


Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics that explores the relationship between computers and natural languages. The Apache OpenNLP library is a machine learning toolkit, which processes natural language text written in Java. It supports most NLP tasks.
OpenNLP is an open source library for processing natural language texts using inbuilt machine learning tools. It is a toolkit from the Apache Software Foundation to support the most common NLP tasks, such as tokenisation, sentence detection and name finding. This library can be downloaded from the Apache mirror site http://mirror.fibergrid.in/apache/opennlp/opennlp-1.5.3. This demonstration uses OpenNLP version 1.5.3. The binary tar file apache-opennlp-1.5.3-bin.tar.gz is extracted and located under the /usr/local/apache-opennlp-1.5.3 directory of Ubuntu Linux.
It is necessary to download the pre-trained models for the OpenNLP 1.5 series from the site http://opennlp.sourceforge.net/models-1.5/. The following pre-trained models are used for tokenising, sentence detection and name finding in English language texts.
Tokenizer: Trained on OpenNLP training data – en-token.bin
Sentence Detector: Trained on OpenNLP training data – en-sent.bin
Name Finder: Location name finder model – en-ner-location.bin
Name Finder: Person name finder model – en-ner-person.bin
Name Finder: Organisation name finder model– en-ner-organization.bin
This is going to be demonstrated on an Ubuntu 12.04 LTS Linux system in this article.
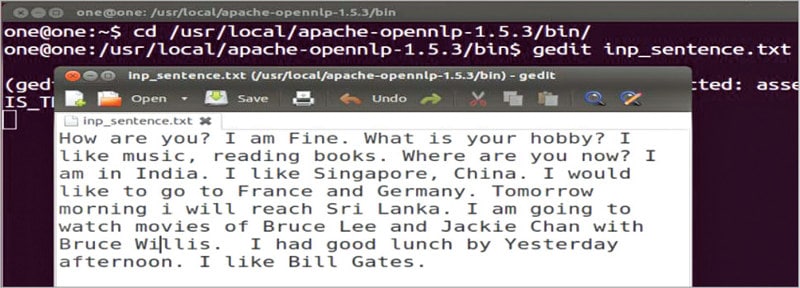
Figure 1 shows the English language text file inp_sentence.txt used for testing the OpenNLP tools for the entire sequence of activity.
The first step
Test the command opennlp in Linux under the location /usr/local/apache-opennlp-1.5.3/bin.
Tokenisation
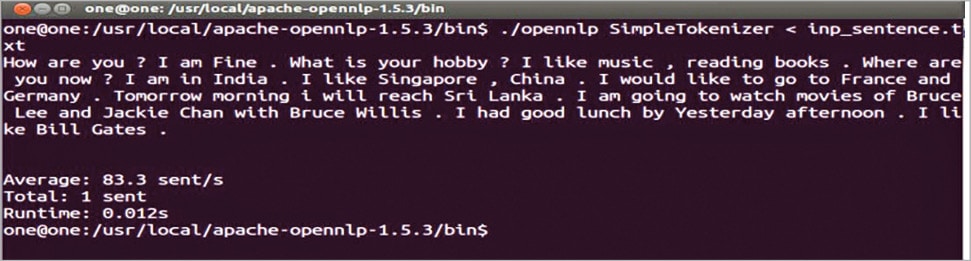
Tokeniser segments input character sequences into tokens. Tokens are usually words, punctuation, numbers, etc.
The result of the SimpleTokenizer tool with input text file inp_sentence.txt is shown in Figure 2.
Sentence detection
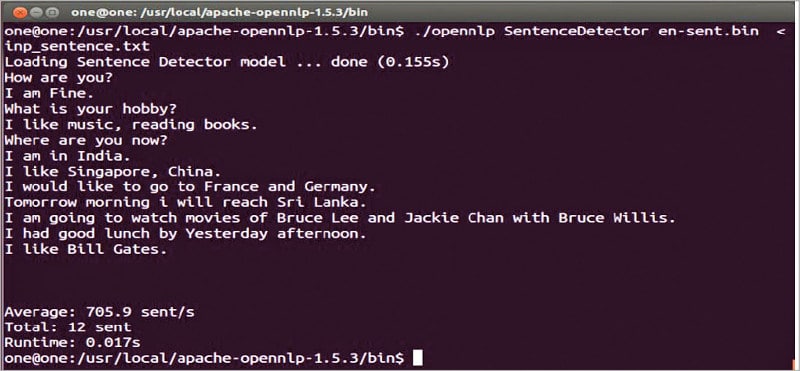
The sentence detector detects each sentence based on the punctuation symbols like the full stop (.) and question mark (?).
The result of the SentenceDetector tool using the pre-trained model en-sent.bin is shown in Figure 3.
Name finder (finding the location of a name)
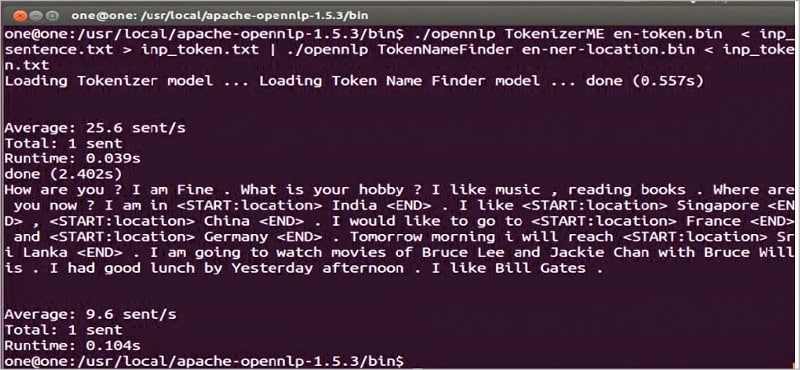
The name finder can detect named entities and numbers in text – like the names of famous persons, locations and organisations. We need to have pre-trained models to detect entities. The example in Figure 4 shows the process of finding the location in a file inp_sentence.txt by using the model en-ner-location.bin. The locations are marked as <START:location> India <END>. The command given in Figure 4 is actually the pipelining of both tokenising and token name finding using the tools TokenizerME and TokenNameFinder, respectively.
Name finder (finding a person)
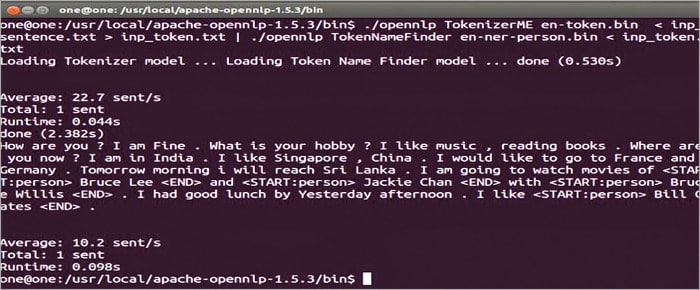
The example given in Figure 5 shows the process of finding the person in a file inp_sentence.txt by using the model en-ner-person.bin. The persons are marked as <START:person> Bill Gates <END>. The command in Figure 5 actually pipelines both tokenising and token name finding, using the tools TokenizerME and TokenNameFinder, respectively.

