main types of NoSQL databases as shown in Figure 1.
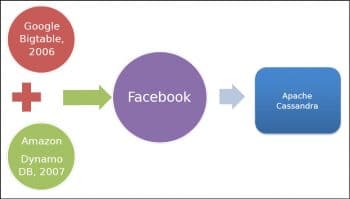
Apache Cassandra is an open source NoSQL database and management system. It was designed to handle large amounts of data across many servers, data centres and clouds. It can store hundreds of terabytes of data, and differs a lot from relational database management systems (RDBMS). Apache Cassandra was developed by the Apache Software Foundation in 2008, is written in the Java language, and supports a cross-platform operating system. Initially developed by Facebook to power its inbox search feature, it is being used by many other organisations, such as Twitter, Reddit, Rackspace, Ciscom, Cloudkick, among others.


Cassandras architecture is different. It consists of various nodes all over the network. There is no master node concept in Cassandra; every node can serve any request. Each node contains different data, which makes it seem as if it is distributed across all the data centres. It provides automatic data distribution across all nodes, and is a ring or database cluster. The concept of replication can be configured across one or many data centres, and also at multiple cloud availability zones for achieving high availability.
Cassandra provides various features such as scalability, durability, storing duplicate copies of data across all the nodes available in a network, and replication. This means that if any node goes down, other copies of the nodes data are available on other machines as failover, which can be used. Thus, Cassandra provides anytime access to the data.
There are various key features in Cassandra that are better than what other databases offer. Cassandra consists of a data model in which rows are partitioned. It offers a schema-free data model. Rows are organised as a table, in which the first component of a tables primary key is the partition key. Within a partition, rows are clustered by the remaining columns of the key. Other columns may be indexed separately from the primary key. It does not support joins or sub-queries; rather, it emphasises de-normalisation through features such as collections. It supports linear scalability, which means that if two nodes can manage 100,000 operations per second, four nodes will be able to manage 200,000 operations per second and eight nodes will handle 400,000 operations per second.

Where can Apache Cassandra be used?
1. Cassandra can be used where there is a requirement for data to be ingested at a very high speed with all the features, reliability and redundancy.
2. It is used in situations where low coupling, high throughput and low latency to read and write is required.
3. It is preferred when there is a tight connection between the data.
4. Cassandra is used when there is a need to store a large amount of data feeds from customers.
5. It is used to store a large volume of data by compressing it, e.g., sound files of about 120MB can be stored by compressing them to about 2-5MB.
6. It can be used for persistent data storage, i.e., data will be available only for the specified session, and for finding particular data based on the situation.
7. It can be used for geographically distributing the data and for real-time querying.
Case study
There are various organisations that are using Apache Cassandra to maintain data distribution across various servers. Let us look at how these organisations switched to this technology in the following case study of eBay.
eBay is one of the worlds largest online markets that enables its users to buy and sell anything, from anywhere. Whenever any user requests for a search, a huge amount of data corresponding to this search needs to be retrieved and displayed on the screen. There was a need for a database that enabled retrieval with high speed, to satisfy the customers requirements.
Cassandra can be used in such cases as it supports a large amount of data across various nodes. It makes data retrieval from these nodes easy, provides low latency, high throughput, and ensures all-time availability even during peak loads as well as accuracy of the searched data, which satisfies the customer.
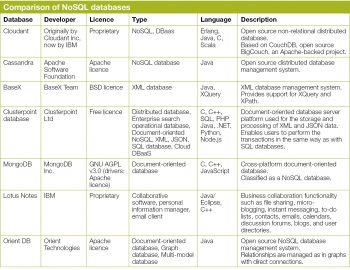
References
[1] http://en.wikipedia.org/wiki/Document-oriented_database
[2] http://www.cubrid.org/blog/dev-platform/nosql-benchmarking/
[3] http://en.wikipedia.org/wiki/NoSQL
[4] http://en.wikipedia.org/wiki/Apache_Cassandra
[5] http://www.datastax.com/resources/casestudies/ebay
[6] http://planetcassandra.org/apache-cassandra-use-cases/

















{kind=link}