






























































A NoSQL or a Not only SQL database is a non-relational, largely distributed database system that can store and analyse very complicated and unstructured data with ease. It addresses the issues that are faced by modern day applications when using traditional databases.
NoSQL database types
NoSQL comprises a few different types of database technologies, each with its own design, function and set of uses.
- Document databases: This category of NoSQL databases pairs each key with a complex data structure called a document, which can store and process data in many different arrangements based on the requirements. These arrangements include key-value pairs, key-array pairs or even a complex data structure such as a nested document.
- Key-value databases: These are the most simple and widely used NoSQL database technologies. Each object or item in the database is stored with a unique attribute name, also called as key, together with its value. Key-value databases combine a few elements from traditional relational databases as well, such as the ability to provide a value with a type to perform more data operations over it, like an integer or a float.
- Wide-column databases: These are designed to cope with tremendous volumes of data that can span across millions of columns. These databases, notably, Cassandra and Hadoop HBase, are optimised for processing queries over large datasets, where data is grouped and stored in columns rather than rows.
- Graph databases: These are based on the concept of Graph Theory. They are designed for data that is well represented and interconnected. Graph databases are commonly used to store information obtained from social media connections, real-world applications, etc.
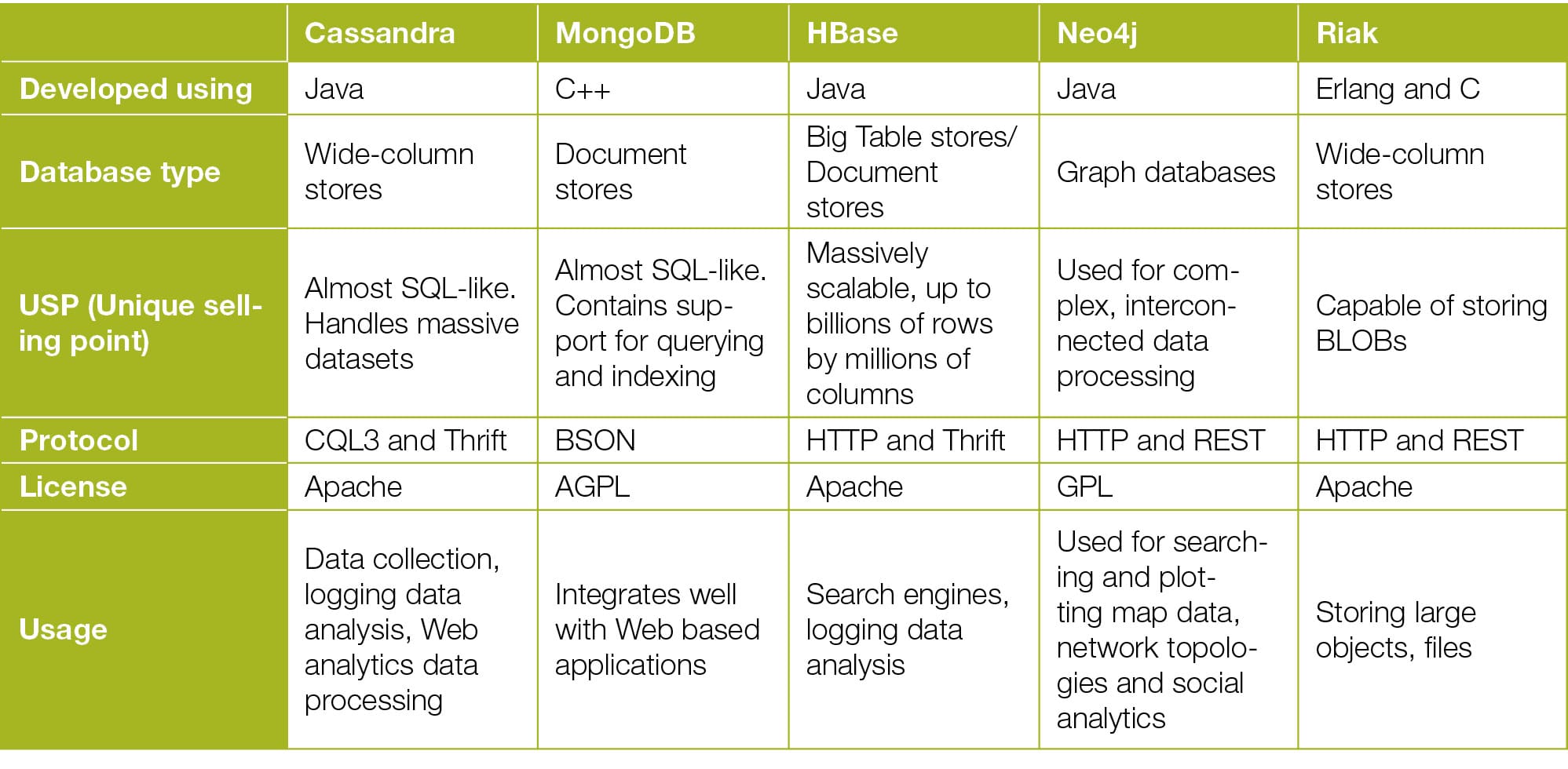
Table 1 briefly compares some of the most common and frequently used NoSQL databases.
