































































This article gives readers an overview of Google machine learning APIs. It contains code samples to get started with APIs, bringing the power of machine learning to everyday developers.
For the past two decades, Google has been at the forefront of collecting and mining data. It has built multiple machine learning models through which it now provides some of the most powerful machine learning APIs. These machine learning models are the magic behind some of the applications like Google Photos, Inbox Reply (Gmail), Google Translate and more.
In the last year, Google has opened up its machine learning models by making its APIs accessible to the public. The Google Cloud Machine Learning Platform provides easy-to-use REST APIs that have powerful capabilities like computer vision, NLP, translation and more.
Google Cloud Machine Learning Platform
One of the main issues facing developers is figuring out how much of theoretical knowledge they need before using machine learning algorithms in their applications. The team at Google has understood this and identified a spectrum across which different products from Google can be used from the Machine Learning Platform.
At one end of the spectrum is TensorFlow, which is an open source library for machine intelligence. TensorFlow does require that you are up to speed on various machine learning concepts and can use the API to build machine models, using them effectively in your applications. This might not be possible for all developers, especially those who are looking for REST APIs to use in their applications. To cater to this need, Google has identified multiple capabilities in its Machine Learning Platform and has exposed those capabilities in the form of easy-to-call REST APIs. There is also a free quota per month for these APIs.
Over the last few months, Google has released multiple REST APIs in the Machine Learning Platform. The most important ones are listed below.
Google Cloud Vision API: The Cloud Vision API provides a REST API to understand and extract information from an image. It uses powerful machine learning models to classify images into thousands of categories, detect faces, identify adult content, emotions, OCR support and more. If you are looking to classify and search through images for your application, this is a good library to consider.
Google Natural Language API: The Natural Language API is used to identify parts of speech and to detect multiple types of entities like persons, monuments, etc. It can also perform sentiment analysis. It currently supports three languages: English, Spanish and Japanese.
Google Speech API: The Speech API is used to translate audio files into text. It is able to identify over 80 languages and their variants, and can work with most audio files.
There are multiple other APIs in this family like the Translate API, but we will limit our sample code to the above three APIs.
Getting started
To get started with using the machine learning APIs listed above, you need to sign up for the Google Cloud Platform and enable your billing. The platform provides a trial period of two months for US$300, which is sufficient to try out the APIs.
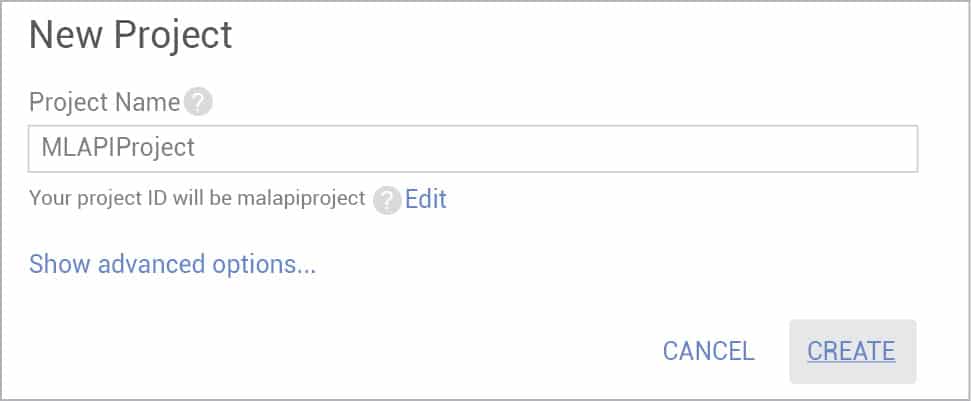
Once you have signed up for the platform, you need to create a project. Go to the Cloud Console and click on New Project. In the New Project dialogue box, provide a name for your project, as shown in Figure 1, before clicking on Create.
