

MongoDB becomes much more efficient when combined with GridFS. The latter divides a document into parts or chunks that are then stored as separate documents. In a nutshell, GridFS is a kind of file system used to store files.
The rapidly increasing volume and variety of unstructured data generates enormous datasets which are difficult to analyse and extract further knowledge from. Issues related to the storage, processing and knowledge discovery from huge amounts of unstructured data are addressed by Big Data analytics. There are various applications for which the volume, velocity and variety of data increases very frequently, and a significant amount of research work is going on to understand how Big Data analytics could help in processing and understanding such data.
The following list gives a rough idea of why Big Data analytics has gained so much importance today:
- Since the inception of The Indian Railway Catering and Tourism Corporation or IRCTC in 2002, online ticket bookings have increased from 29 tickets to 1.3 million tickets per day.
- As per recent research at Harvard, the information stored in 1 gram of DNA is equivalent to 700 terabytes of data in digital format.
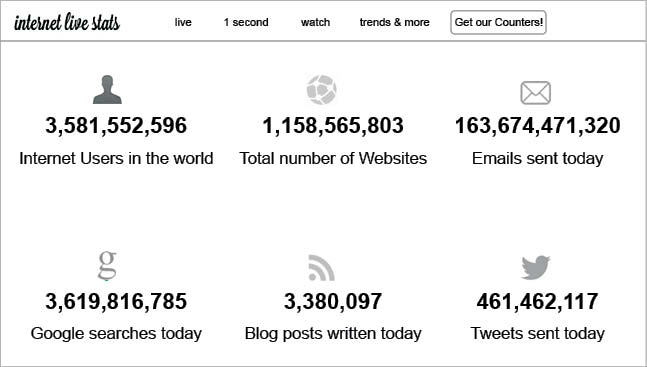
- According to InternetLiveStats.com, around 10,000 tweets are processed per second on Twitter; the Internet traffic per second totals more than 42TB; and on YouTube, more than 68,000 videos are viewed every second.
- As per a report on popular statistics portal Statista.com, there were more than 1000 million users per day on Facebook, as of December 2016.
MongoDB: A prominent NoSQL database for Big Data processing
MongoDB is one of the widely used NoSQL databases under free and open source distribution. It is a document-oriented database written in C++, and a leader in the database segment for large scale as well as performance-aware Big Data based applications. The implementation and storage of Aadhaar cards in India is being effectively done with the integration of MongoDB.
MongoDB provides a number of modules and specifications to support scalable and high performance Big Data based applications. These features and modules include GridFS, Sharding, Capped Collections, Map Reduce and many others. MongoDB can insert more than 200 million rows of data in a few seconds.
GridFS—for the storage and retrieval of large objects
GridFS is one of the powerful specifications of MongoDB that helps to store and retrieve large scale files. These files can be structured or unstructured and they include documents, audio files, images, recorded video clips, binary files, etc. GridFS is similar to a file system for the storage of files. MongoDB collections are used for storage of data and files using GridFS, which has powerful features to store the files of any format, including files that are even more than 16MB in size. In classical implementations, there is the file storage limit of 16MB but MongoDB-GridFS can store and retrieve files beyond this limit too.
Using GridFS, the files are divided into a number of chunks. Every single chunk of the dataset is stored in arbitrary but logically connected documents, each with the maximum size of 255KB.
GridFS works on two collections called fs.files and fs.chunks, for the storage of metadata and a chunk of a file. Each chunk is uniquely associated with an ID. The collection fs.files acts as the parent document corresponding to the chunk. The field files_id in the collection fs.chunks is used to link the actual content with its parent.
The format of fs.files collection is:
{
“filename”: “********”, // Filename
“chunkSize”: “********, // Size of Chunk
“uploadDate”: ISODate(“”********”), // Timestamp
“md5”: “”********”, // MD5 (Message Digest) Hash of File
“length”: “********, // Size of document in bytes
“contentType”: “********, // File Type in MIME
“metadata”: “******** // Additional Information
}
The format of fs.chunks collection is:
{
“ _id”: ObjectId(“”********”,”), // Unique ID of the chunk
“files_id”: ObjectId(“”***”,”), // Parent ID of the document
“n”: “********”, // Sequence Number of chunk
“data”: “”********”,” // Data in chunk
}
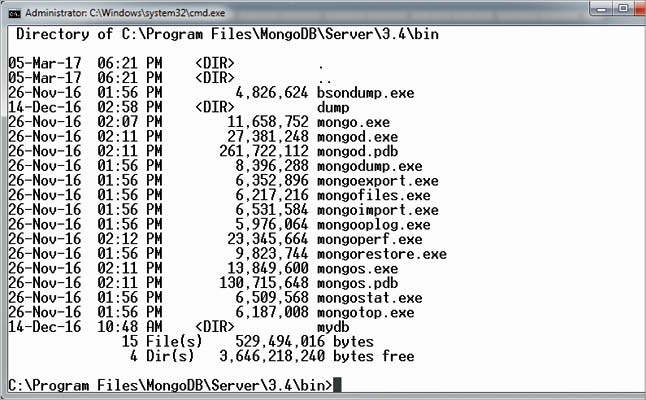
Adding and retrieving large binary files using GridFS
In the following example, the storage of a video file will be implemented using GridFS. The put command is used for this. The utility mongofiles.exe in the bin folder is required to be executed.
First, open the command prompt. Next, change the directory to the bin folder of MongoDB. Now start the MongoDB server by executing mongod.exe.