The benefits of NoSQL
Now that we have understood what a NoSQL database is, let us have a quick look at some of its key features and benefits compared to traditional relational databases.
- Easy and quick scaling: NoSQL databases can scale out much faster than traditional RDBMSs because of the monolithic architecture followed by most of the latter variety. Scaling can be achieved by simply adding more nodes to the NoSQL database cluster according to the data storage needs.
- Schema-less data storage: NoSQL databases can store and handle all types of data, whether they are structured, non-structured or even semi-structured. This is possible as NoSQL databases have no fixed data model. This flexibility enables organisations to access and store much larger quantities of data, as and when required.
- Quick and easy data manipulation: While traditional relational databases use their own specific query languages to perform any data manipulations and operations, NoSQL databases use JSON and other such object-oriented APIs to perform the same tasks. This makes it easier for developers to code and develop their applications and integrate them to NoSQL databases.
- No SPoF (Single Point of Failure): The best part about using a NoSQL database is that most of the underlying complex tasks such as high availability with automatic load balancing, clustering, etc, are all performed and managed by the database itself. Most of the current and popular NoSQL databases come with inbuilt fault tolerance and can continue to function even if a couple of nodes go down.
NoSQL databases have a variety of unique use cases and deployment scenarios. Some of the most common use cases of these databases are:
- Data mining of logs: NoSQL databases can be used to store and analyse large datasets of logs. A good example of one such NoSQL database is Cassandra, which can manage and mine data out of log files that are extremely large in size.
- Real-time analytics: NoSQL databases are very popular when it comes to mining data that is constantly changing. Organisations can track the real-time performance of their systems, monitor stocks or track unique user hits on a website when a NoSQL database is used.
- Big Data processing: Perhaps one of the most interesting and key uses of NoSQL databases is in the Big Data industry, where a NoSQL database can be used to store, analyse and provide useful insights on data that is simply too massive for a traditional RDBMS to handle.
Introducing Apache CouchDB
CouchDB is a highly concurrent NoSQL database that is designed to scale horizontally across numerous devices with ease, and be fault-tolerant and reliable. It is a document-oriented NoSQL database that uses many programming languages such as JSON to store data, JavaScript to query the data using MapReduce, and HTTP as an application interface.
Unlike traditional RDBMSs, CouchDB stores its databases as a collection of independent documents. Each of these documents contains its own schema and metadata. The metadata contains additional attributes such as the revision number and replication information, which can be used by developers during the replication process to synchronise two or more CouchDB databases.
Installation
CouchDB can be installed both via packages as well as from source. Installation from packages is quite simple in case you are using a Debian or Ubuntu system. All you need to do is run the following command at the terminal:
# sudo apt-get install couchdb
Note: To install using the source files, download the latest source tar ball from CouchDBs official site: http://couchdb.apache.org/#download. Once downloaded, uncompress it and build the packages using the make command.
Running basic commands
After a successful installation, lets check whether our CouchDB instance is up and running. For that, simply run a curl GET command as shown:
# curl -X GET http://<COUCHDB_SERVER_IP>:5984
where COUCHDB_SERVER_IP will be the IP address of the computer on which you have installed CouchDB.