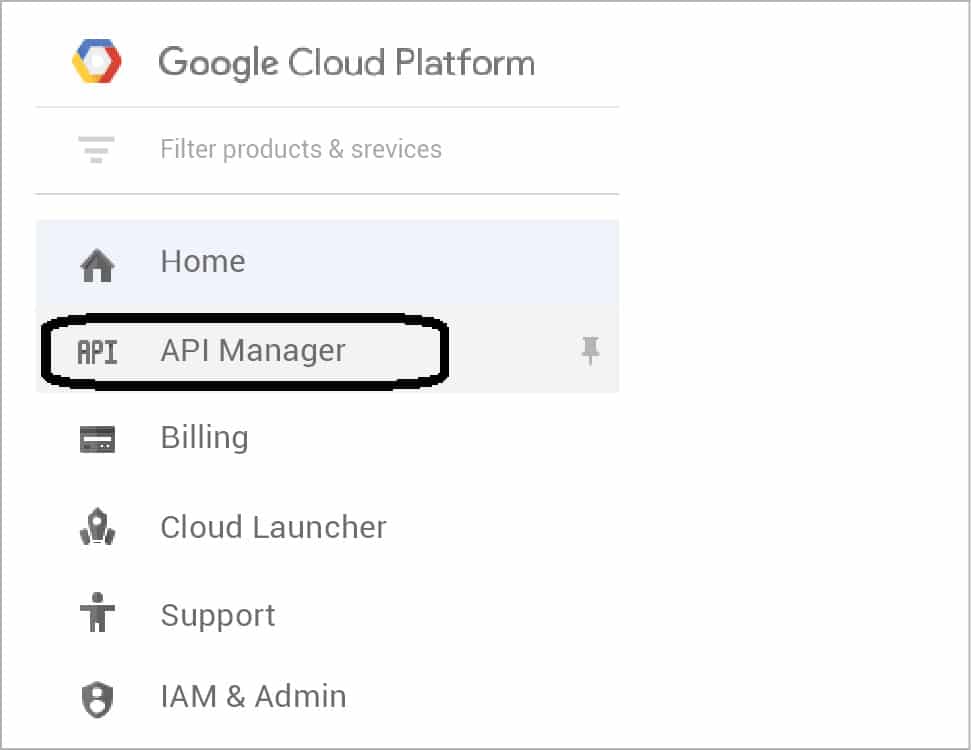
Once the project is created, you need to enable the above three APIs for your project. To do that, go to the Main Menu on the top left in the Cloud Console and click on API Manager, as shown in Figure 2.
In the search bar, enter ‘Cloud Vision’ and it will display the Google Cloud Vision API in the list. Select it and then click on Enable. This will enable the API. Perform the same operation for the other two APIs also, i.e., the natural language processing (NLP) API and the Speech API. Ensure that you have enabled the above three APIs for your project before moving ahead.
Since we are going to be writing an external program that invokes the REST APIs, our calling client application needs to identify itself to the Google Cloud platform. We do that through the concept of a service account, which will be used by our client application to invoke the APIs.
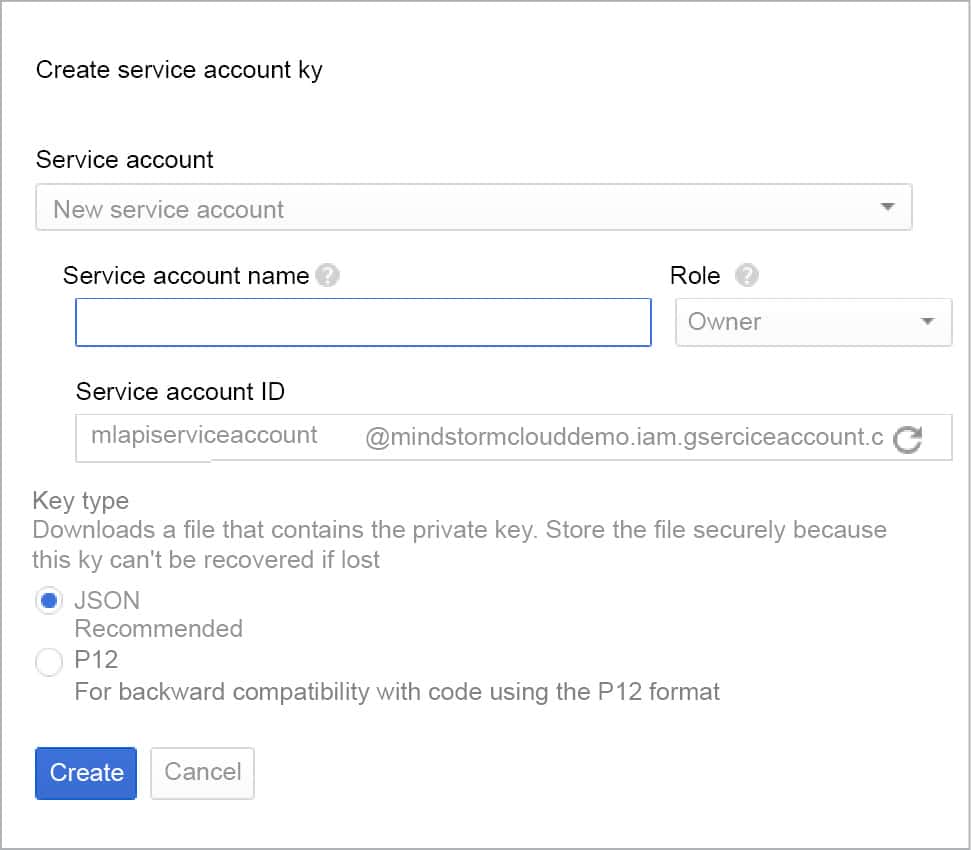
To do that, we need to download the service account keys for our project. From the API Manager menu on the left, click on Credentials and then on Create Credentials. Select Service Account Key from the options. This will bring up a dialogue box as shown in Figure 3. Select New Service Account, give a name to the service account and in Role, select Project Owner.
Click on Create. This will download a JSON file for your service account. Ensure that you save this file in a safe place, since we will use it when we run our client application. For the purpose of this article, the service account JSON file downloaded will be referred to as the mlapi-serviceaccount.json file.
Vision API
Let’s first test the vision API. As mentioned earlier, this has multiple features and, in this specific example, we are going to test its label detection feature. This feature allows you to provide an image, and it will identify various labels for this image, which can help in its classification.
We are going to provide it an image of a cricket match and see what it can figure out about it. The image that we are going to test it against is shown in Figure 4.
Before you run this code and the other examples, you will need to set an environment variable named GOOGLE_APPLICATION_CREDENTIALS and it will need to point to the service account JSON file that we downloaded earlier. For example:
export GOOGLE_APPLICATION_CREDENTIALS=mlapi-serviceaccount.json
