































































Sentiment analysis is widely used by research scholars and others. In this approach, there are a number of tools and technologies available for fetching live data sets, tweets, emotional attributes, etc. Using these tools, real-time tweets and messages can be extracted from Twitter, Facebook, Whats App and many other social media portals. This article presents the fetching of live tweets from Twitter using Python programming.
The emotional attributes of Internet users on social media portals can be analysed, and certain conclusions arrived at and predictions made using this method. Let us suppose that we want to evaluate the overall cumulative score of a celebrity. For this, Python or PHP based programming scripts can fetch live tweets about that celebrity from Twitter. After that, using natural language processing toolkits, the fetched data in the form of tweets or messages can be analysed and the popularity of that particular person or movie or celebrity can be more accurately assessed.
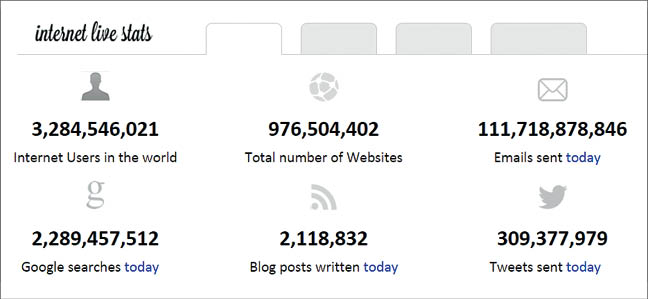
The following are the statistical reports from InternetLiveStats.com and Statista.com about the real time data on social media and related Web portals.
Around 350 million tweets flow daily from more than 500 million accounts on Twitter. Around 571 new websites are hosted every minute on the World Wide Web. There are more than 5 billion users on their mobile phones concurrently.
On WhatsApp, there are 700 million active users. There are more than 1 million new user registrations every month.Around 30 billion messages are sent and 34 billion received every day on WhatsApp. On Facebook, five new profiles are created every second. There are also around 83 billion fake profiles. Around 300 billion photos are uploaded every day by 890 billion daily active users. About 320TB of data is processed daily, with 21 minutes being spent by every user, on an average.
Now, the question is: how to do research on these datasets? Also, which technologies can be used to fetch the real-time datasets? The live streaming data can be fetched using Python, PHP, Perl, Java and many others used for network programming.
Fetching live streaming data from Twitter using Python code
Specific packages named Tweepy and Twitter with Python are required to fetch live tweets from Twitter. After these packages are installed, the Python code will be able to fetch live data from Twitter.
These can be installed using the Pip command as follows:
$ python -m pip install tweepy $ python -m pip install Twitter
The code to fetch live tweets from Twitter is:
from tweepy import Stream from tweepy import OAuthHandler from tweepy.streaming import StreamListener my_app_consumerkey = XXXXXXXXXXXXXXXXXXXXXXXXXX my_app_consumersecret = XXXXXXXXXXXXXXXXXXXXXXXXXX my_app_accesstoken = XXXXXXXXXXXXXXXXXXXXXXXXXX my_app_accesssecret = XXXXXXXXXXXXXXXXXXXXXXXXXX class TweetListener(StreamListener): def on_data(self, mydata): print mydata return True def on_error(self, status): print status auth = OAuthHandler(my_app_consumerkey, my_app_consumersecret) auth.set_my_app_accesstoken(my_app_accesstoken, my_app_accesssecret) stream = Stream(auth, TweetListener()) stream.filter(track=[Name of the Celebrity or Movie or Person])
After execution of this script, the output dataset is fetched in JSON file format. The JSON file can be parsed using the OpenRefine tool in the XML, CSV or any other readable format by the data mining and machine learning tools.
OpenRefine is a powerful and effective tool used for processing the Big Data and JSON file formats.