You should get the following output as a result of the above command:
{couchdb:Welcome,uuid:e833c5cfb43d9601433cae620e74595,version:1.6.1,vendor:{name:The Apache Software Foundation,version:1.6.1}}
Next, lets create a simple database using the curl PUT parameter:
# curl -X PUT http://<COUCHDB_SERVER_IP>:5984/<DATABASE_NAME>
You should get the following response:
{ok:true}.
This means you have successfully created a new database on CouchDB.
While naming your database, always remember the following useful points:
- Use lowercase characters (a-z)
- You can use digits (0-9) while naming your database but the first character has to be a letter of the alphabet
- You can use any of the characters _, $, (, ), +, – and / while naming your database but the first character has to be a letter of the alphabet
You can obtain additional details about your database by simply querying against it. Once again, lets use the curl GET command to pull the relevant database information:
# curl -X GET http://<COUCHDB_SERVER_IP>:5984/<DATABASE_NAME>
This provides a detailed description of your database as shown below:
{
db_name:<DATABASE_NAME>,
doc_count:0,
doc_del_count:0,
update_seq:0,
purge_seq:0,
compact_running:false,
disk_size:79,
data_size:0,
instance_start_time:142779596351454,
disk_format_version:6,
committed_update_seq:0
}
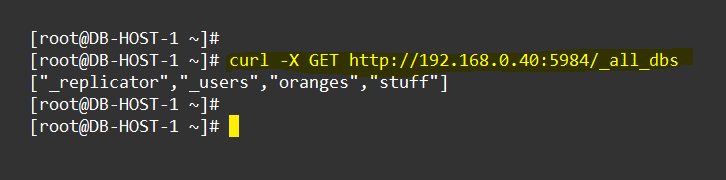
CouchDB also allows you to list all your databases in one go using some special built-in commands, such as _all_dbs.
# curl -X GET http://<COUCHDB_SERVER_IP>:5984/_all_dbs
The output in Figure 1 shows you a list of all the databases present in this particular CouchDB instance. In the output, you will also notice the presence of two CouchDB internal databases/interfaces called _users and _replicator. These interfaces are managed and run by CouchDB itself. A brief list of these interfaces is given below:
- /_users: Contains all CouchDB users
- /_active_tasks: Lists all actively running tasks in the database
- /_db_updates: Lists all current occurring database events
- /_log: Displays CouchDBs internal logs
- /_replicate: This database is primarily used during the database replication process
- /_restart: Restarts the CouchDB instance
- /_stats: Displays the database as well as CouchDB servers statistics
- /_utils: Used to provide access to the built-in CouchDB administration interface
- /_uuids: Used to request one or more uniquely generated UUIDs from CouchDB
- /_config: Displays the entire CouchDB configuration details
Now that our database is ready, let us populate it with a document. As we discussed earlier, documents are the primary unit of data in CouchDB and consist of any number of fields and attachments. Documents also include metadata thats maintained by the database system. Document fields are uniquely named and contain values of varying types (text, number, boolean, lists, etc), and there is no set limit to the text size or element count.
To add a document to a database, lets use the curl POST command but, additionally, pass a -d parameter for the data. For example:
# curl -X POST http://<COUCHDB_SERVER_IP>:5984/<DATABASE_NAME> \
-H Content-type: application/json \
-d {
fruit:apple,
car:fiat,
random stuff:Some R@nD0m DATA
}
The output will contain two fields that you should make a note of:
- id: This is the unique ID that identifies your document.
- rev: This is the revision ID. Revisions are important in CouchDB, as it will not allow a user to update a document unless the documents current revision ID is provided.
{ok:true,id:0ca55157ffdd55287d98934002b2b,rev:1-c31f8f2f54792f63d319547db7180}
You can list any documents contents by using the curl GET command along with the documents ID as shown:
# curl -X GET http://<COUCHDB_SERVER_IP>:5984/<DATABASE_NAME>/<DOCUMENT_ID>
Deleting a database is also a simple process; just provide the databases name with the curl DELETE parameter as shown below:
# curl -X DELETE http://<COUCHDB_SERVER_IP>:5984/<DATABASE_NAME>
By now you may be thinking that you need to be a command line Ninja to manage CouchDB. But thats not true because there are Web based tools, like Futon, to manage CouchDB. Futon is a Web based user interface provided by CouchDB that helps in the creation, updating and overall management of the databases. You can additionally create and work with documents, list various database configuration parameters and initiate database replication as well, using this UI.
