






























































Apache Cassandra is an open source, distributed, massively scalable NoSQL database. It is designed to handle large volumes of structured, semi-structured and unstructured data across multiple data centres, and it supports the cloud. Cassandra offers capabilities like continuous availability, linear scalability and operational simplicity across many commodity servers with no single point of failure. Its powerful, dynamic data model is designed for maximum flexibility and fast response times.
History
Apache Cassandra was originally developed by Avinash Lakshman (one of the authors of Amazons Dynamo) and Prashant Malik at Facebook for inbox search. Cassandra was published as an open source project on Google Code in July 2008. It was accepted into the Apache Incubator in March 2009 and, since February 2010, has been an Apache top-level project.
Features
Massively scalable architecture: Cassandra has a masterless design where all nodes are the same. This provides operational simplicity and easy scale-out. There is no single point of failure.
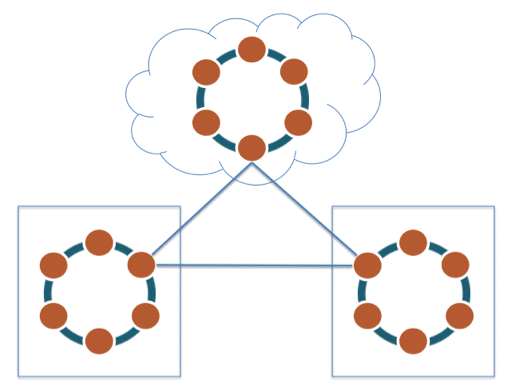
Multiple data centre replication: Cassandra gives great support for replication across multiple data centres (in multiple geographies) and multi-cloud availability zones for writes/reads.
Linear scale performance: Users can increase performance by adding new nodes without any downtime or interruption to applications. For example, if one node can handle 50,000 transactions per second, two nodes will support 100,000 transactions/second and four nodes will tackle 200,000 transactions/second, and so on.
Tunable data consistency: Cassandra supports configured consistency levels to manage availability versus data accuracy. We can configure consistency on a Cassandra cluster, data centre, or per individual read or write operation.
Tunable consistency is one of the strongest features of Cassandra. There are two types of consistency levels — strong or eventual. To ensure that data is written and read correctly, Cassandra extends the concept of eventual consistency by offering tunable consistency. Tunable data consistency allows individual read or write operations to be as strongly consistent as required by the client application. The consistency level of each read or write operation can be set, so that the data returned is more or less consistent, based on need.
Data compression: Data is compressed up to 80 per cent without any performance overhead.
Cassandra Query Language: This is an SQL-like language that allows the running of SQL-like queries in traditional databases.
When should Cassandra be used?
Apache Cassandra can be used for various applications. Here are some use cases where it would be the best choice over other NoSQL databases.
In activity-tracking and monitoring applications: Numerous entertainment and media organisations use Cassandra to monitor user activity based on movies, music, albums, artists or other parameters.
In heavy write systems or in time-series-based applications: Cassandra is perfect for very heavy write systems for example, in Web analytics where the data is logged for each request based on hits, by type of browser, traffic sources, location, behaviour, technology, devices, etc.
In social media analytics: Cassandra is used by many social media providers to analyse the data and provide suggestions to their customers.
In product catalogues and retail applications: A very popular use case of Cassandra is to display fast product catalogue inputs and lookups, and in retail applications.
Messaging: Cassandra serves as the database backbone for numerous mobile phone and message providers applications.
Data model
The data model of Cassandra is different from that of a relational DBMS. Cassandra does not support joins or subqueries for which there is support in an RDBMS. Instead, Cassandra emphasises denormalisation through features like collections.
Cassandra is basically a key-value and a column-oriented (or tabular) database. Rows are organised into tables; the first component of a tables primary key is the partition key, and within a partition, rows are clustered by the remaining columns of the key. Other columns can be indexed separately from the primary key.
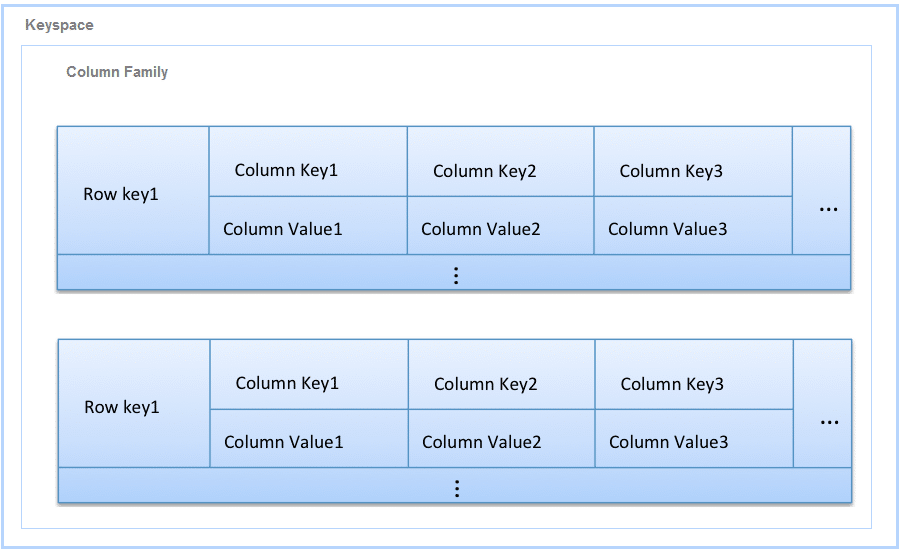
The Cassandra data model consists of keyspace, column families, columns and rows.
Keyspace: The keyspace is the outermost container for your application data. It is similar to the schema in a relational database. The keyspace can include operational elements, such as the replication factor and data centre awareness. It is a group of many column families.
Column family: A column family is a container for an ordered collection of rows, each of which is itself an ordered collection of columns. A column family is similar to a table in RDBMS and is a logical separation of similar data.
Column: Its a basic data structure of Cassandra with three values – name, value and timestamp.
Super column: A super column stores a map of sub-columns.
Row: This is a collection of columns labelled with a name.
Apache Cassandra Query Language
The Cassandra Query Language (CQL) allows you to query Cassandra using queries similar to SQL. It was first introduced in Cassandra 0.8 and is the most preferred way to communicate with the Cassandra database. You can use CQL through the CQL shell, cqlsh. You can create keyspaces, tables, insert tables and use many more features which are available in CQL. CQL3 also supports JSON, user defined functions (UDFs), user defined aggregates (UDAs) and role based access control (RBAC).
So if your application has a large amount of data, and if you are planning to scale it, then Cassandra will definitely help you. The main difference between a relational database and Cassandra is that the former breaks data into many tables, but Cassandra tends to keep as much of it as possible intact within the same row to avoid having to join that data for retrieval.

















{kind=link}