The sample code in Python is shown below. This is a modification of the code that is available at its API page.
from googleapiclient import discovery
import argparse
import base64
import json
from oauth2client.client import GoogleCredentials
DISCOVERY_URL = (‘https://{api}.googleapis.com/’
‘$discovery/rest?version={apiVersion}’)
def main(photo_file):
credentials = GoogleCredentials.get_application_default()
service = discovery.build(‘vision’, ‘v1’,credentials=credentials)
with open(photo_file, ‘rb’) as image:
image_content = base64.b64encode(image.read())
service_request = service.images().annotate(body={
‘requests’: [{
‘image’: {
‘content’: image_content.decode(‘UTF-8’)
},
‘features’: [{
‘type’: ‘LABEL_DETECTION’,
‘maxResults’: 5
}]
}]
})
response = service_request.execute()
print(json.dumps(response[‘responses’],indent=4))
if __name__ == ‘__main__’:
parser = argparse.ArgumentParser()
parser.add_argument(‘image_file’, help=’The image you\’d like to label.’)
args = parser.parse_args()
main(args.image_file)
Let us understand the code first. In the main block, we read the file name that we provided. The first step in the main function is to establish the credentials; we use the standard application credentials, which were set via the environment variable. We then read the file bytes and invoke the REST API endpoint for the cloud vision API. Notice that in the REST API call, we provide not just the bytes for the image but also the feature that we are interested in, i.e., LABEL_DETECTION, and command it to return us a maximum of five such label results. We finally invoke the API and print out the results.
The output can be downloaded from https://www.opensourceforu.com/article_source_code/dec16/gml.zip. Notice that each of the labels that it detected has a confidence score out of 10. It is generally considered a positive response if it is about 70-80 per cent, but it is entirely up to your application to accept these results. Note that it has also detected erroneously that there is a baseball player —it is important to keep these points in mind.
Natural Language API
The Natural Language API helps us to identify parts of speech in a text, entities (persons, monuments, organisations, etc) and also do sentiment analysis. In the specific example that we will execute here, we are going to test how the API extracts entities. This will help us to identify the different entities that were present in the piece of text that we provided to it.