In a similar way, the timeline of any person or Twitter ID can be fetched using the following code:
import tweepy import time my_app_consumerkey = XXXXXXXXXXXXX my_app_consumersecret = XXXXXXXXXXXXX my_app_accesstoken = XXXXXXXXXXXXX my_app_accesssecret = XXXXXXXXXXXXX auth = tweepy.auth.OAuthHandler(my_app_consumerkey, my_app_consumersecret) auth.set_my_app_accesstoken(my_app_accesstoken, my_app_accesssecret) api = tweepy.API(auth) list= open(Twitter.txt,w) if(api.verify_credentials): print Connected to Twitter Server currentuser = tweepy.Cursor(api.followers, screen_name=gauravkumarin).item() while True: try: u = next(currentuser) list.write(u.screen_name + \n) except: time.sleep(15*60) u = next(currentuser) list.write(u.screen_name + \n) list.close()
The following script of Python can be used to parse the JSON to CSV format:
JSON - CSV Parser
import fileinput
import json
import csv
import sys
l = []
for currentline in fileinput.input():
l.append(currentline)
currentjson = json.loads(.join(l))
keys = {}
for i in currentjson:
for k in i.keys():
keys[k] = 1
mycsv = csv.DictWriter(sys.stdout, fieldnames=keys.keys(),
quoting=csv.QUOTE_MINIMAL)
mycsv.writeheader()
for row in currentjson:
mycsv.writerow(row)
Fetching data from Twitter using PHP code
For fetching live tweets using PHP code, the API TwitterAPIExchange is required. After including this API in this PHP code, the script will directly interact with the Twitter servers and live streaming data.
<?php
error_reporting(0);
define(CURRENTDBHOST,localhost);
define(CURRENTDBUSERNAME,root);
define(CURRENTCURRENTDBPASSWORD,);
define( CURRENTDBPASSWORD ,Twitter);
define(CURRENTTWEETTABLE,Twittertable);
require_once(TwitterAPIExchange.php);
$settings = array(
oauth_my_app_accesstoken => XXXXXXXXXXXXXXXXXX,
oauth_my_app_accesstoken_secret => XXXXXXXXXXXXXXXXXX ,
my_app_consumerkey => XXXXXXXXXXXXXXXXXX ,
my_app_consumersecret => XXXXXXXXXXXXXXXXXX
);
$url = https://api.Twitter.com/1.1/statuses/user_timeline.json;
$myrequestMethod = GET;
$getfield = ?screen_name=gauravkumarin&count=20;
$Twitter = new TwitterAPIExchange($settings);
$string = json_decode($Twitter->setGetfield($getfield)
->buildOauth($url, $requestMethod)
->performRequest(),$assoc = TRUE);
if($string[errors][0][message] != ) {echo <h3>Sorry, there was a problem.</h3><p>Twitter returned the following error message:</p><p> <em>.$string[errors][0][message].</em></p>;exit();}
foreach($string as $items)
{
echo Tweeted by: . $items[currentuser][name].<br />;
echo Screen name: . $items[currentuser][screen_name].<br />;
echo Tweet: . $items[text].<br />;
echo Time and Date of Tweet: .$items[timestamp].<br />;
echo Tweet ID: .$items[id_str].<br />;
echo Followers: . $items[currentuser][followers].<br /><hr />;
echo insertTweetsDB($items[currentuser][name],$items[currentuser][screen_name],$items[text],$items[timestamp],$items[id_str],$items[currentuser][followers]);
}
function insertTweetsDB($name,$screen_name,$text,$timestamp,$id_str,$followers){
$mysqli = new mysqli(CURRENTDBHOST, CURRENTDBUSERNAME, CURRENTCURRENTDBPASSWORD, MYDBNAME);
if ($mysqli->connect_errno) {
return Failed to connect to Database: ( . $mysqli->connect_errno . ) . $mysqli->connect_error;
}
$QueryStmt=INSERT INTO .MYDBNAME...CURRENTTWEETTABLE. (name, screen_name, text, timestamp, id_str, followers) VALUES (?,?,?,?,?,?);;
if ($insert_stmt = $mysqli->prepare($QueryStmt)){
$insert_stmt->bind_param(ssssid, $name,$screen_name,$text,$timestamp,$id_str,$followers);
if (!$insert_stmt->execute()) {
$insert_stmt->close();
return Tweet Creation cannot be done at this moment.;
}elseif($insert_stmt->affected_rows>0){
$insert_stmt->close();
return Tweet Added.;
}else{
$insert_stmt->close();
return No Tweet were Added.;
}
}else{
return Prepare failed: ( . $mysqli->errno . ) . $mysqli->error;
}
}
Using these technologies, the parsing, processing and predictions on real-time tweets and their association with a particular event can be mapped. News channels adopt these technologies for exit polls, which help to predict the probability of a political party or candidate winning. In a similar manner, the success of a movie can be predicted after careful analysis of the live streaming data.
Research scholars can work on such real life topics related to Big Data analytics, so that effective and presentable research work can be accomplished.

















{kind=link}