To access Futon, simply launch a browser and type the following command:
http://<COUCHDB_SERVER_IP>:5984/_utils
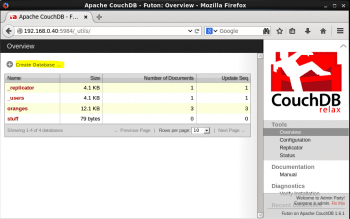
You will be presented with a dashboard that contains a Home screen or the Overview tab. This tab shows you a list of databases that you have created on the current CouchDB instance. To the right of the UI, there is a Tools section, where you can select different options that will guide you through changing the databases configuration, enable replication, etc. You can also view the current status and health of your CouchDB instance using the Tools section.
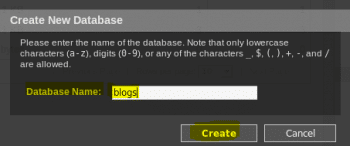
To create a new database, select the Create Database button. Provide a suitable name for your database and click Create once you are done.
Now that you have created your database, you can populate it with documents, manage the databases security and even delete it, if required.
Replication
The replication process in CouchDB is an incremental one-way process involving two or more CouchDB database instances. These instances can be on the same CouchDB server or running on a separate node altogether.
The main purpose of replication in CouchDB is that, at the end of the process, all active documents from the source database are successfully placed on the remote database as well. Alternatively, if the database is deleted from the sources end, then the same should also get deleted from the remote database as well.
In this case, we have two CouchDB instances on two different nodes (DB-HOST-1 and DB-HOST-2). Each CouchDB instance has an empty database created within it. On DB-HOST-1, we have a database called db-01 and on the second host, we have a database called db-02.
To start the replication process, we make use of the _replicate database/interface. Here, you need to provide the source and target database information as shown below:
# curl -X POST http://127.0.0.40:5984/_replicate \
-H Content-Type: application/json \
-d \
{
source:http://<DB-HOST-1_IP_ADDRESS>:5984/db-01,
target:http://<DB-HOST-2_IP_ADDRESS>:5984/db-02,
continuous:true
}
Note: You can inspect the status of the replication process by running the _active_tasks interface as shown: # curl -X GET http://127.0.0.1:5984/_active_tasks
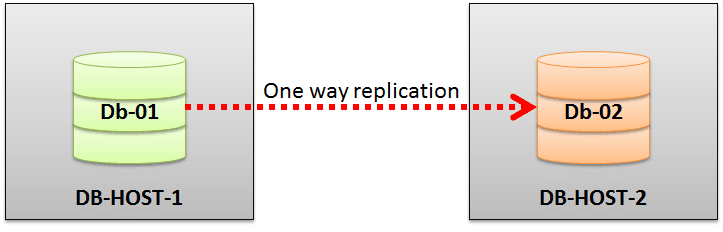
To test if the replication is a success or not, simply try to create a document in the db-01 database. You should see the document created and listed in the db-02 database as well.
Replication can also be triggered using the Futon Web interface. From the Futon dashboard, select the Replicator option from the right-hand side Tools tab as shown in Figure 5. This will display the Replicator wizard, using which you can easily set up and configure a replication process between two CouchDB instances on the same host or on different hosts.
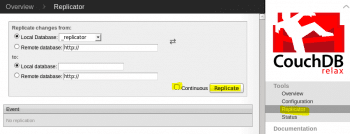
To start the replication process, select the Replicate button as shown in Figure 5. You can monitor the status of the replication process from the Status option located under the Tools bar.
So heres a quick recap. In this article, we have looked at the many features and benefits of using NoSQL databases. We also learnt how to get started with Apache CouchDB, creating and populating simple databases as well as performing basic operations such as replication. This, though, is just the tip of the iceberg when it comes to what CouchDB can do. You can design your Web or mobile apps around CouchDB, leverage JavaScript to design and build MapReduce functions, query large datasets and much more!
References
[1] http://couchdb.readthedocs.org/en/1.6.1/intro/tour.htmlf
[2] https://wiki.apache.org/couchdb/Replication
[3] http://code.tutsplus.com/articles/getting-started-with-couchdb–net-18801
[4] http://www.yoyoclouds.com/2015/04/getting-started-with-couchdb-part-1.html

















{kind=link}