Name finder (finding an organisation)
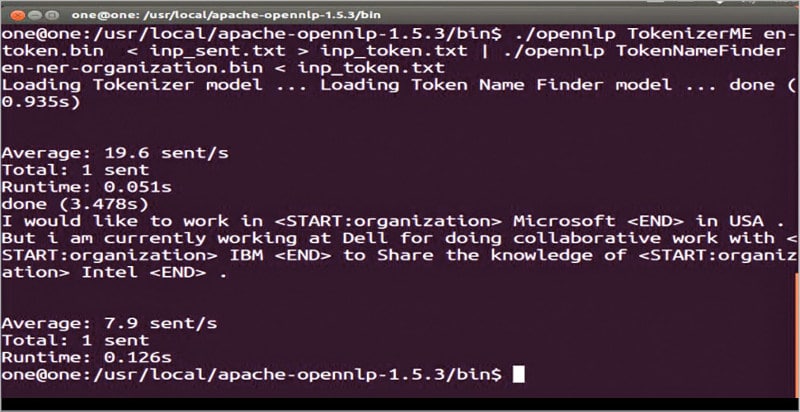
Figures 6 and 7 show the process of finding an organisation in a file inp_sentence.txt by using the model en-ner-organization.bin. The results are marked as <START:organization> Intel <END>. The command in Figure 6 is actually pipelining both tokenising and token name finding using the tools TokenizerME and TokenNameFinder, respectively.



{kind=link}