Next, execute the following command:
<em>C:\MongoDBDirectory\bin\mongofiles.exe -d gridfs put MyVideo.avi</em>
In the instruction above, mongofiles.exe is the utility for executing different commands.
The keyword ‘gridfs’ represents the name of the database that is to be used for the storage and retrieval of files. In case the database is not already created, MongoDB will create a new database with the same name dynamically. MyVideo.avi is the video file to be uploaded using GridFS.
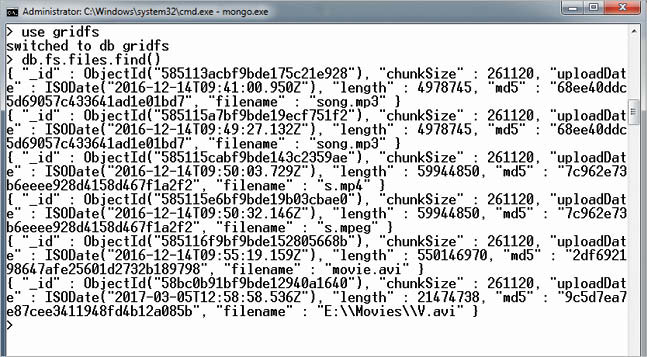
To search and view the document in the database, execute the following command on a MongoDB prompt:
MongoDB Prompt> db.fs.files.find()
To display all the chunks created, the following instruction is executed:
MongoDB Prompt> db.fs.chunks.find({files_id:ObjectId(‘ 58bc0b91bf9bde12940a1640’)})
Interfacing MongoDB-GridFS with PHP
The integration of PHP with MongoDB can be done using the MongoDB driver available at https://s3.amazonaws.com/drivers.mongodb.org/php/index.html.
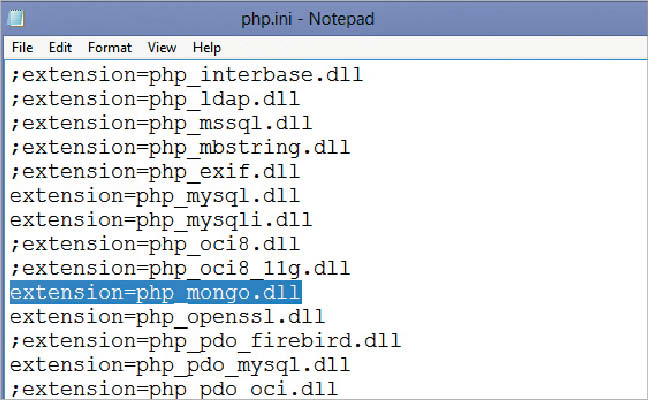
After downloading php_mongo.dll, the following line is inserted in the php.ini file:
extension = php_mongo.dll
Once the PHP-MongoDB driver is ready, GridFS can be used.
Use the following script to upload and store a large file using PHP-MongoDB-GridFS:
<?php $BigDataConnection = new Mongo(“127.0.0.1:27017”); $db = $BigDataConnection->BigDatabase; $db->authenticate(“database-username”,”database-password”); $biggrid = $db->getGridFS(); $name = $_FILES[‘BigFile’][‘name’]; $type = $_FILES[‘BigFile’][‘type’]; $id = $biggrid->storeUpload(‘BigFile’,$name); $files = $db->fs->files; $files->update(array(“filename” => $name), array(‘$set’ => array(“contentType” => $type, “aliases” => null, “metadata” => null))); $BigDataConnection->close(); exit(0); ?>
To display all files using PHP-MongoDB-GridFS, use the following script:
<?php
$BigDataConnection = new Mongo(“127.0.0.1:27017”);
$db = $BigDataConnection->BigDatabase;
$db->authenticate(“database-username”,”database-password”);
$biggrid = $db->getGridFS();
$mycursor = $biggrid->find();
foreach ($mycursor as $myobj)
{
echo ‘Filename: ‘.$myobj->getFilename().’ Size: ‘.$myobj->getSize().’<br/>’;
}
$BigDataConnection->close();
exit(0);
?>
To delete files using PHP-MongoDB-GridFS, use the script given below:
<?php $BigDataConnection = new Mongo(“127.0.0.1:27017”); $mydb = $BigDataConnection->BigDatabase; $mydb->authenticate(“database-username”,”database-password”); $biggrid = $db->getGridFS(); $myfilename = $_REQUEST[“myfile”]; $myfile = $biggrid->findOne($myfilename); $myid = $file->file[‘_id’]; $biggrid->delete($myid); $BigDataConnection->close(); exit(0); ?>
Interfacing MongoDB-GridFS with Python
To integrate Python with MongoDB-GridFS, attach the pymongo library with the existing Python set-up. After this step, GridFS can be used.
On the Python prompt, the following instructions can be executed for Python-MongoDB-GridFS interfacing:
>>> from pymongo import MongoClient >>> import gridfs
For selecting database and file system, execute the following instructions:
>>> mydb = MongoClient().MyGridFS >>> filesystem = gridfs.GridFS(mydb)
To insert a new file, put() is used:
>>> myfile = filesystem.put(“My New File”)
To read the file contents, get() is used:
>>> filesystem.get(myfile).read()
These executions can be used for assorted applications involving Big Data processing. MongoDB-GridFS interfacing can also be done with other programming languages with higher levels of integrity and performance, including Java, C++, JavaScript, Ruby, Scala, Haskell and many others.



{kind=link}