The text that we will provide to the REST API is as follows:
The search for a new chairman of Tata Sons following the ouster of Cyrus Mistry has thrown up quite a few names. The high-profile names include Indra Nooyi, the head of PepsiCo Inc, Arun Sarin, the former head of Vodafone Group, and Noel Tata, chairman of the Tata retail unit, Trent.
The code is shown below and it follows a pattern similar to the vision API that we saw earlier.
from googleapiclient import discovery
import httplib2
import json
from oauth2client.client import GoogleCredentials
DISCOVERY_URL = ('https://{api}.googleapis.com/'
'$discovery/rest?version={apiVersion}')
def main():
http = httplib2.Http()
credentials = GoogleCredentials.get_application_default().create_scoped(
['https://www.googleapis.com/auth/cloud-platform'])
http=httplib2.Http()
credentials.authorize(http)
service = discovery.build('language', 'v1beta1',
http=http, discoveryServiceUrl=DISCOVERY_URL)
service_request = service.documents().analyzeEntities(
body={
'document': {
'type': 'PLAIN_TEXT',
'content': "The search for a new chairman of Tata Sons following the ouster of Cyrus Mistry has thrown up quite a few names. The high-profile names include Indra Nooyi, the head of PepsiCo Inc, Arun Sarin, the former head of Vodafone Group, and Noel Tata, chairman of the Tata retail unit Trent."
}
})
response = service_request.execute()
entities = response['entities']
print(json.dumps(entities,indent=4))
return 0
if __name__ == '__main__':
main()
Once the credentials are established, we are simply going to invoke the REST API and, specifically, the analyzeEntities method. The output results can be obtained from https://www.opensourceforu.com/article_source_code/dec16/gml.zip.
It is interesting to see that the Natural Language API has been able to correctly identify the entities (organisations and individuals) and, in some cases, also provided information on their Wikipedia entries.

Speech API
The Speech API is used to convert a RAW audio file to its equivalent text format. The API is powerful enough to work with disturbances in the audio and has multiple optimisations inbuilt to detect the text.
The code shown below is taken from the official documentation, and the parameter that we pass to it at runtime is the audio file in RAW format. The code simply reads the audio file bytes, provides information in the request about the kind of audio and then, in a synchronous fashion, gets back the results of the audio converted to text.
import argparse
import base64
import json
from googleapiclient import discovery
import httplib2
from oauth2client.client import GoogleCredentials
# [START authenticating]
DISCOVERY_URL = (‘https://{api}.googleapis.com/$discovery/rest?’
‘version={apiVersion}’)
def get_speech_service():
credentials = GoogleCredentials.get_application_default().create_scoped(
[‘https://www.googleapis.com/auth/cloud-platform’])
http = httplib2.Http()
credentials.authorize(http)
return discovery.build(
‘speech’, ‘v1beta1’, http=http, discoveryServiceUrl=DISCOVERY_URL)
def main(speech_file):
with open(speech_file, ‘rb’) as speech:
speech_content = base64.b64encode(speech.read())
service = get_speech_service()
service_request = service.speech().syncrecognize(
body={
‘config’: {
‘encoding’: ‘LINEAR16’,
‘sampleRate’: 16000,
‘languageCode’: ‘en-US’,
},
‘audio’: {
‘content’: speech_content.decode(‘UTF-8’)
}
})
response = service_request.execute()
print(json.dumps(response))
if __name__ == ‘__main__’:
parser = argparse.ArgumentParser()
parser.add_argument(
‘speech_file’, help=’Full path of audio file to be recognized’)
args = parser.parse_args()
main(args.speech_file)
The output is shown below, and is the actual audio content that was present in the file.
{“results”: [{“alternatives”: [{“confidence”: 0.98267895, “transcript”: “how old is the Brooklyn Bridge”}]}]}
Google Machine Learning APIs provide a wide range of APIs that developers can use today to incorporate powerful machine learning algorithms in the domains of computer vision, language analysis, sentiment analysis, audio conversion and translation. The key factors that make this a compelling list of APIs is Google’s track record in machine learning—the complex machine learning models that it has built over the last decade—and the ease and accuracy of the APIs.
















